

重磅消息传来,通过测试了,74年来最高,54%的参与者误认为它是真人
重磅消息传来,通过测试了,74年来最高,54%的参与者误认为它是真人GPT-4通过图灵测试,54%人误认为真人。
来自主题: AI资讯
10763 点击 2024-06-21 11:42
GPT-4通过图灵测试,54%人误认为真人。

今天, OpenAI劲敌Anthropic忽然丢炸弹,发布下一代旗舰大模型Claude 3.5 Sonnet。
测试Gemini1.5 Pro、GPT-4o等多模态大模型的新基准来了,针对视频理解能力的那种。

苹果OpenAI官宣合作,GPT-4o加持Siri,让AI个性化生成赛道热度飙升。

GTP-4o挑战悬赏八百万的超难数据集,实现SOTA!
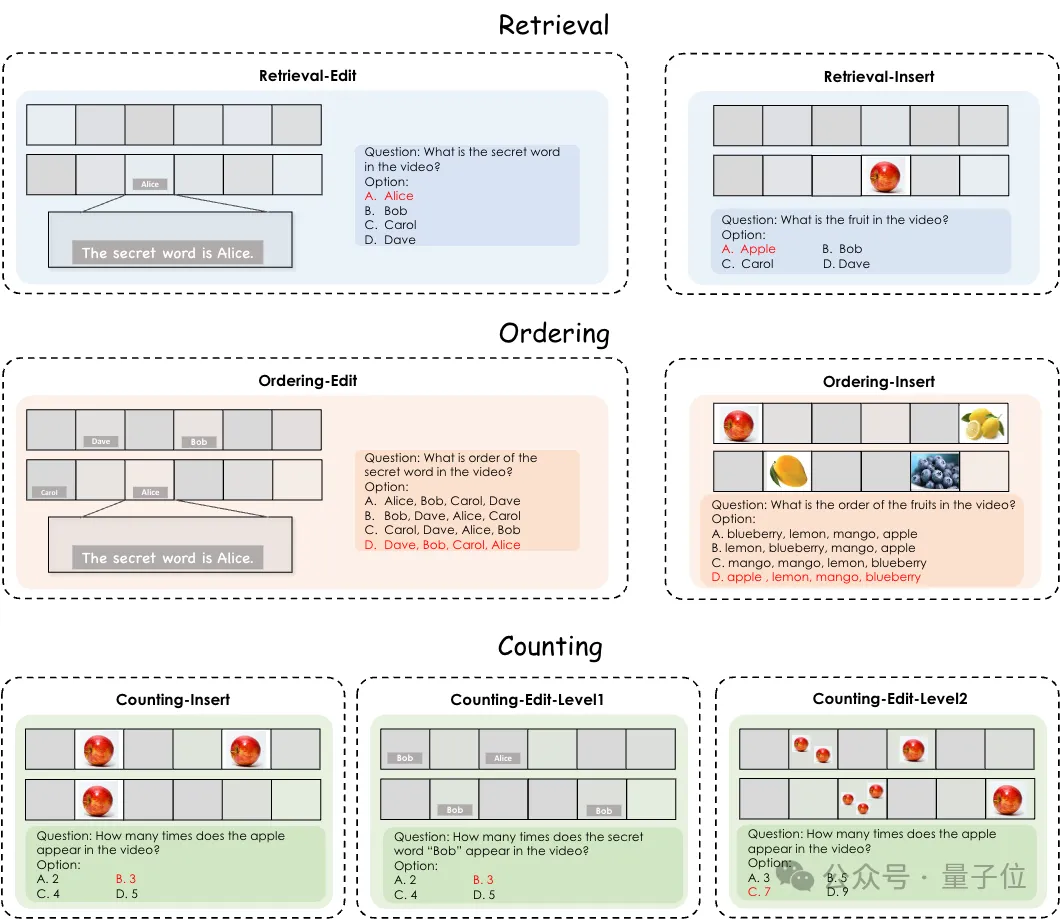
OpenAI和谷歌接连两场发布会,把AI视频推理卷到新高度。 但业界还缺少可以全面评估大模型视频推理能力的基准。 终于,多模态大模型视频分析综合评估基准Video-MME,全面评估多模态大模型的综合视频理解能力,填补了这一领域的空白。
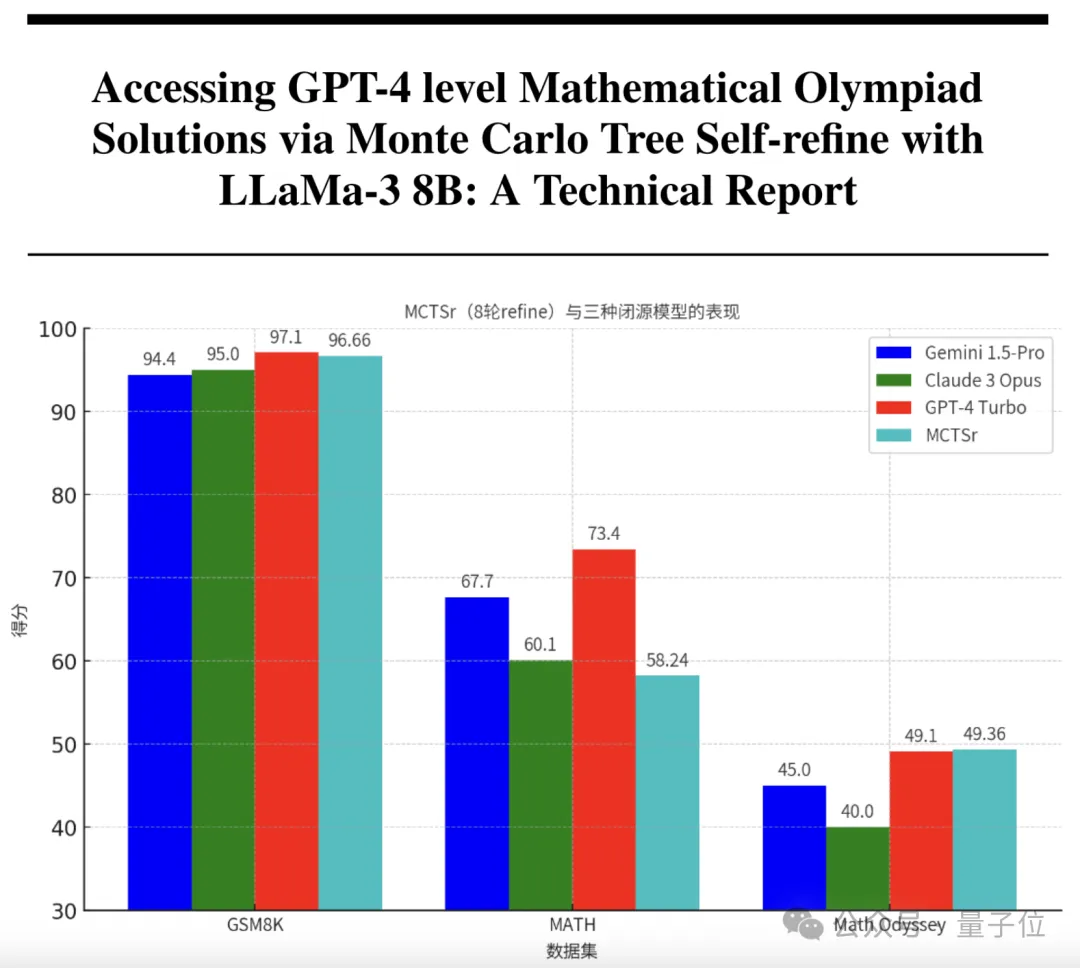
只要1/200的参数,就能让大模型拥有和GPT-4一样的数学能力? 来自复旦和上海AI实验室的研究团队,刚刚研发出了具有超强数学能力的模型。 它以Llama 3为基础,参数量只有8B,却在奥赛级别的题目上取得了比肩GPT-4的准确率。

通过算法层面的创新,未来大语言模型做数学题的水平会不断地提高。

最近两天,一篇入选 ACL 2024 的论文《Can Language Models Serve as Text-Based World Simulators?》在社交媒体 X 上引发了热议,就连图灵奖得主 Yann LeCun 也参与了进来。

大模型是世界模型吗?UA微软等机构最新研究发现,GPT-4在复杂环境的模拟中,准确率甚至不及60%。对此,LeCun激动地表示,世界模型永远都不可能是LLM。