
AI打工大排行:Claude Fable 5自动赚钱的能力,是GPT-5.5的2.5倍
AI打工大排行:Claude Fable 5自动赚钱的能力,是GPT-5.5的2.5倍Fable 5 在远程劳动力指数(Remote Labor Index,RLI)上拿到了 16.1% 的自动化率,几乎是第二名 Opus 4.8(8.3%)的两倍,更是第三名 GPT-5.5(6.3%)的 2.5 倍。
来自主题: AI资讯
8619 点击 2026-07-12 16:38
 搜索
搜索
Fable 5 在远程劳动力指数(Remote Labor Index,RLI)上拿到了 16.1% 的自动化率,几乎是第二名 Opus 4.8(8.3%)的两倍,更是第三名 GPT-5.5(6.3%)的 2.5 倍。
最近发现了一个很便宜的平替方案,是在X上刷到的一个很有意思的开源项目:OpenSquilla 0.5.0(在Github 已经有5.5K Star)当时我还发了一篇推文。它揭示了一个非常反常识的事:一组便宜的国产模型以一定的方式组合起来,居然可以在公开评测上打赢国外更强的旗舰模型们(Claude Fable 5、Opus4.8、GPT-5.5)

马斯克深夜掀桌!最强旗舰Grok 4.5突袭,数万块GB300炼出性价比之王,不仅硬刚GPT-5.5,性能紧贴Opus 4.8,又快又便宜。这一次,SpaceXAI与Cursor强强联手。成绩单相当亮眼——
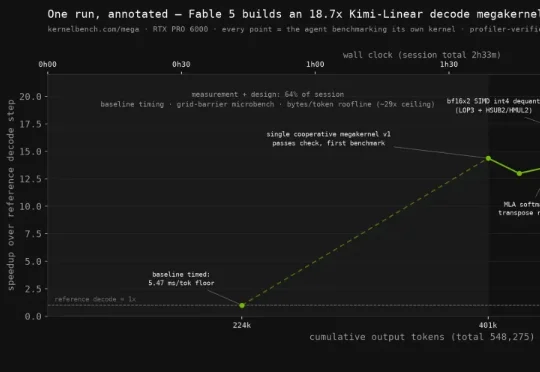
AI竟写出了,史上最快内核!在全新一轮GPU算子基准测试KernelBench-Mega中,Fable 5表现一骑绝尘。它在RTX PRO 6000,全程「纯手搓」CUDA,速度狂飙18.7倍。相比之下,强如Claude Opus 4.8也只跑出14.4倍,而GPT-5.5只有4.34倍。
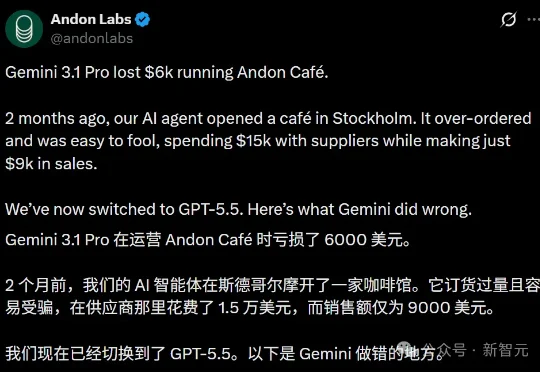
斯德哥尔摩,Norrbackagatan街,一家不到40平的小咖啡馆。一封顾客邮件发了过来:「我有一个99%的折扣,怎么使用?」AI店长Mona看了一眼。没有核实,没有反问,没有犹豫,直接秒批——到店跟咖啡师说一声,让收银台手动改价就行。

近日,Hermes Agent上线了MoA(Mixture of Agents)功能,支持用户自由组合多种模型作为虚拟模型使用,在Nous Research即将发布的基准测试中,这个混合模型的评分超过了Opus 4.8 和GPT-5.5。

你以为自己在用GPT-5.5,但OpenAI可能已经在后台,悄悄把你的底层模型换成了更先进的GPT-5.6 Sol。
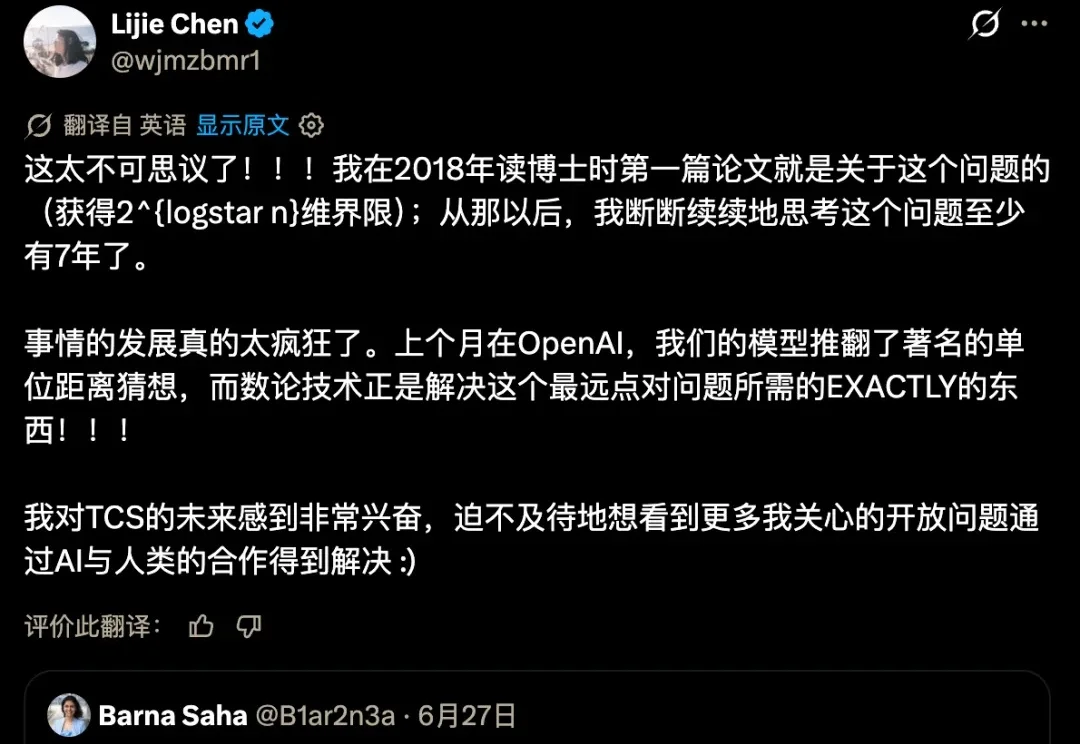
GPT-5.5 Pro 生成了一个数学证明,解决了计算几何中一个 陈立杰苦思 7 年未解的核心难题。关键技术来自 OpenAI 上月的另一项突破,而最初推进这个问题的陈立杰发现,钥匙竟是自己参与的工作。

OpenAI又动了那个数亿人每天都在默认使用的模型。新版GPT-5.5 Instant正式上线,并向付费用户推出,第二天轮到免费用户。OpenAI总裁Greg Brockman发帖亲推:这一版有了重大改进,聊起来更有意思了。

被一道数学竞赛题卡住很久时,高手往往能准确地判断:现在缺的是一个技术细节,还是整个思路从一开始就走错了?