
AI“硬控”拜年
AI“硬控”拜年这个春节,国产AI引发全球轰动,一家叫做DeepSeek的初创科技公司发布了一款推理模型,不仅能力不输OpenAI的o1,训练成本也远低于国外,各行各业更是跟风尝试。1月27日,DeepSeek超过ChatGPT,成为苹果商店美国区免费应用榜单第一,也登顶中国区免费榜,由于用户突然涌入太多,还出现了短暂宕机。
来自主题: AI资讯
8461 点击 2025-01-30 12:46
 搜索
搜索
这个春节,国产AI引发全球轰动,一家叫做DeepSeek的初创科技公司发布了一款推理模型,不仅能力不输OpenAI的o1,训练成本也远低于国外,各行各业更是跟风尝试。1月27日,DeepSeek超过ChatGPT,成为苹果商店美国区免费应用榜单第一,也登顶中国区免费榜,由于用户突然涌入太多,还出现了短暂宕机。

VARGPT是一种新型多模态大模型,能够在单一框架内实现视觉理解和生成任务。通过预测下一个token完成视觉理解,预测下一个scale完成视觉生成,展现出强大的混合模态输入输出能力。

谈到大模型的“国货之光”,除了DeepSeek之外,阿里云Qwen这边也有新动作——首次将开源Qwen模型的上下文扩展到1M长度。
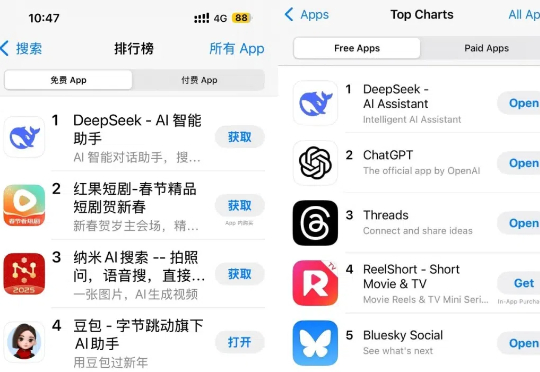
DeepSeek 20 日发布以来获得的热度至今依然没有任何消退的迹象。一觉醒来,DeepSeek 发布的 iOS 应用甚至超越了 ChatGPT 的官方应用,直接登顶 AppStore。
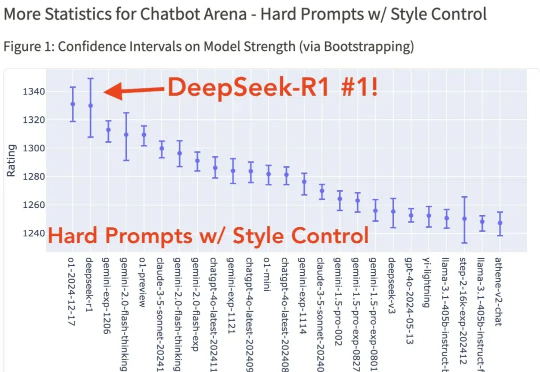
“神秘东方力量”DeepSeek给硅谷带来的影响,还在不断泛起涟漪——刚刚,DeepSeek-R1跻身大模型竞技榜前三。以开源、便宜20倍的“身价”与ChatGPT-4o(2024.11.20)并列。

苏格拉底曾提到的门诺悖论(Meno's paradox)认为,人只能学会自己已经知道的事情;而关于AI辅助编程,谷歌资深工程师最近的一篇博客告诉我们,类似的知识悖论同样存在。
ChatGPT等聊天机器人背后的算法能从各种各样的网络文本中抓取万亿字节的素材,文本来源可以是网络文章,也可以是社媒平台的帖子,还可以是视频里的字幕或评论。

时隔不到一个月,DeepSeek又一次震动全球AI圈。去年 12 月,DeepSeek推出的DeepSeek-V3在全球AI领域掀起了巨大的波澜,它以极低的训练成本,实现了与GPT-4o和Claude Sonnet 3.5等顶尖模型相媲美的性能,震惊了业界。

字节最近推出了一款名为 Trae 的 AI 编程工具,面向海外的AI中文开发环境IDE。号称实现了从Copilot向Autopilot的演进。该工具可选择简体中文或英文,并内置了GPT-4o、Claude-3.5-Sonnet模型供免费使用。
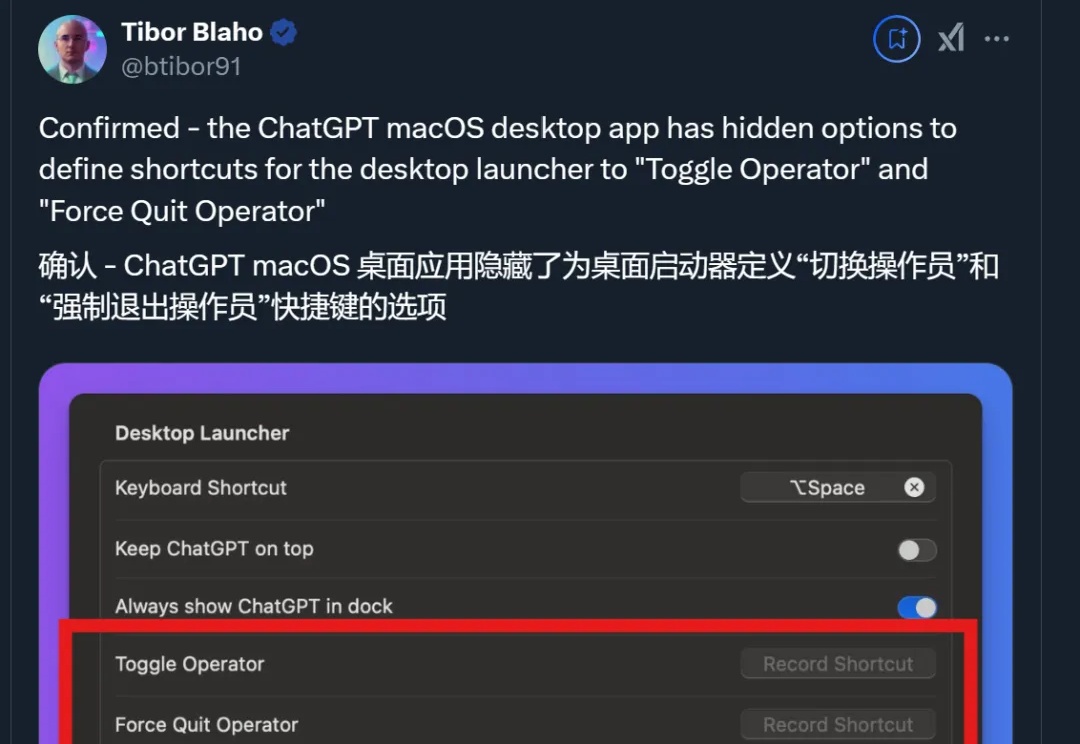
没错,OpenAI的智能体时代真的要来了!