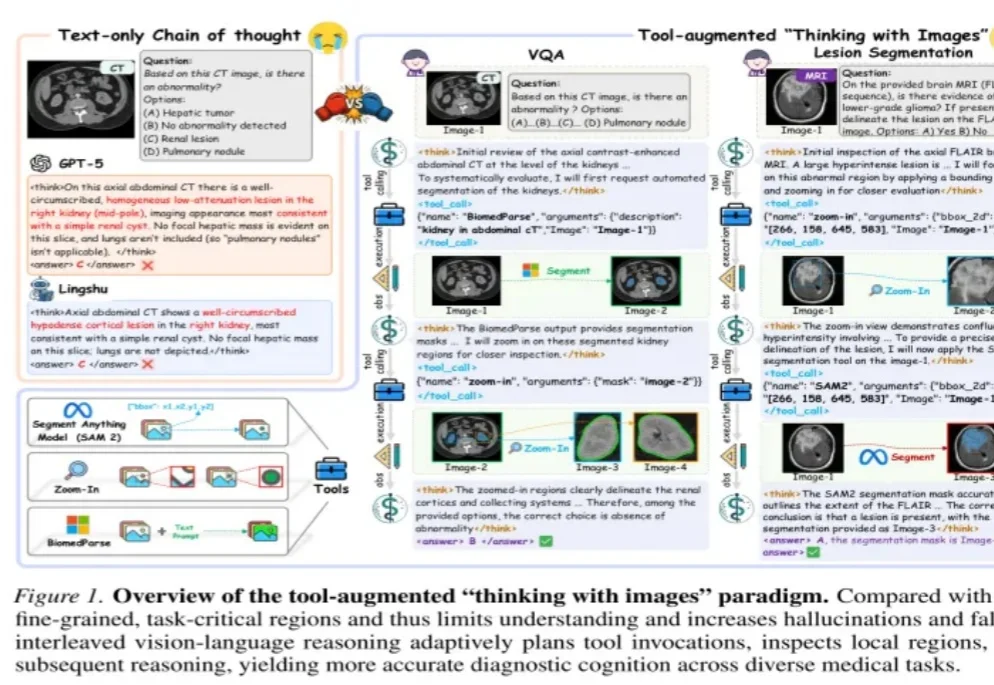
7B打败o3、GPT-5!医学AI智能体让模型学会“看哪里、怎么看”
7B打败o3、GPT-5!医学AI智能体让模型学会“看哪里、怎么看”医学AI会写解释,但不代表它真的“看到”了关键证据。
来自主题: AI技术研报
10211 点击 2026-05-28 14:51
 搜索
搜索
医学AI会写解释,但不代表它真的“看到”了关键证据。

超越 GPT-5.5、Gemini 3.5 Flash、DeepSeek V4 Pro,阿里的最新旗舰模型 Qwen3.7 Max 在编程竞技榜拿下第二名,仅次于 Claude Opus 4.7。除了真实场景的用户选择,在传统的大模型固定评测榜单上,像是终端能力 Terminal Bench、编程能力 SWE Bench 等,Qwen3.7 Max 的表现也是拿下了国产模型的冠军。

一个号称「零污染」的新基准 DeepSWE,用113道原创题撕开了旧编程榜单的遮羞布。

GPT-5.5被扒出「假思考」,用两小时就被偷偷换成mini,200美元月费买了个「薛定谔的脑子」。Trace命令实锤,官方文档亲自认领。往后有纷纷吐槽:OpenAI,你糊弄谁呢?
DeepSeek研究员陈德里,在个人博客更新一篇研究综述论文。用的是他自己的技能DeliAutoResearch,DeepSeek-V4-Pro研究和写作,GPT-Image2画图。论文共迭代6次(V1:4 次,V2:1 次,V3:1 次),总耗时6天,进行了约108轮Agent调用,消耗64.8万token,写了2234行LaTeX代码。
最近,GPT-5.6泄露了!150万Token+神级极简UI,下月紧急上线,奥特曼的「超级智能体」要掀翻整个硅谷?6月AI大战,已经提前爆发了。

没有信息泄漏的专业术数题库面前,Claude、GPT等主流模型集体「翻车」。但一个叫Tianfu Agent的系统,却一举将准确率提升至50%,逼近本届术数大赛人类Top20选手的53.5%平均水平。
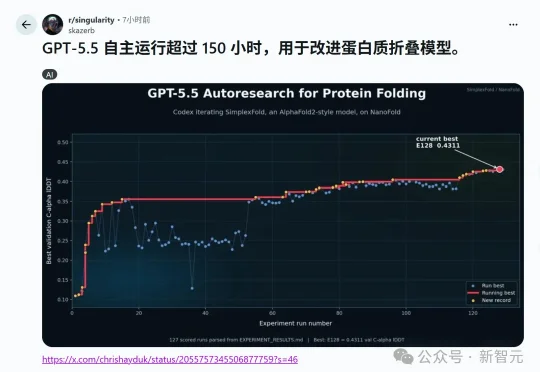
有人晒出开源项目:GPT-5.5连续狂飙150小时,自主挑战诺奖级AlphaFold2!它用拓扑「单纯形」重构蛋白质折叠逻辑,虽然性能暂未登顶,却展示了AI科学家的恐怖潜力:秒回滚、零情绪、全自动进化。科研范式,真要变天了。

姜旭是少数完整参与过 OpenAI 大模型核心技术演进的华人创业者之一。2019 至 2023 年间,他经历了 GPT 系列能力爆发最关键的阶段,工作横跨底层训练 infra、大规模预训练、RLHF 对齐算法与数据构建等核心链路。
昨天,想必大家都被 Google IO 大会刷屏了。