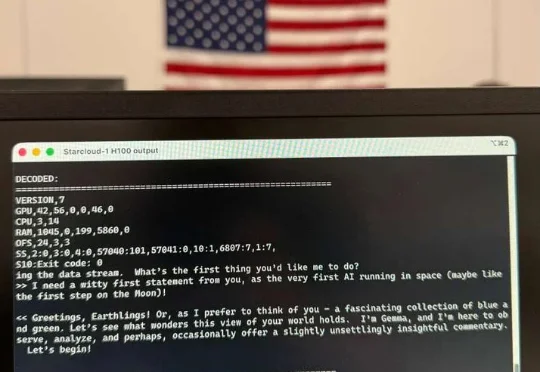
全球首个太空AI诞生,H100在轨炼出!马斯克爆赞
全球首个太空AI诞生,H100在轨炼出!马斯克爆赞见证历史!今天,首个由H100太空GPU训出LLM诞生了,它基于Karpathy nano-GPT训练。不仅如此,谷歌Gemma也在太空成功运行,向世界发出首句问候:地球人,你好。
来自主题: AI资讯
10364 点击 2025-12-11 16:27
 搜索
搜索
见证历史!今天,首个由H100太空GPU训出LLM诞生了,它基于Karpathy nano-GPT训练。不仅如此,谷歌Gemma也在太空成功运行,向世界发出首句问候:地球人,你好。

在本周一举行的 Open Source Summit Japan 主题演讲中,Linux 基金会执行董事 Jim Zemlin 抛出了一个耐人寻味的判断: “AI 可能还谈不上全面泡沫化,但大模型或许已经开始泡沫化了。”

据特朗普最新社交媒体消息透露,美国政府计划允许英伟达(Nvidia)对华出口其H200芯片,这是这家AI芯片设计公司为维持其在世界第二大经济体的市场准入所做努力的最新转折。该芯片的性能高于此前获准销售的H20,但不如该公司今年发布的顶级Blackwell产品,也不如明年将推出的Rubin系列芯片。

在工业界动辄十万卡的暴力美学面前,学术界正沦为算力的「贫民窟」。当高校人均不足0.1张卡时,AI科研的主导权之争或许已经没有了悬念。
本文为Milvus Week系列第5篇,该系列旨在把Zilliz团队过去半年多积累的先进的技术实践和创新整理成多篇干货深度文章发布。

GPU编程变天了。
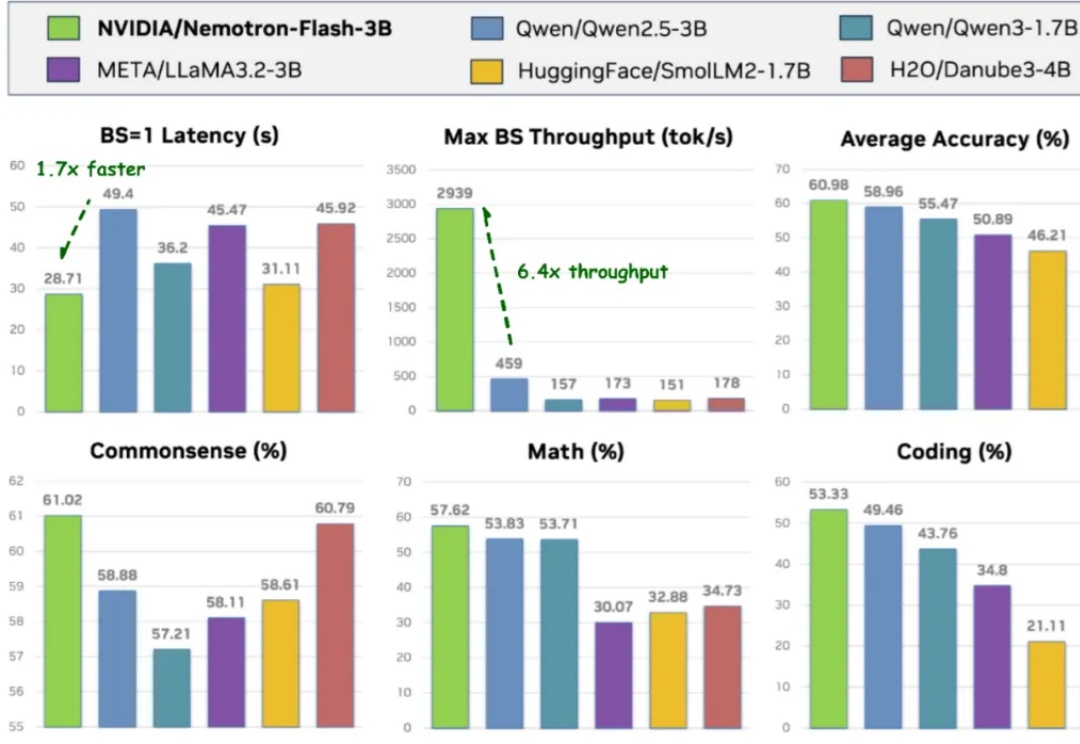
导读 过去两年,小语言模型(SLM)在业界备受关注:参数更少、结构更轻,理应在真实部署中 “更快”。但只要真正把它们跑在 GPU 上,结论往往令人意外 —— 小模型其实没有想象中那么快。

在AI数据中心里,数以万计的英伟达H100 GPU,正静静地躺在地上吃灰。这些单价3万美元、被黄仁勋称为「工业黄金」的芯片,本该全速运转,为GPT-5或Sora注入灵魂,但此刻——它们没有电。

一听到谷歌要抢走10%的年收入,英伟达罕见地慌了。

带领IDEA研究院(粤港澳大湾区数字经济研究院)走过第五个年头的沈向洋,新鲜分享了他用来梳理智能演进的五个维度——作为IDEA研究院创院理事长,相比给出一个技术路径路线图,他更希望提出一个识别机会的思考框架,帮助创新者在智能演进中找到技术、产品与商业的切口。