OpenAI 不想再「跪着」买显卡了
OpenAI 不想再「跪着」买显卡了《金融时报》最新消息,OpenAI 正在和博通合作,自研一颗代号 “XPU” 的 AI 推理芯片,预计会在 2026 年量产,由台积电代工。不同于英伟达 的 GPU,这款芯片不会对外销售,而是专门满足 OpenAI 内部的训练与推理需求,用来支撑即将上线的 GPT-5 等更庞大的模型。
来自主题: AI资讯
9681 点击 2025-09-06 12:50
 搜索
搜索
《金融时报》最新消息,OpenAI 正在和博通合作,自研一颗代号 “XPU” 的 AI 推理芯片,预计会在 2026 年量产,由台积电代工。不同于英伟达 的 GPU,这款芯片不会对外销售,而是专门满足 OpenAI 内部的训练与推理需求,用来支撑即将上线的 GPT-5 等更庞大的模型。

昨天,美团低调地开源了其560B参数的混合专家(MoE)模型——LongCat-Flash。 一时间,大家的目光都被吸引了过去,行业内的讨论大多围绕着它在公开基准测试中媲美顶尖模型的性能数据,以及其精巧的MoE架构设计。

短短两天,寒武纪两度超越贵州茅台,成为 A 股第一高价「股王」。而推动用户预期不断攀升的,离不开 AI 市场的持续火热。
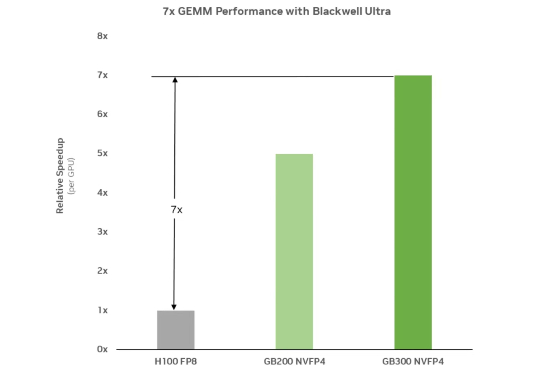
前些天,DeepSeek 在发布 DeepSeek V3.1 的文章评论区中,提及了 UE8M0 FP8 的量化设计,声称是针对即将发布的下一代国产芯片设计。
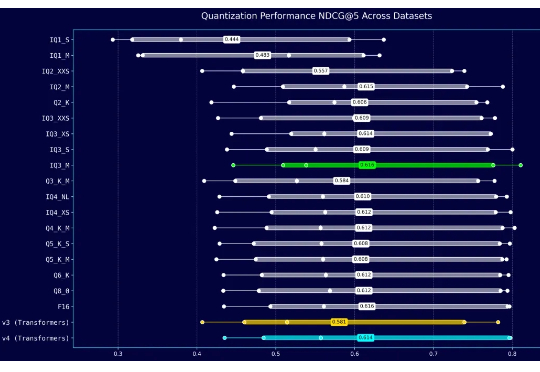
两周前,我们发布了 jina-embeddings-v4 的 GGUF 格式及其多种动态量化版本。jina-embeddings-v4 原模型有 37.5 亿参数,在我们的 GCP G2 GPU 实例上直接运行时效率不高。因此,我们希望通过更小、更快的 GGUF 格式来加速推理。
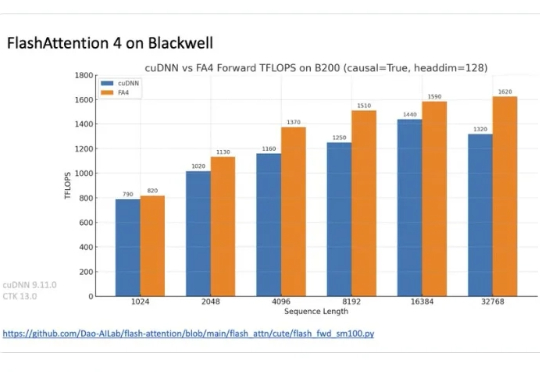
在正在举办的半导体行业会议 Hot Chips 2025 上,TogetherAI 首席科学家 Tri Dao 公布了 FlashAttention-4。
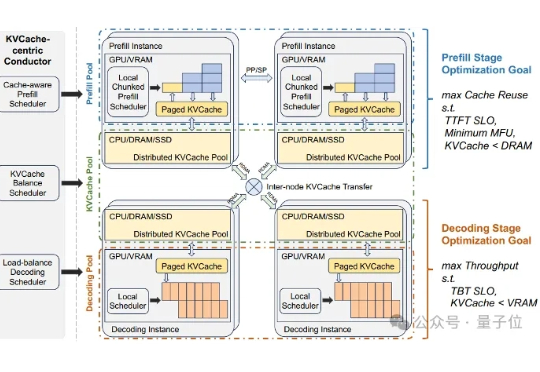
当大语言模型(LLM)走向千行百业,推理效率与显存成本的矛盾日益尖锐。

英伟达直接把服务器级别的算力塞进了机器人体内。 全新的机器人计算平台Jetson Thor正式发售,基于最新的Blackwell GPU架构,AI算力直接飙升到2070 TFLOPS,比上一代Jetson Orin提高至整整7.5倍,同时能效提高至3.5倍。
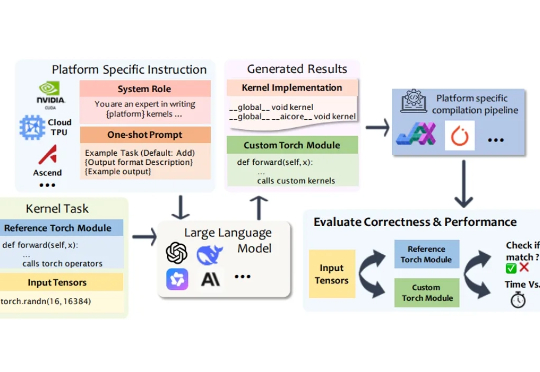
在深度学习模型的推理与训练过程中,绝大部分计算都依赖于底层计算内核(Kernel)来执行。计算内核是运行在硬件加速器(如 GPU、NPU、TPU)上的 “小型高性能程序”,它负责完成矩阵乘法、卷积、归一化等深度学习的核心算子运算。

当人们热议着AI大模型如何改变世界时,很少有人会注意到,这场技术革命的真正“战场”,竟隐藏在一块块墨绿色的电路板上。