马斯克“巨硬计划”新动作曝光!从0建起算力集群,6个月完成OpenAI&甲骨文15个月的工作
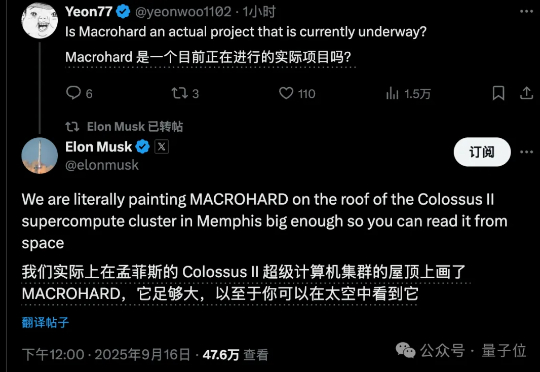
马斯克“巨硬计划”新动作曝光!从0建起算力集群,6个月完成OpenAI&甲骨文15个月的工作马斯克“巨硬计划”(MACROHARD)新动作曝光: 6个月从0建起算力集群,已完成200MW供电规模,足以支持11万台英伟达GB200 GPU NVL72。仅用6个时间,完成了OpenAI和甲骨文等合作花费15个月完成的工作,再次创造纪录。
来自主题: AI资讯
8519 点击 2025-09-19 09:21