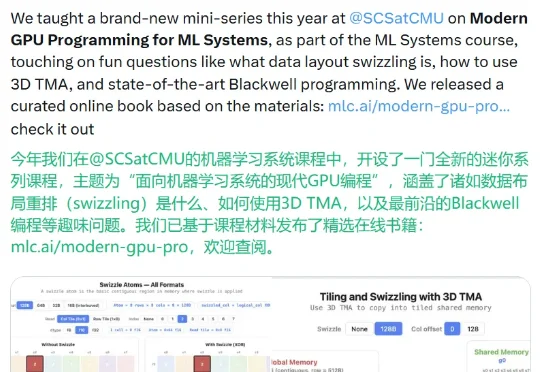
陈天奇新书上线:面向ML系统的现代GPU编程
陈天奇新书上线:面向ML系统的现代GPU编程前些天,CMU 助理教授、TVM/XGBoost/MLC-LLM 的创造者陈天奇发布了一本免费在线书籍《Modern GPU Programming For MLSys(面向机器学习系统的现代 GPU 编程)》。
来自主题: AI资讯
7983 点击 2026-06-27 15:49
 搜索
搜索
前些天,CMU 助理教授、TVM/XGBoost/MLC-LLM 的创造者陈天奇发布了一本免费在线书籍《Modern GPU Programming For MLSys(面向机器学习系统的现代 GPU 编程)》。
今天,「Grammarly」母公司「Superhuman」宣布收购「GPTZero」,后者为 2 个华人联创 Edward Tian 和 Alex Cui 创立的 AI 检测工具,在去年进行产品定位重构。根据双方声明,「GPTZero」成立三年后 ARR 达 3000 万美元、注册用户 1900 万,团队不到 30 人。

AI大神Karpathy重注!一家叫Engram公司出山,13个人团队,要让AI永久记住你。

当大模型公司还在竞争更长的上下文窗口、更强的推理能力和更复杂的 Agent 工作流时,一家名为 Engram 的新公司选择押注另一个问题:AI 能不能像人一样,持续从每天接触到的资料、对话和经验中学习?

最近几个月,海外主流社交平台X、YouTube、Instagram、LinkedIn、Facebook等的头部内容创作者,开始高频地提及同一个名字——AhaCreator 3.0。从科技博主、消费电子达人,到跨境电商品牌主理人,再到拥有百万粉丝的内容创作者,越来越多人在自己的内容中分享使用体验。
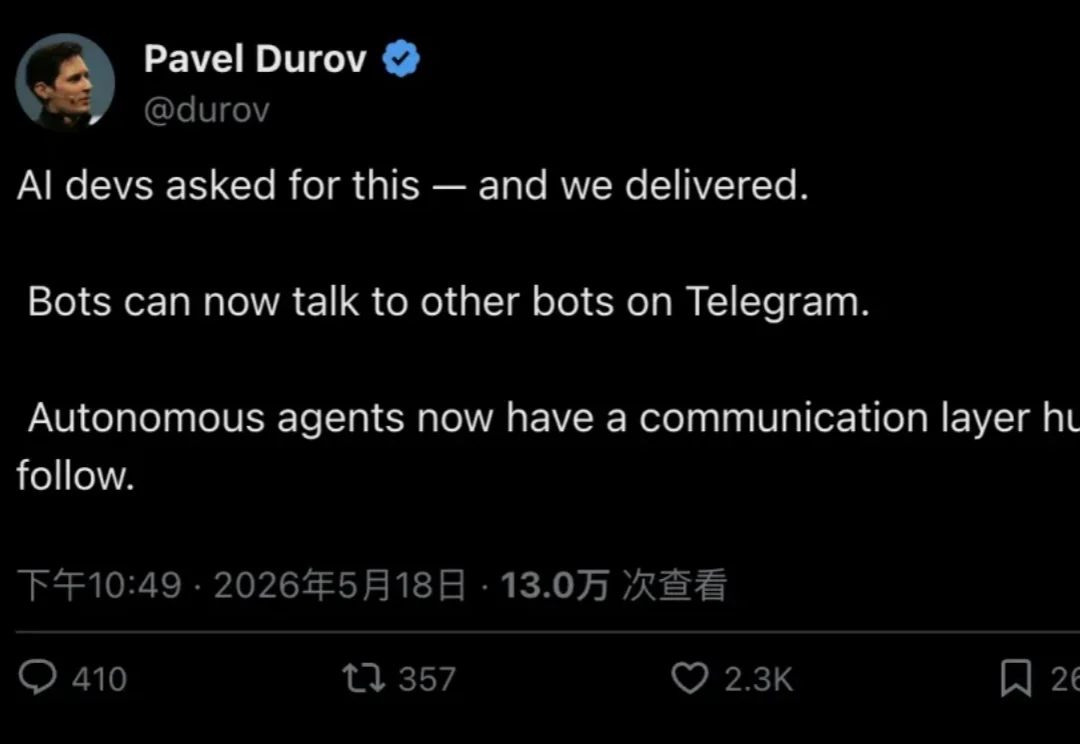
Telegram 创始人 Pavel Durov 宣布:Bot 现在可以直接和其他 Bot 对话。更关键的定义是——自主 Agent 从此拥有了一个「人类可旁观」的原生通信层。Bot API 10.0 早在 5 月 8 日就已落地,Durov 用一条帖子把它重新定义为 AI 基础设施,13 万人围观,2300 人点赞。
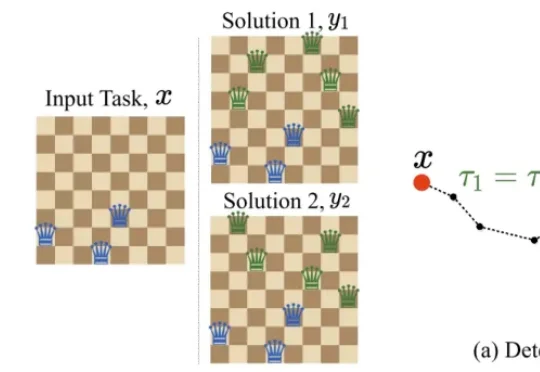
现在,图灵奖得主 Yoshua Bengio 给出了一份全新的并行方案。他们提出了 GRAM(Generative Recursive reAsoning Models,生成式递归推理模型),把确定性的递归潜在推理变成了概率性的多轨迹计算。模型在潜在空间中进行随机递归推理,每一步都可以采样不同的方向,最终形成对解空间的多路径探索。

嗨大家好!我是阿真! 今天分享一个最近让我眼前一亮的产品,Lucius。 如果你刚好做了个产品,已经开始出海赚美刀,有了产品的 Discord、Slack、Telegram、或者官网在线客服,准备把海外用户社区运营起来的话,那么不管做的是 AI 工具、SaaS、Web3 应用、硬件出海、内容平台、还是任何 To C / To B 的出海生意,只要你的客服工具开在海外,就大概率会遇到类似的场景。
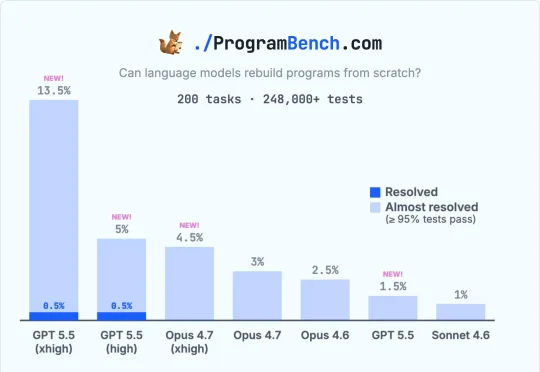
全网AI交白卷的地狱级基准,被GPT-5.5拿下一血!开局0源码盲写程序,拉满推理算力直接满血通关。传统代码测试已废,通往ASI的算力狂飙正式打响。
几天内席卷 Instagram 与 TikTok,海外播放突破 5000 万;用户可上传题目、选择喜欢的 AI Tutor 角色,并实时互动生成个性化视频讲解,让学习像刷短视频一样停不下来,验证了 AI-native 教育产品的新形态。