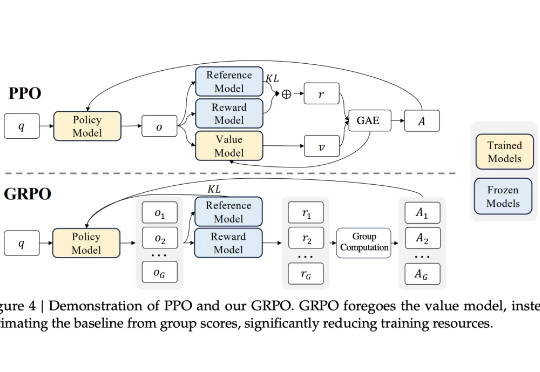
DeepSeek的GRPO会导致模型崩溃?看下Qwen3新范式GSPO
DeepSeek的GRPO会导致模型崩溃?看下Qwen3新范式GSPO众所周知,大型语言模型的训练通常分为两个阶段。第一阶段是「预训练」,开发者利用大规模文本数据集训练模型,让它学会预测句子中的下一个词。第二阶段是「后训练」,旨在教会模型如何更好地理解和执行人类指令。
来自主题: AI技术研报
9831 点击 2025-08-08 11:22
 搜索
搜索
众所周知,大型语言模型的训练通常分为两个阶段。第一阶段是「预训练」,开发者利用大规模文本数据集训练模型,让它学会预测句子中的下一个词。第二阶段是「后训练」,旨在教会模型如何更好地理解和执行人类指令。