
AI争霸战开启!OpenAI急建10万块GB200超算,马斯克10万块H100月末开训
AI争霸战开启!OpenAI急建10万块GB200超算,马斯克10万块H100月末开训马斯克官宣xAI建造的世界最大超算集群,由10万块H100搭建,预计本月末开始投入训练。另一边,OpenAI再次加码,将打造由10万块GB200组成的超算,完全碾压xAI。
来自主题: AI资讯
11552 点击 2024-07-16 19:48
 搜索
搜索
马斯克官宣xAI建造的世界最大超算集群,由10万块H100搭建,预计本月末开始投入训练。另一边,OpenAI再次加码,将打造由10万块GB200组成的超算,完全碾压xAI。
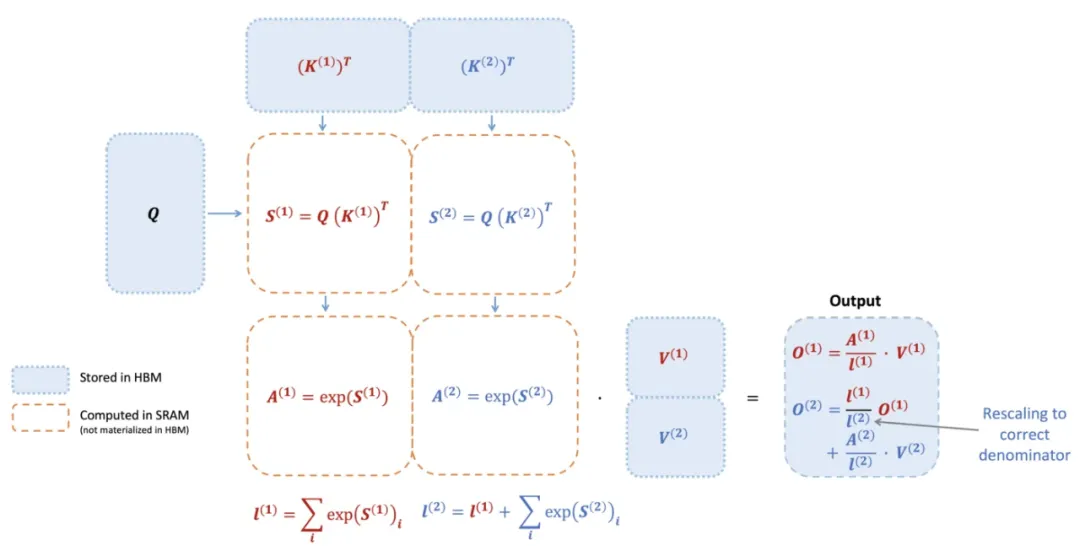
740 TFLOPS!迄今最强 FlashAttention 来了。

时隔一年,FlashAttention又推出了第三代更新,专门针对H100 GPU的新特性进行优化,在之前的基础上又实现了1.5~2倍的速度提升。
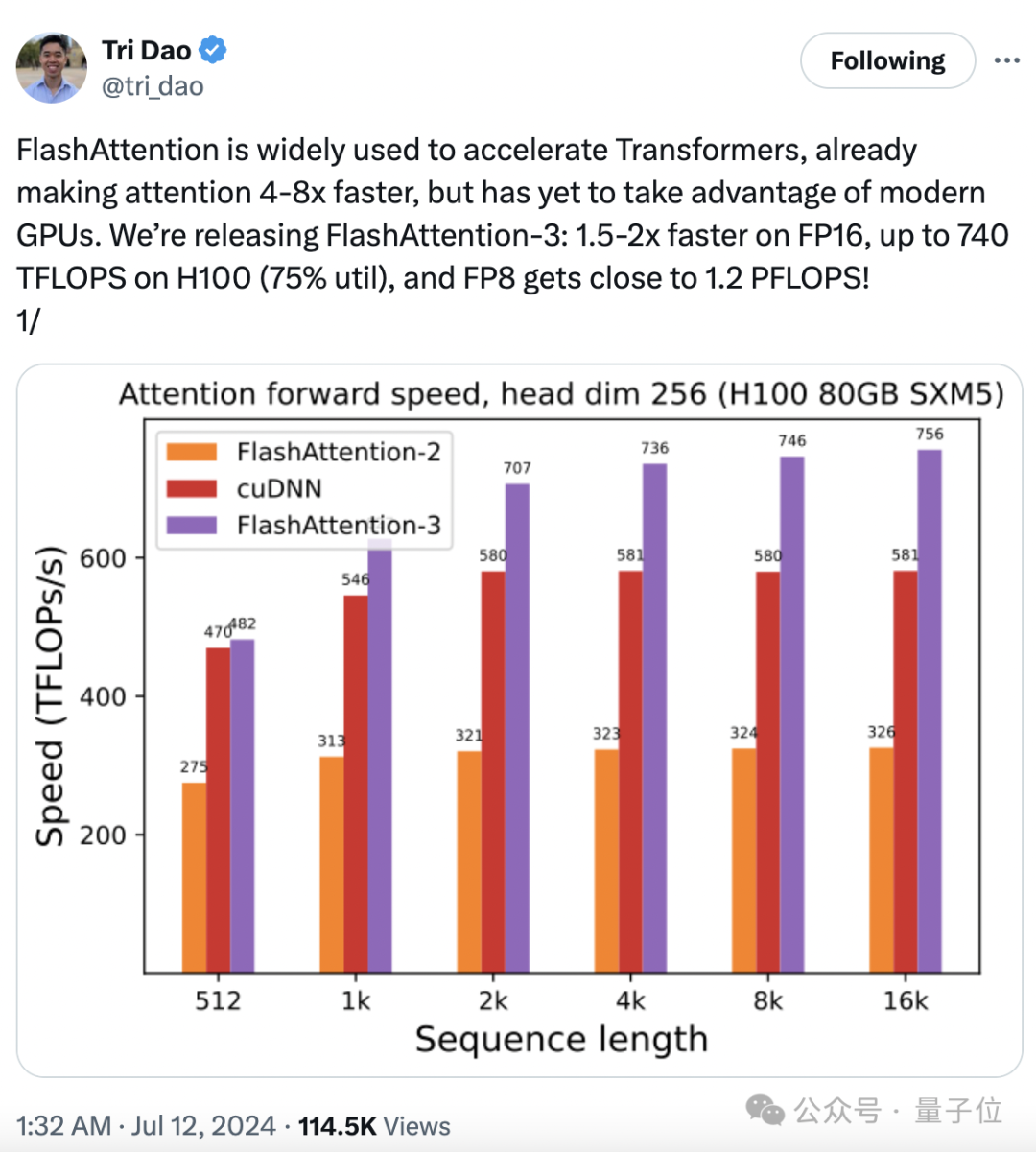
大模型训练推理神作,又更新了!
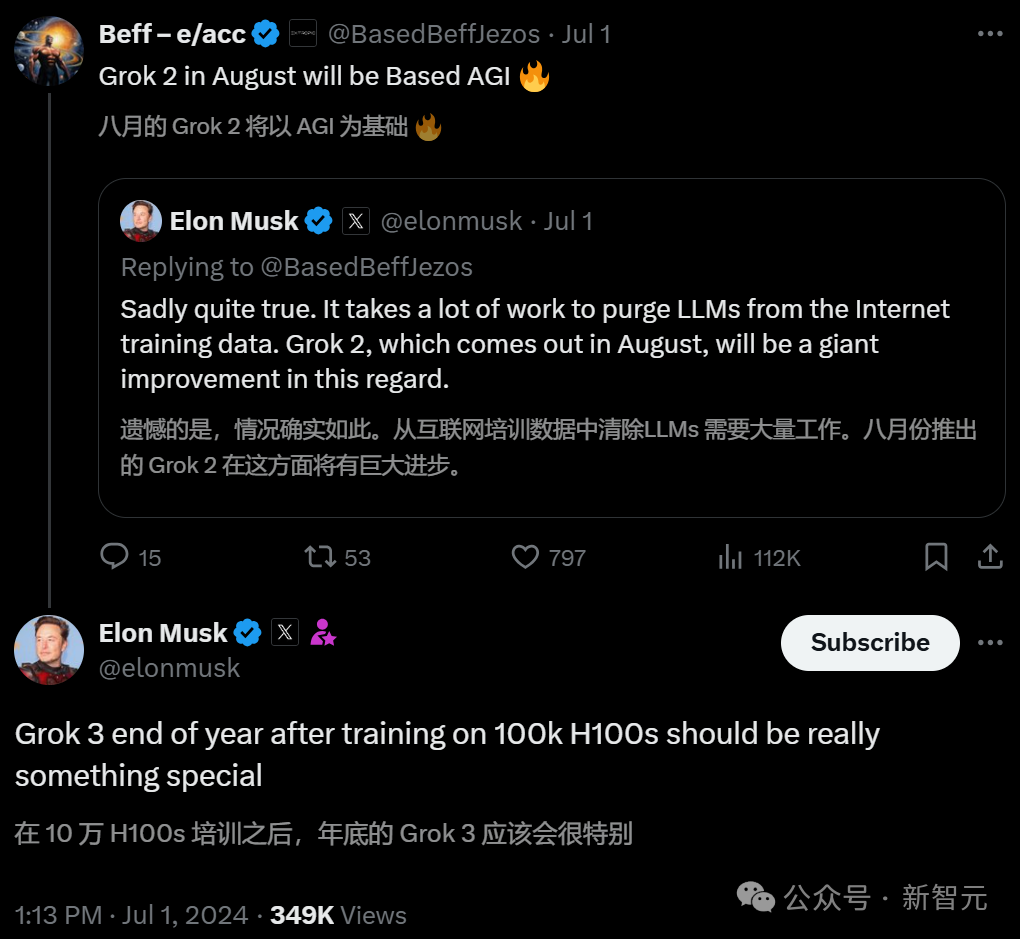
马斯克为Grok 3要豪掷近40亿美元狂买10万张H100,GPT-6的训练则可能要耗资百亿。然而红杉和高盛近日都给行业泼了冷水:每年要挣6000亿美元才能支付的巨额硬件支出,换来的却只是OpenAI 34亿美元的收入,绝大多数初创连1亿美元都达不到。而如果全世界的AI泡沫都被戳破,很可能就会导致新的经济危机。
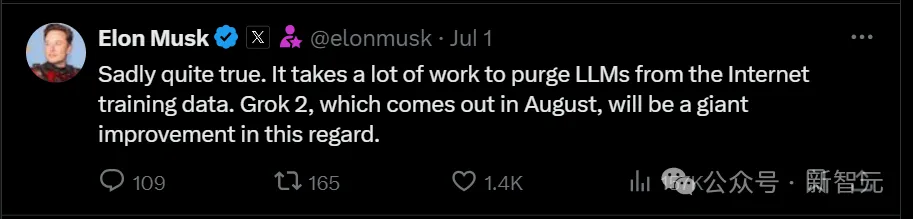
马斯克连回两条推文为xAI造势,宣布8月发布Grok 2,年底将推出在10万张H100上训练的Grok 3,芯片加持创新数据训练,打造对标GPT的新一代大语言模型。
10万张H100卡构成的超级AI算力集群就像是现代人类文明的奇观,是人类通向AGI的钥匙。AI时代的军备竞赛已经拉开帷幕,赌注是天量的Capex支出,胜者则有机会成为AI时代的造物主。

全美TOP 5的机器学习博士痛心发帖自曝,自己实验室里H100数目是0!这也引起了ML社区的全球网友大讨论。显然,相比普林斯顿、哈佛这样动辄三四百块H100的GPU大户,更常见的是GPU短缺的「穷人」。同一个实验室的博士,甚至时常会出现需要争抢GPU的情况。

在中文互联网上,英伟达每天都在被颠覆。绝大部分自媒体和短视频达人都讨厌英伟达,包括周鸿祎在内。他们千方百计地指出,某种替代品(不管是不是国产)的性能指标已经超过英伟达A100或H100,后者即将沦为资本市场历史上最大的泡沫云云。尤其是在B站、小红书这样的平台,“英伟达将迅速被替代”可以被视为一致观点,反对这个观点的人将遭到群嘲。

可在单张A100/H100 GPU或TPU主机上高效运行全精度推理。