
ICML 2026史上最严新规:LLM不得列为作者,滥用AI直接退稿
ICML 2026史上最严新规:LLM不得列为作者,滥用AI直接退稿ICML 2026论文可以投了,截止日期2026年1月28日。今年针对AI使用,组委会强调了三点:LLM不可以「署名」;严禁提示注入,否则拒稿;以及扩大AI审稿。
来自主题: AI资讯
9034 点击 2025-11-06 14:50
 搜索
搜索
ICML 2026论文可以投了,截止日期2026年1月28日。今年针对AI使用,组委会强调了三点:LLM不可以「署名」;严禁提示注入,否则拒稿;以及扩大AI审稿。

全新一代 video-SALMONN 2/2+、首个开源推理增强型音视频理解大模型 video-SALMONN-o1(ICML 2025)、首个高帧率视频理解大模型 F-16(ICML 2025),以及无文本泄漏基准测试 AVUT(EMNLP 2025) 正式发布。新阵容在视频理解能力与评测体系全线突破,全面巩固 SALMONN 家族在开源音视频理解大模型赛道的领先地位。

从ICML到ACL,张铭教授的实验室十年两度拿下世界顶会「最佳论文」。甚至连中学生,都能在这里提前卷科研,拿下「小诺贝尔奖」。一间实验室,如何同时孵化论文大奖、百亿企业和未来科学家?这背后,是科研思维与创新教育的独特结合。

人类和AI在工作中如何协作?耶鲁和南大的研究人员合作的这篇论文讲清楚了。 这篇论文提出了一个数学框架,通过把工作技能拆分成两个层次来解释这个问题
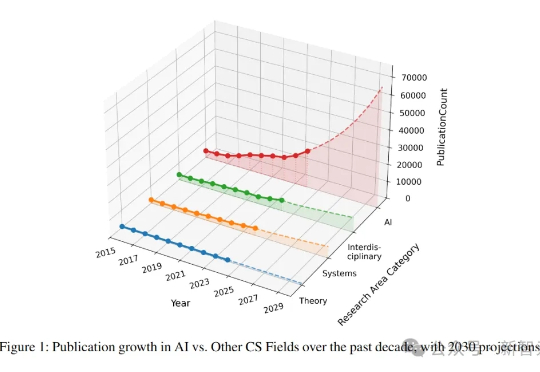
就在刚刚,NUS研究者呼吁:NeurIPS、ICML、CVPR三大顶会,正在反噬整个AI学术圈!平均每个研究者每年被逼狂发4.5篇论文,已经身心俱疲。总之,顶会模型已经濒临崩溃,是时候踩刹车了!

近年来,大语言模型(LLM)的能力越来越强,但它们的“饭量”也越来越大。这个“饭量”主要体现在计算和内存上。当模型处理的文本越来越长时,一个叫做“自注意力(Self-Attention)”的核心机制会导致计算量呈平方级增长。这就像一个房间里的人开会,如果每个人都要和在场的其他所有人单独聊一遍,那么随着人数增加,总的对话次数会爆炸式增长。
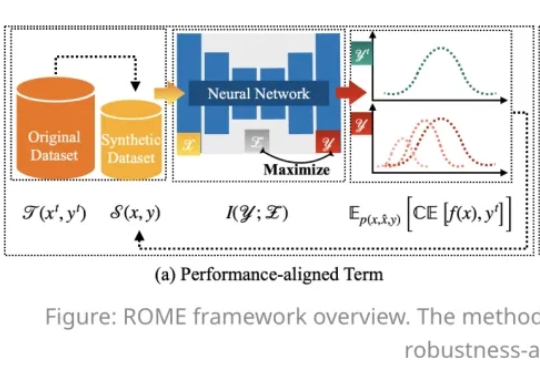
在人工智能模型规模持续扩大的今天,数据集蒸馏(Dataset Distillation,DD)方法能够通过使用更少的数据,达到接近完整数据的训练效果,提升模型训练效率,降低训练成本。
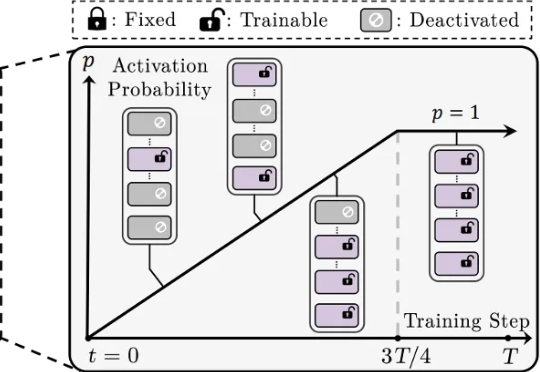
还在为 LoRA 训练不稳定、模型融合效果差、剪枝后性能大降而烦恼吗?来自香港城市大学、南方科技大学、浙江大学等机构的研究者们提出了一种简单的渐进式训练策略,CoTo,通过在训练早期随机失活一部分适配器,并逐渐提高其激活概率,有效缓解了层级不均衡问题,并显著增强了模型在多任务融合和剪枝等操作上的鲁棒性和有效性。该工作已被机器学习顶会 ICML 2025 接收。
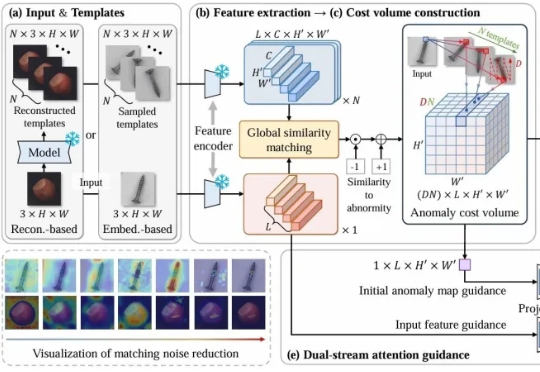
CostFilter-AD通过构建异常代价体并滤波来优化异常检测,能精准识别微小缺陷,无需缺陷样本训练。可作为通用插件提升现有检测系统,帮助工厂提前发现缺陷,提高产品质量。
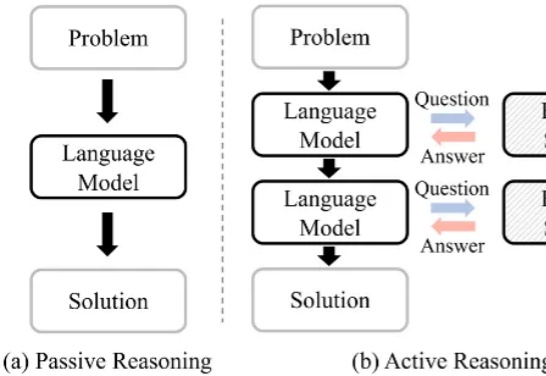
大语言模型(Large Language Model, LLM)在复杂推理任务中表现卓越。借助链式思维(Chain-of-Thought, CoT),LLM 能够将复杂问题分解为简单步骤,充分探索解题思路并得出正确答案。LLM 已在多个基准上展现出优异的推理能力,尤其是数学推理和代码生成。