
ACL 2026|打破推理同质化!阿里达摩院新作让RLVR从重复采样走向有效探索
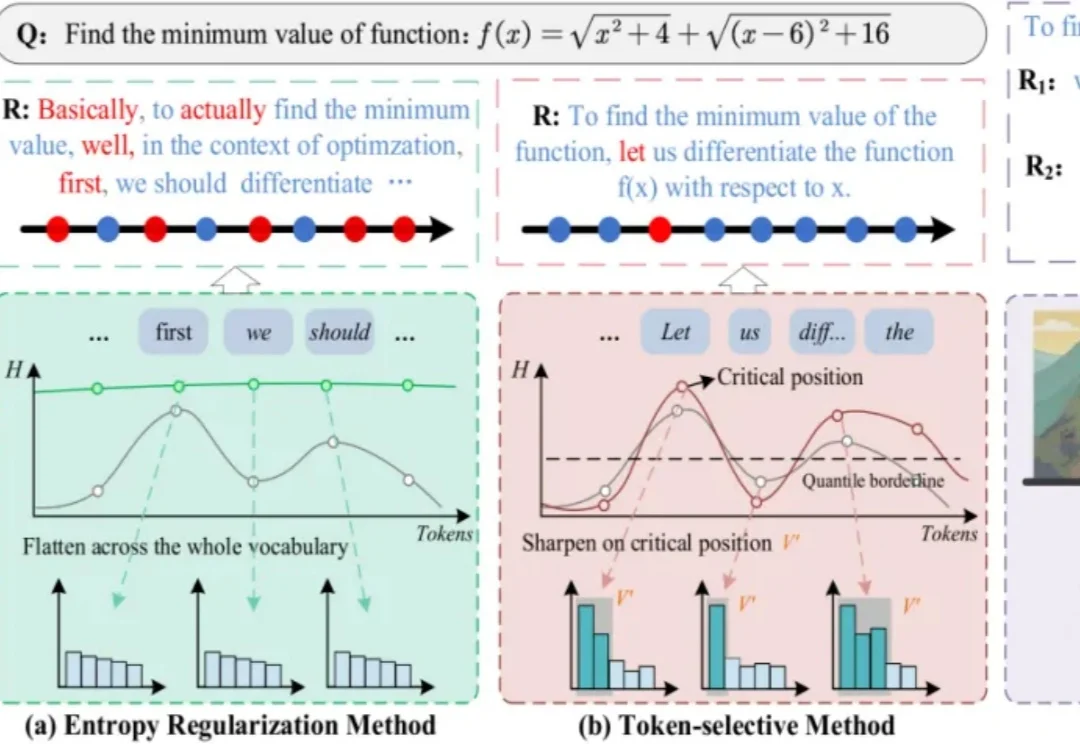
ACL 2026|打破推理同质化!阿里达摩院新作让RLVR从重复采样走向有效探索I²B-LPO 是一个面向 RLVR 后训练的探索增强框架,通过改进 rollout 策略引导模型生成更多样化的推理轨迹,将探索行为从 “重复采样” 推进到 “在关键节点生成更具区分度的推理轨迹”,在多个数学基准上同时提升准确率与语义多样性,最高分别达 5.3% 和 7.4%。该工作接收于 ACL 2026 Main,来自阿里达摩院 - 智能决策团队。
来自主题: AI技术研报
9576 点击 2026-05-14 14:24