CVPR 2026 | 1000万段驾驶视频,教会模型如何估计相机位姿
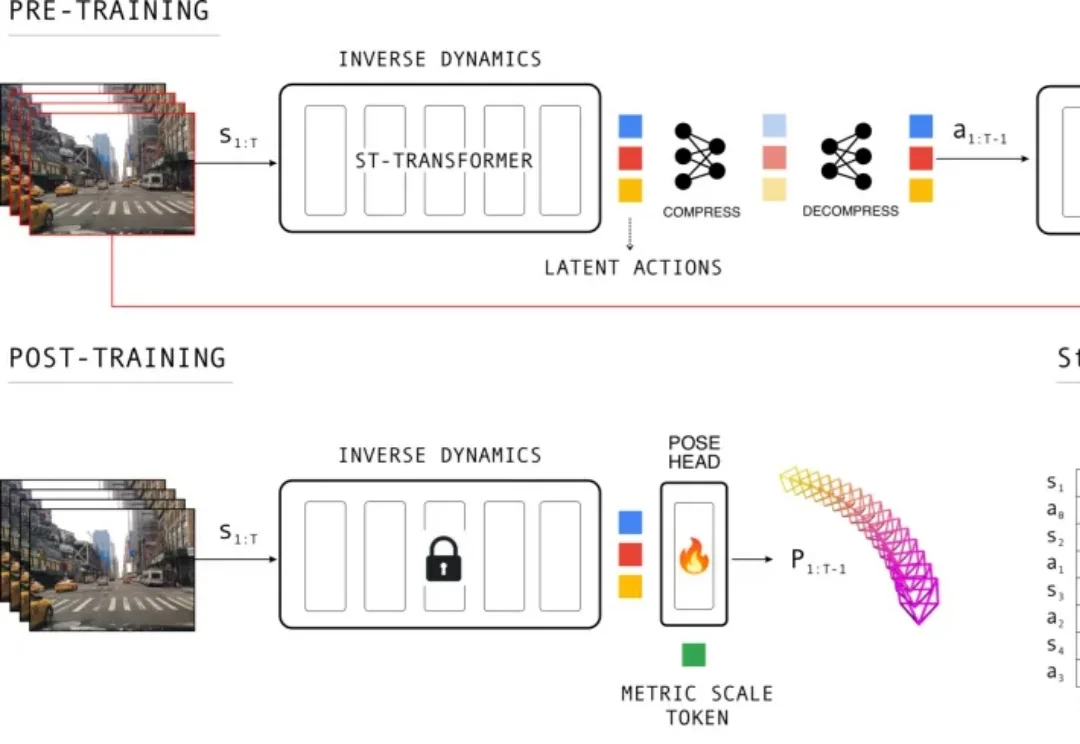
CVPR 2026 | 1000万段驾驶视频,教会模型如何估计相机位姿不用百万级 3D 标注,模型也能从普通驾驶视频中学会「自己是怎么动的」。Wayve 的 LA-Pose 试图把未标注视频里的运动信号,转化为自动驾驶系统所需的相机位姿估计能力。
来自主题: AI技术研报
7311 点击 2026-05-27 16:10
 搜索
搜索
不用百万级 3D 标注,模型也能从普通驾驶视频中学会「自己是怎么动的」。Wayve 的 LA-Pose 试图把未标注视频里的运动信号,转化为自动驾驶系统所需的相机位姿估计能力。