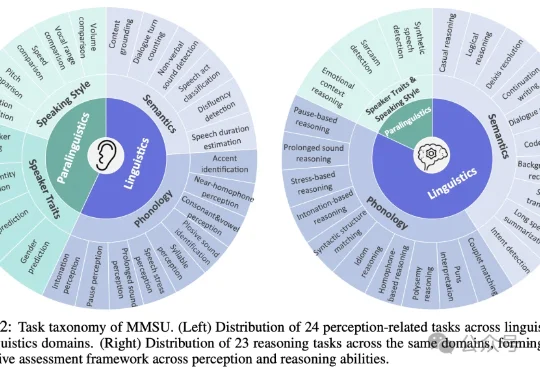
大模型真听懂了吗?最全综合性口语感知与推理基准 | ICLR'26
大模型真听懂了吗?最全综合性口语感知与推理基准 | ICLR'26随着多模态大模型能力不断扩展,语音大模型(SpeechLLMs) 已从语音识别走向复杂语音交互。然而,当模型逐渐进入真实口语交互场景,一个更基础的问题浮现出来:我们是否真正定义清楚了「语音理解」的能力边界?
来自主题: AI技术研报
10834 点击 2026-02-24 15:35
 搜索
搜索
随着多模态大模型能力不断扩展,语音大模型(SpeechLLMs) 已从语音识别走向复杂语音交互。然而,当模型逐渐进入真实口语交互场景,一个更基础的问题浮现出来:我们是否真正定义清楚了「语音理解」的能力边界?

近日,微软Bing Ads与DKI团队发表论文《AdNanny: One Reasoning LLM for All Offline Ads Recommendation Tasks》,宣布基于DeepSeek-R1 671B打造了统一的离线推理中枢AdNanny,用单一模型承载所有离线任务。这标志着从维护一系列任务特定模型,转向部署一个统一的、推理中心化的基础模型,从
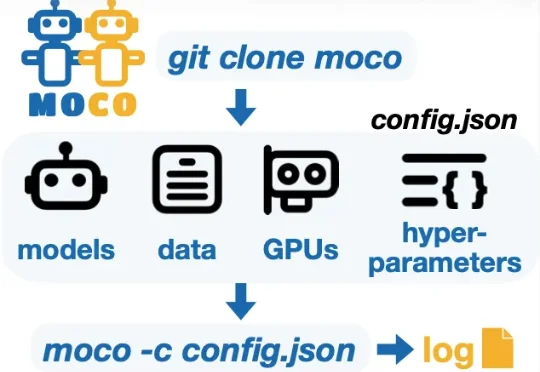
为了支持多模型协同研究并加速这一未来愿景的实现,华盛顿大学 (University of Washington) 冯尚彬团队联合斯坦福大学、哈佛大学等研究人员提出 MoCo—— 一个针对多模型协同研究的 Python 框架。MoCo 支持 26 种在不同层级实现多模型交互的算法,研究者可以灵活自定义数据集、模型以及硬件配置,比较不同算法,优化自身算法,以此构建组合式人工智能系统。MoCo 为设计、
基于真实居民健康档案构建的MedLLM-EHR-EVAL-V2评测集显示,星火医疗大模型在智能健康分析、报告解读、运动饮食建议、辅助诊疗、智能用药审核等关键任务上,得分均显著超越国内外主流大模型。
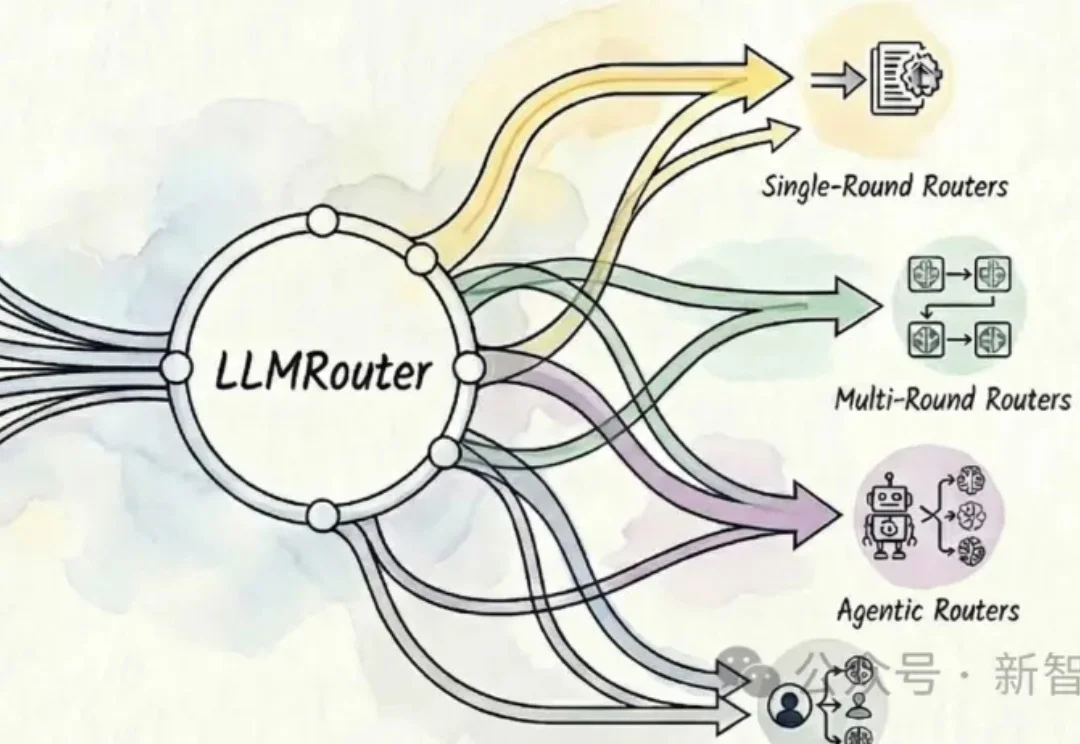
UIUC开源的智能模型路由框架LLMRouter可以自动为大模型应用选择最优模型,提供16+路由策略,覆盖单轮选择、多轮协作、个性化偏好和Agent式流程,在性能、成本与延迟间灵活权衡。
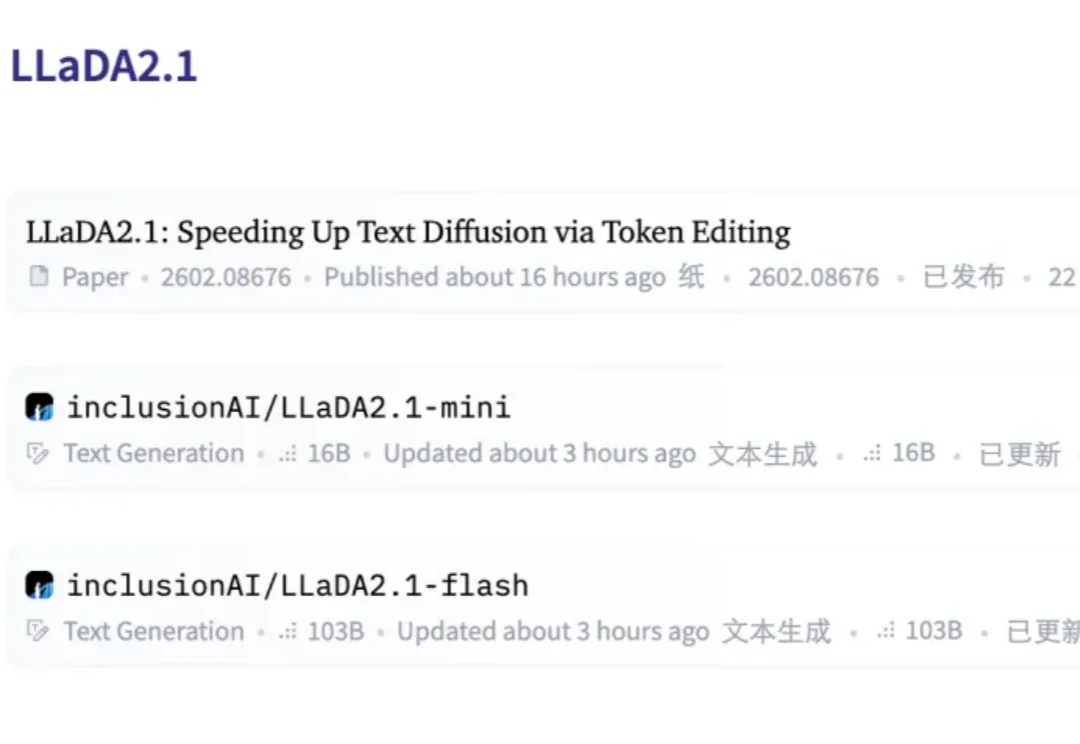
扩散语言模型(dLLM),这个曾被认为是「小众赛道」的研究方向,如今终于迎来了质变。
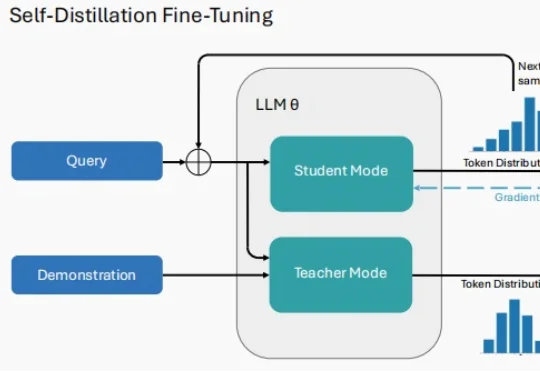
2026 年刚拉开序幕,大模型(LLM)领域的研究者们似乎达成了一种默契。 当你翻开最近 arXiv 上最受关注的几篇论文,会发现一个高频出现的词汇:Self-Distillation。

大规模表格模型(LTM)而非大规模语言模型(LLM)的 Fundamental 公司 Nexus 模型,在多个重要方面突破了当代人工智能实践。该模型具有确定性——即每次被询问相同问题时都会给出相同答案——且不依赖定义当代大多数人工智能实验室模型的 Transformer 架构 。
来自上海交通大学、清华大学、微软研究院、麻省理工学院(MIT)、上海 AI Lab、小红书、阿里巴巴、港科大(广州)等机构的研究团队,系统梳理了近年来大语言模型在数据准备流程中的角色变化,试图回答一个业界关心的问题:LLM 能否成为下一代数据管道的「智能语义中枢」,彻底重构数据准备的范式?

2025 年 1 月 20 日,DeepSeek 发布了推理大模型 DeepSeek-R1,在学术界和工业界引发了对大模型强化学习方法的广泛关注与研究热潮。 研究者发现,在数学推理等具有明确答案的任务