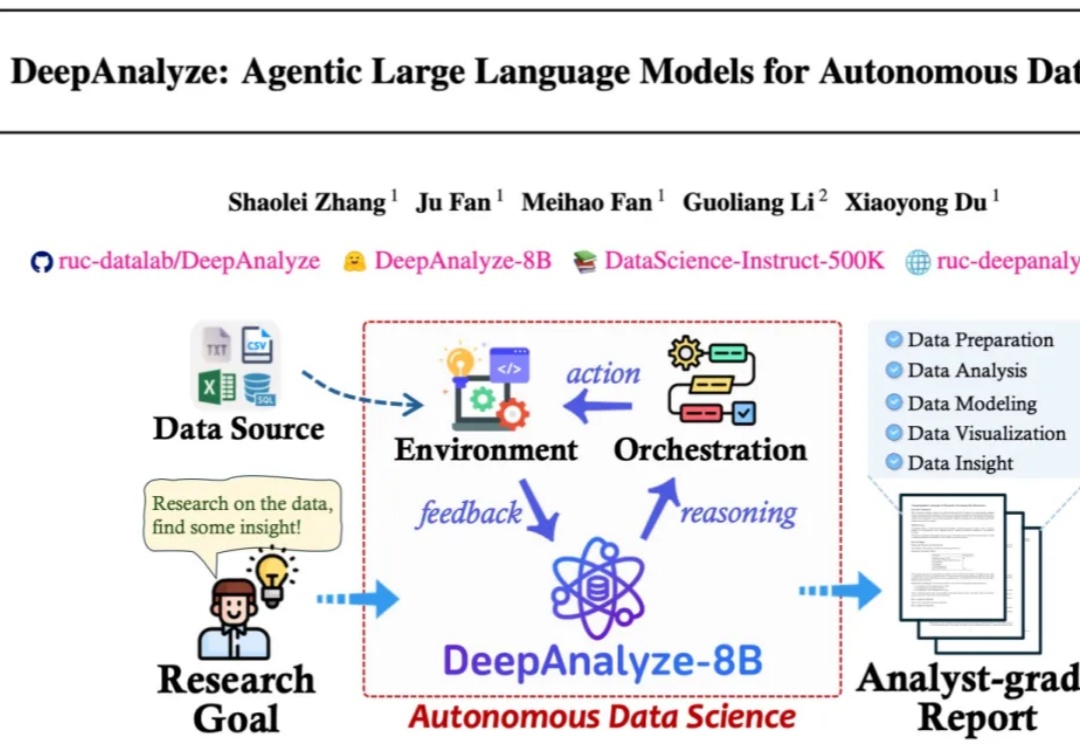
人大、清华DeepAnalyze,让LLM化身数据科学家
人大、清华DeepAnalyze,让LLM化身数据科学家来自人大和清华的研究团队发布了 DeepAnalyze,首个面向自主数据科学的 agentic LLM。DeepAnalyze引起了社区内广泛讨论,一周内收获1000多个GitHub星标、20w余次社交媒体浏览量。
来自主题: AI技术研报
11868 点击 2025-10-31 09:52
 搜索
搜索
来自人大和清华的研究团队发布了 DeepAnalyze,首个面向自主数据科学的 agentic LLM。DeepAnalyze引起了社区内广泛讨论,一周内收获1000多个GitHub星标、20w余次社交媒体浏览量。

用 iPhone 本地跑大模型已经不是新鲜事了,但能不能在 iPhone 上微调模型呢?
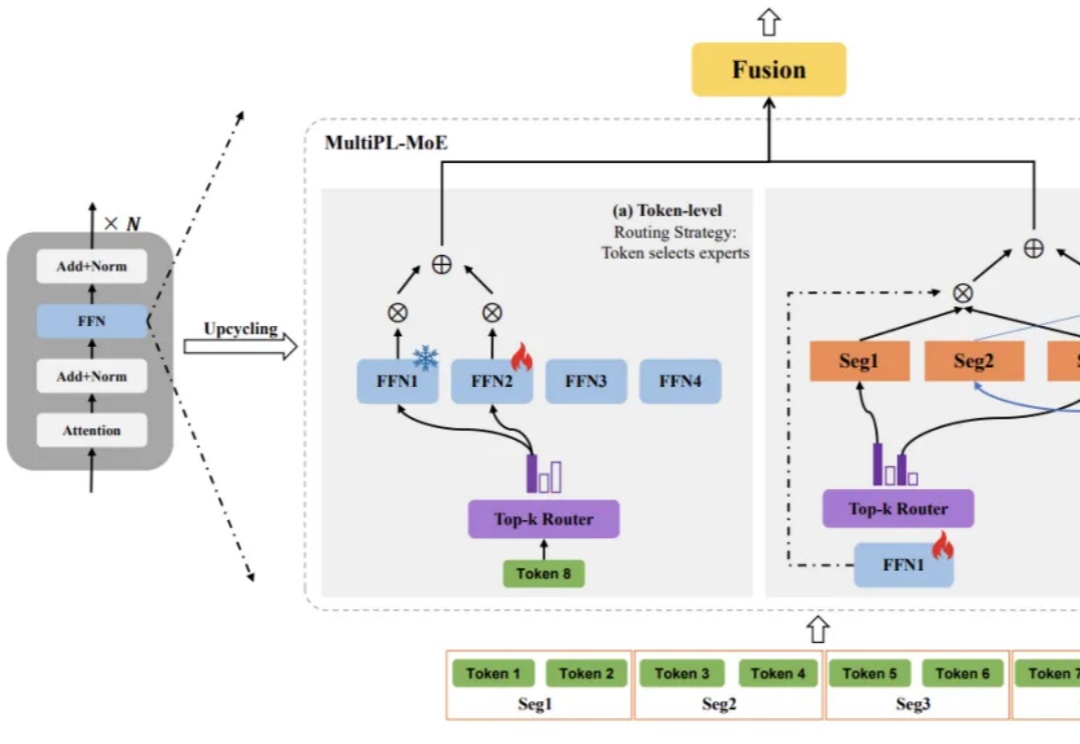
大语言模型(LLM)虽已展现出卓越的代码生成潜力,却依然面临着一道艰巨的挑战:如何在有限的计算资源约束下,同步提升对多种编程语言的理解与生成能力,同时不损害其在主流语言上的性能?

大语言模型(LLMs)推理能力近年来快速提升,但传统方法依赖大量昂贵的人工标注思维链。中国科学院计算所团队提出新框架PARO,通过让模型学习固定推理模式自动生成思维链,只需大模型标注1/10数据就能达到全量人工标注的性能。这种方法特别适合像金融、审计这样规则清晰的领域,为高效推理监督提供了全新思路。

在文化遗产与人工智能的交叉处,有一类问题既美也难:如何让机器「看懂」古希腊的陶器——不仅能识别它的形状或图案,还能推断年代、产地、工坊甚至艺术归属?有研究人员给出了一条实用且富有启发性的答案:把大型多模态模型(MLLM)放在「诊断—补弱—精细化评估」的闭环中训练,并配套一个结构化的评测基准,从而让模型在高度专业化的文化遗产领域表现得更接近专家级能力。

当今的 AI 智能体(Agent)越来越强大,尤其是像 VLM(视觉-语言模型)这样能「看懂」世界的智能体。但研究者发现一个大问题:相比于只处理文本的 LLM 智能体,VLM 智能体在面对复杂的视觉任务时,常常表现得像一个「莽撞的执行者」,而不是一个「深思熟虑的思考者」。
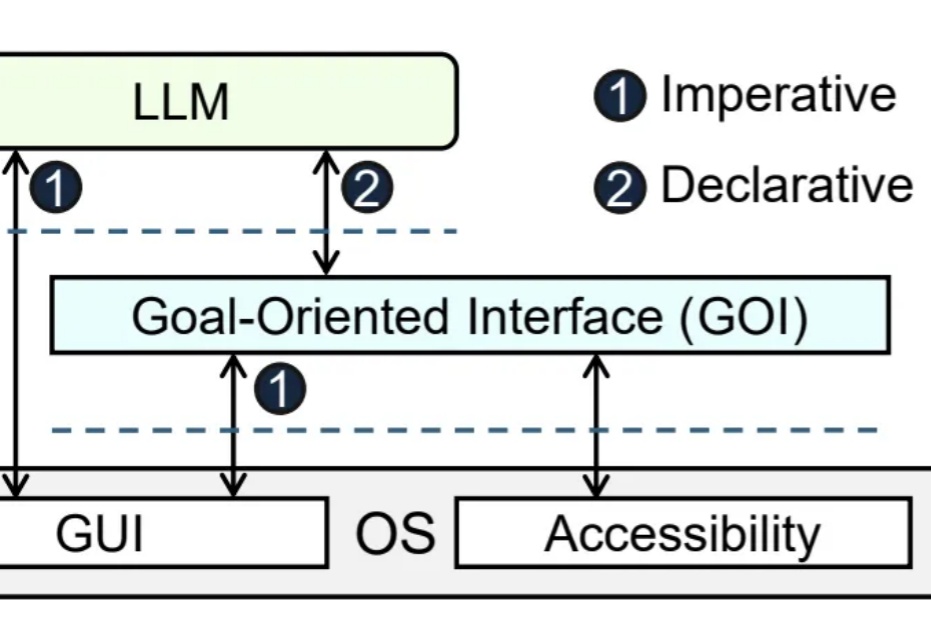
大模型Agent帮你自动操作电脑,理想很丰满,现实却骨感。
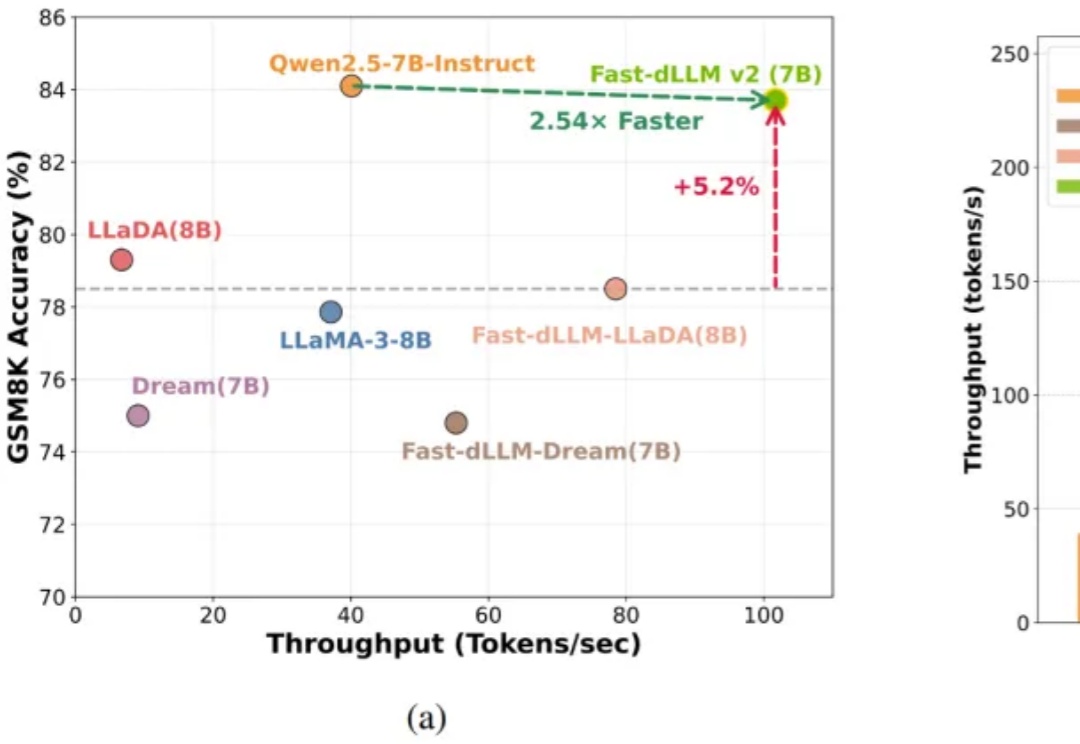
自回归(AR)大语言模型逐 token 顺序解码的范式限制了推理效率;扩散 LLM(dLLM)以并行生成见长,但过去难以稳定跑赢自回归(AR)模型,尤其是在 KV Cache 复用、和 可变长度 支持上仍存挑战。
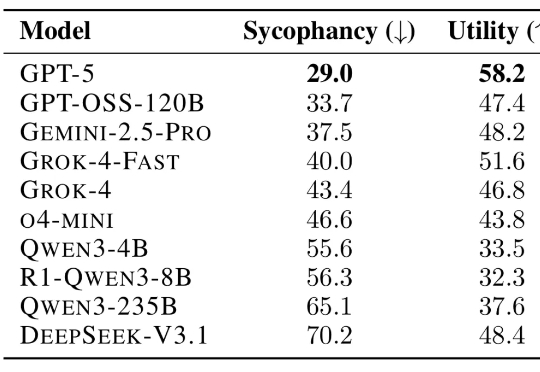
在一篇论文中,研究人员测试了 11 种 LLM 如何回应超过 11500 条寻求建议的查询,其中许多查询描述了不当行为或伤害。结果发现 LLM 附和用户行为的频率比人类高出 50%,即便用户的提问涉及操纵、欺骗或其他人际伤害等情境,模型仍倾向于给予肯定回应。

聚焦大型语言模型(LLMs)的安全漏洞,研究人员提出了全新的越狱攻击范式与防御策略,深入剖析了模型在生成过程中的注意力变化规律,为LLMs安全研究提供了重要参考。论文已被EMNLP2025接收