# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
幻觉,作为AI圈家喻户晓的概念,这个词您可能已经听得耳朵起茧了。我们都知道它存在,也普遍接受了它似乎无法根除,是一个“老大难”问题。但正因如此,一个更危险的问题随之而来:当我们对幻觉的存在习以为常时,我们是否也开始对它背后的系统性风险变得麻木?我们是真的从第一性原理上理解了它,还是仅仅在用一个又一个的补丁(比如RAG)来被动地应对它?

这正是这篇来自巴塞罗那大学(Universitat de Barcelona)的深度研究想要回答的核心问题。它不只是重复“幻觉不可避免”这个我们已经熟知的结论,而是深入到了问题的最底层,用严谨的计算理论和一份前所未有的完整“幻觉谱”,为我们揭示了它的系统性真相。这篇文章将带您深入这份研究,目的不是告诉您一个新秘密,而是帮助您将已经“知道”的事情,转化为真正“理解”的工程智慧,并最终在您的产品设计中,将幻觉从一个烦人的“Bug”,变成一个可以被精确管理和利用的、最重要的“边界条件”。
只要数据够好、模型够大,幻觉就不叫事,甚至有一天能被彻底根除,之前有相当一部分人这么认为,但研究者们给出了一个相当有冲击力的结论:对于任何基于现有计算范式的LLM,幻觉都是理论上不可避免的。为了让这个结论站得住脚,他们首先给“幻觉”下了一个非常严谨的定义。


研究者将问题抽象化:想象一个代表“绝对真理”的函数 f,对于任何问题 s,它总能给出唯一的正确答案 f(s)。而我们的LLM,则是一个试图学习并模仿 f 的可计算函数 h。基于此,幻觉的正式定义就清晰了:论文将幻觉定义为一个可计算的LLM(表示为 h)和一个可计算的“基准真相”函数(表示为 f)之间的不一致 。基准真相函数 f 代表了对于任何输入 s,都存在一个唯一正确的输出 f(s) 。如果一个LLM在所有训练阶段,对于至少一个输入 s,其输出 h(s) 不等于正确答案 f(s),那么这个LLM就被认为产生了幻觉。
那么,“不可避免”的结论又是如何得出的呢?这里研究者们动用了一个强大的数学工具,对角化论证(diagonalization argument)。这是一个由康托尔开创,后被哥德尔和图灵等人用来证明理论边界的经典方法。简单来说,研究者通过这个方法,构造出了一个理论上的“捣蛋”真相函数f,这个f被设计为永远与任何一个给定的LLM h 的输出不一致,从而证明了以下三个令人警醒的定理:
这些定理导出了一个至关重要的推论:LLM无法通过自我反思来根除幻觉。这意味着,无论模型的“思考链”多复杂,它本质上仍是一个封闭的计算系统,无法跳出自身的局限来验证所有知识的真伪。所以LLM不是一个偶尔犯错的知识库,而是一个本质上无法保证绝对真实性的语言概率引擎。之前我也介绍过一个重要研究《实锤,我崩溃了,LLM根本无法100%根除幻觉》

LLM幻觉的定理与推论
幻觉的麻烦之处在于它表现形式多样,远不止是捏造事实那么简单,研究者们为此建立了一个相当完备的分类体系。理解这个图谱,是您识别并设计策略应对它的第一步。
研究者提出了两对核心的分类,帮助我们从根源上理解幻觉的性质。
内在幻觉 (Intrinsic) vs. 外在幻觉 (Extrinsic)
事实性幻觉 (Factuality) vs. 忠实性幻觉 (Faithfulness)
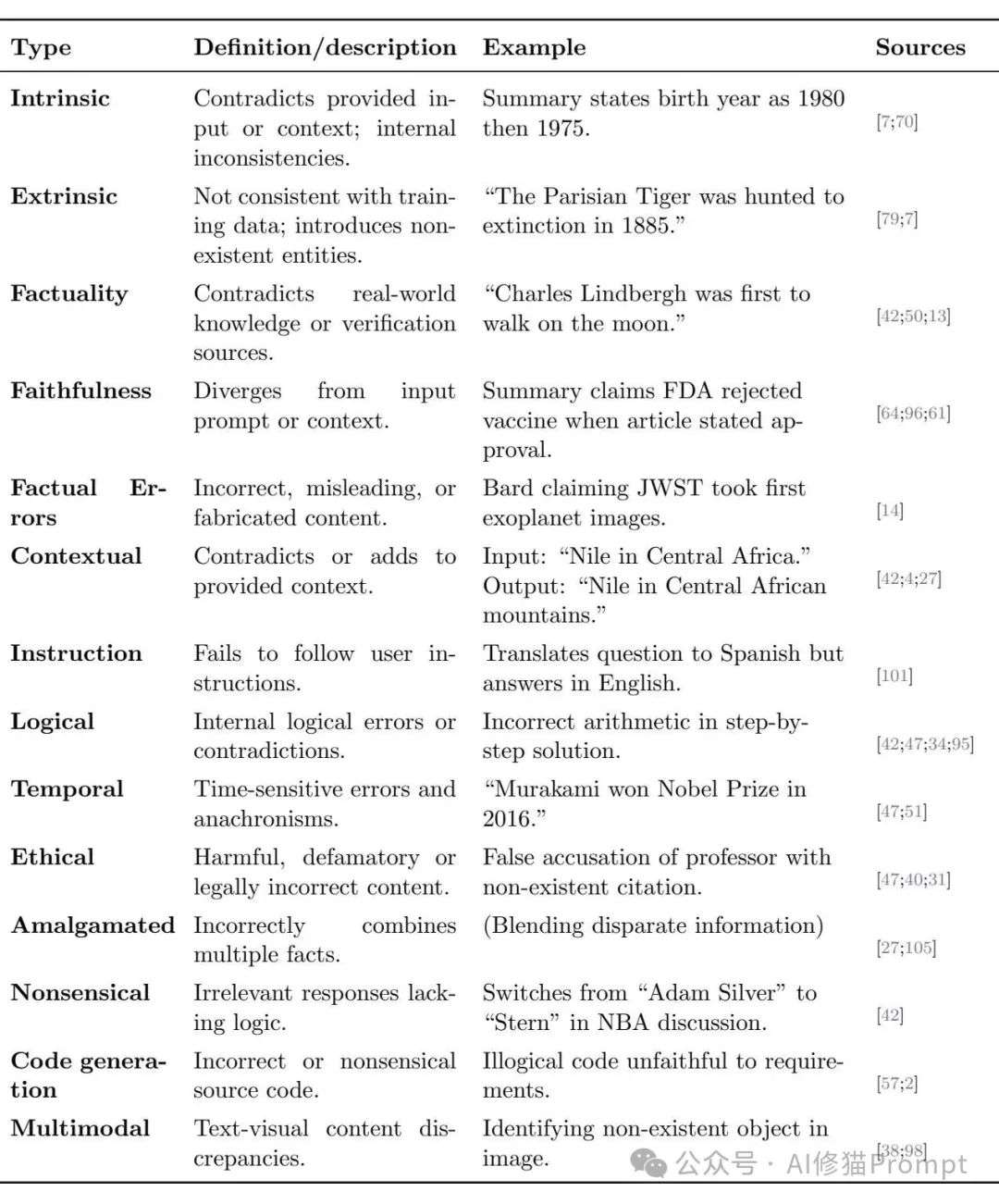
LLM幻觉的综合分类法
除了上述分类,论文还列举了大量真实世界中的幻觉案例,
那模型为什么会这样呢?最核心的原因,其实藏在它的工作原理里,自回归(Auto-regressive)。LLM的本质工作不是“理解并回答”,而是“预测下一个最可能的词”,它的第一目标永远是让句子读起来通顺、连贯,符合它在海量数据里学到的语言模式。至于这个句子是不是符合事实……那只是一个次要的、甚至是偶然达成的目标。
除此之外,研究者还总结了多个层面的原因:

LLM幻觉的根本原因
既然我们理解了幻觉从定义到原因的全貌,那么一个非常实际的问题就摆在面前:在我的产品里,如何科学地衡量幻觉的严重程度?研究者们同样关注这个问题,并发展出了一系列评估基准和量化指标,这为我们提供了评估自家系统幻觉水平的武器。
您可以把这些基准看作是精心设计的“考卷”,专门用来检测模型在特定方面的幻觉倾向。
如果说基准是“考卷”,那指标就是“评分标准”,它们试图用一个分数来量化幻觉的程度。
除了使用静态的基准测试,了解当前各大顶尖模型在真实世界中的幻觉表现也同样重要。论文的第9节为我们指明了几个可以持续关注的前沿阵地,它们就像LLM领域的“专业测评网站”。
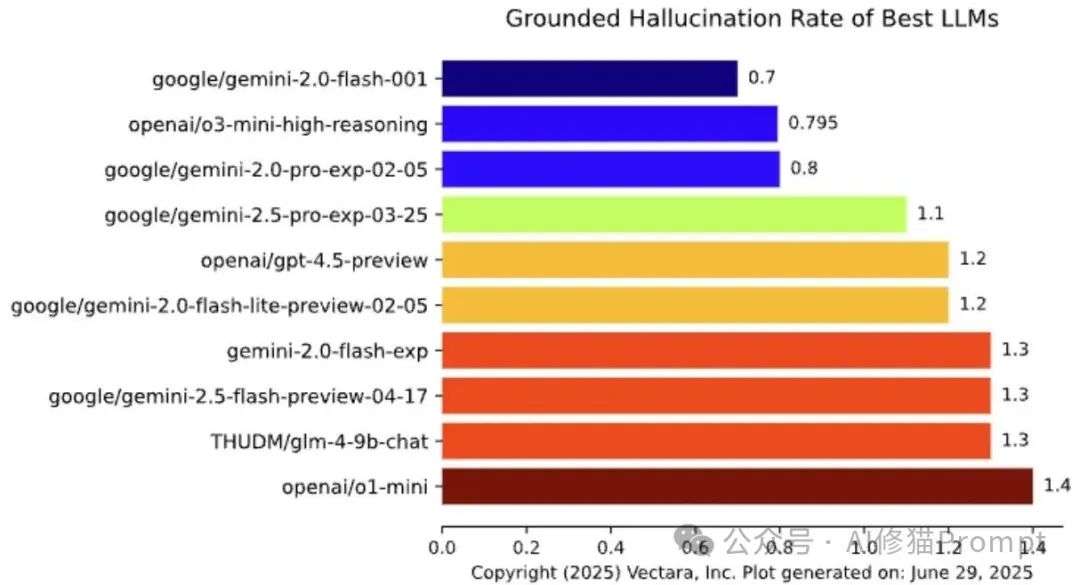
Vectara的Grounded Hallucination评估模型得分(越高越好)
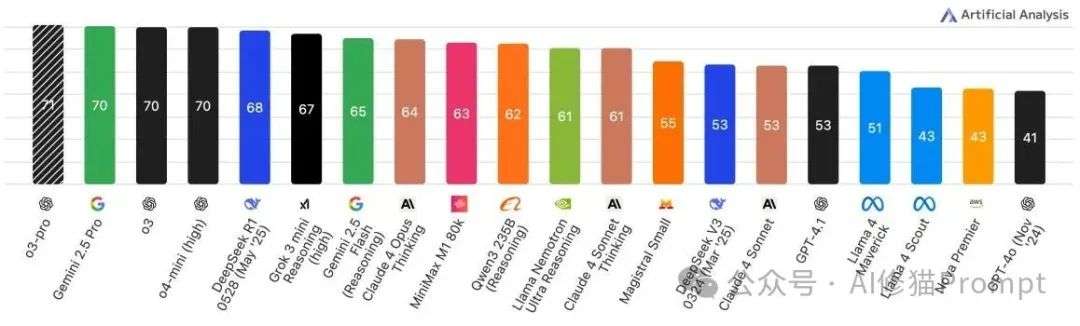
Artificial Analysis的AI智能指数(越高越好)
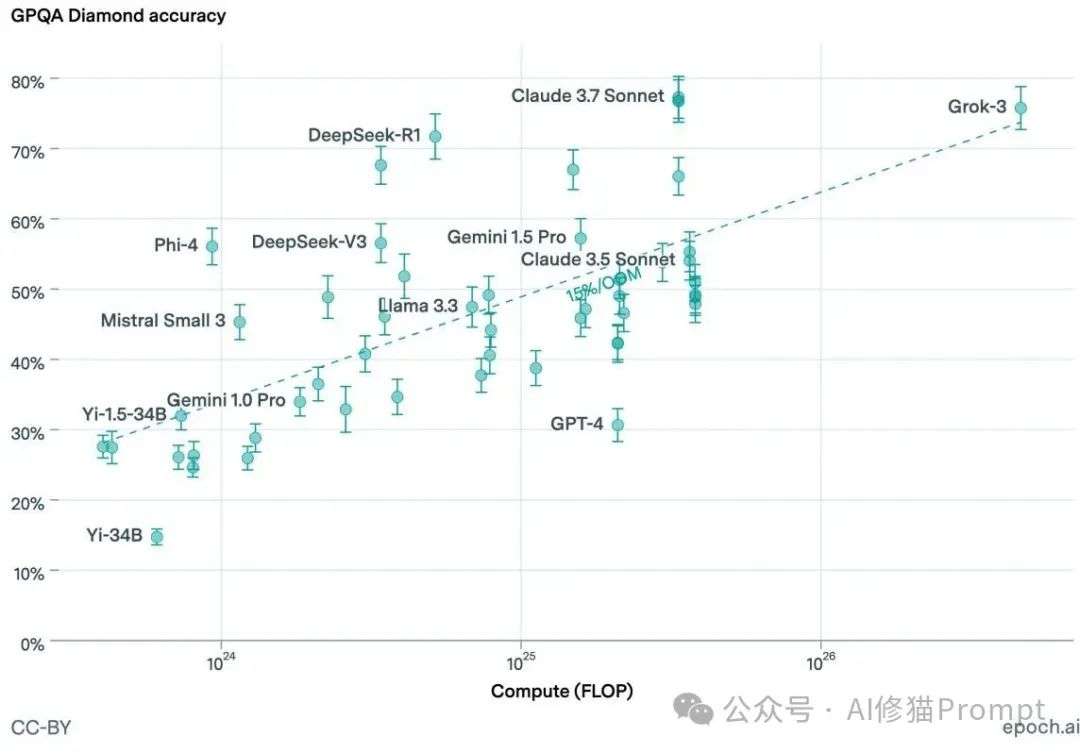
图9: 模型准确率与训练计算量的关系
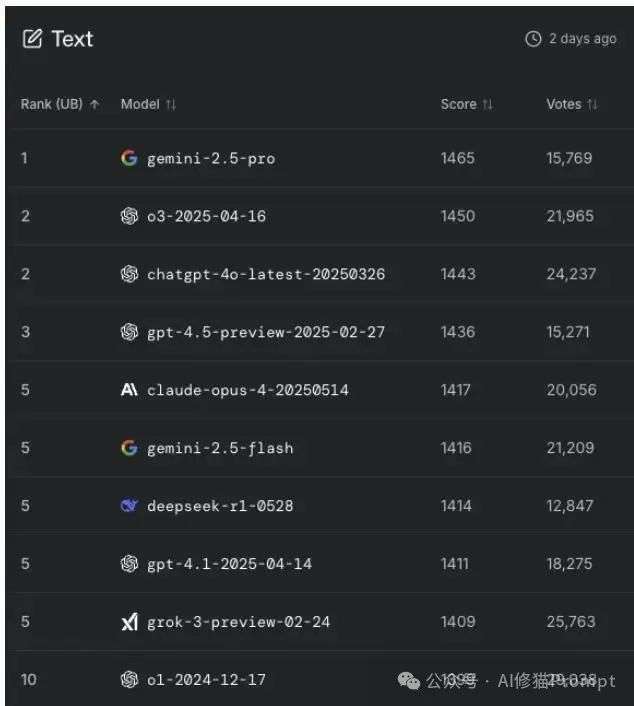
LM Arena文本生成模型排行榜
研究者们总结了目前最有效的几套“组合拳”,思路核心是从“试图让模型变完美”转向“为不完美的模型建立安全护栏”。
最后,研究者发现,幻觉之所以危险,一半“功劳”要归于模型,另一半则要归于我们自己。因为模型的回答通常语法完美、语气自信,我们的大脑会下意识地认为它很可信,这就是所谓的自动化偏见。更要命的是,如果模型说的恰好符合我们的猜想,确认偏见会让我们毫不犹豫地接受它的答案,哪怕它是个彻头彻尾的幻觉。
文章来自于微信公众号“AI修猫Prompt”。


【开源免费】DeepBI是一款AI原生的数据分析平台。DeepBI充分利用大语言模型的能力来探索、查询、可视化和共享来自任何数据源的数据。用户可以使用DeepBI洞察数据并做出数据驱动的决策。
项目地址:https://github.com/DeepInsight-AI/DeepBI?tab=readme-ov-file
本地安装:https://www.deepbi.com/
【开源免费】airda(Air Data Agent)是面向数据分析的AI智能体,能够理解数据开发和数据分析需求、根据用户需要让数据可视化。
项目地址:https://github.com/hitsz-ids/airda
【开源免费】FASTGPT是基于LLM的知识库开源项目,提供开箱即用的数据处理、模型调用等能力。整体功能和“Dify”“RAGFlow”项目类似。很多接入微信,飞书的AI项目都基于该项目二次开发。
项目地址:https://github.com/labring/FastGPT
【开源免费】graphrag是微软推出的RAG项目,与传统的通过 RAG 方法使用向量相似性作为搜索技术不同,GraphRAG是使用知识图谱在推理复杂信息时大幅提高问答性能。
项目地址:https://github.com/microsoft/graphrag
【开源免费】Dify是最早一批实现RAG,Agent,模型管理等一站式AI开发的工具平台,并且项目方一直持续维护。其中在任务编排方面相对领先对手,可以帮助研发实现像字节扣子那样的功能。
项目地址:https://github.com/langgenius/dify
【开源免费】RAGFlow是和Dify类似的开源项目,该项目在大文件解析方面做的更出色,拓展编排方面相对弱一些。
项目地址:https://github.com/infiniflow/ragflow/tree/main
【开源免费】phidata是一个可以实现将数据转化成向量存储,并通过AI实现RAG功能的项目
项目地址:https://github.com/phidatahq/phidata
【开源免费】TaskingAI 是一个提供RAG,Agent,大模型管理等AI项目开发的工具平台,比LangChain更强大的中间件AI平台工具。
项目地址:https://github.com/TaskingAI/TaskingAI
【开源免费】MindSearch是一个模仿人类思考方式的AI搜索引擎框架,其性能可与 Perplexity和ChatGPT-Web相媲美。
项目地址:https://github.com/InternLM/MindSearch
在线使用:https://mindsearch.openxlab.org.cn/
【开源免费】Morphic是一个由AI驱动的搜索引擎。该项目开源免费,搜索结果包含文本,图片,视频等各种AI搜索所需要的必备功能。相对于其他开源AI搜索项目,测试搜索结果最好。
项目地址:https://github.com/miurla/morphic/tree/main
在线使用:https://www.morphic.sh/
【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0
