
IBM发布LLM工具调用判断器ToolRM,工具调用准确率提高25%
IBM发布LLM工具调用判断器ToolRM,工具调用准确率提高25%Tool-Calling作为Agent的核心模块,智能体的双手,这项关键能力允许 LLM 调用外部函数,例如应用程序接口(APIs)、数据库、计算器和搜索引擎,决定了AI Agent的可执行边界。
来自主题: AI技术研报
9128 点击 2025-09-22 10:34
 搜索
搜索
Tool-Calling作为Agent的核心模块,智能体的双手,这项关键能力允许 LLM 调用外部函数,例如应用程序接口(APIs)、数据库、计算器和搜索引擎,决定了AI Agent的可执行边界。

近年来,大语言模型(LLMs)在复杂推理任务上的能力突飞猛进,这在很大程度上得益于深度思考的策略,即通过增加测试时(test-time)的计算量,让模型生成更长的思维链(Chain-of-Thought)。
来自MIT Improbable AI Lab的研究者们最近发表了一篇题为《RL's Razor: Why Online Reinforcement Learning Forgets Less》的论文,系统性地回答了这个问题,他们不仅通过大量实验证实了这一现象,更进一步提出了一个简洁而深刻的解释,并将其命名为 “RL's Razor”(RL的剃刀)。

DeepSeek荣登Nature封面,实至名归!今年1月,梁文锋带队R1新作,开创了AI推理新范式——纯粹RL就能激发LLM无限推理能力。Nature还特发一篇评论文章,对其大加赞赏。

等了一百多天,悬念终于揭晓。 9 月 13 日上午,蚂蚁集团开源团队(「开源技术增长」)携《 2025 大模型开源开发生态全景图 》2.0 版,亮相上海外滩大会。

人类的大脑,会在梦里筛选记忆。如今,AI也开始学会在「睡眠」中整理、保存,甚至遗忘。Bilt部署数百万智能体,让科幻小说里的设问——「仿生人会梦见电子羊吗?」——逐步成真。那么,当AI也能选择忘记时,它会变得更像人,还是更陌生?

随着Agent的爆发,大型语言模型(LLM)的应用不再局限于生成日常对话,而是越来越多地被要求输出像JSON或XML这样的结构化数据。这种结构化输出对于确保安全性、与其他软件系统互操作以及执行下游自动化任务至关重要。

诺奖得主哈萨比斯直击AI痛点:当前LLM远非博士级智能,仅在特定领域闪光,却缺乏全面性和一致性。真正的AGI,还需1-2项关键突破,等待有5-10年。
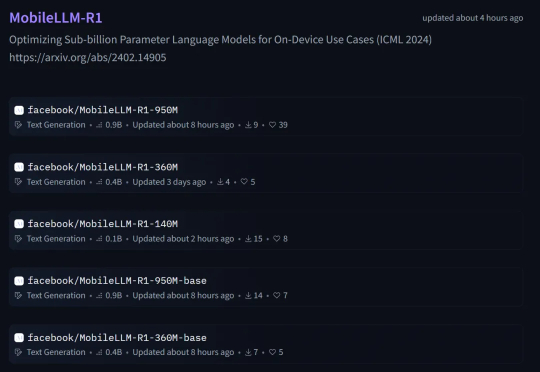
本周五,Meta AI 团队正式发布了 MobileLLM-R1。 这是 MobileLLM 的全新高效推理模型系列,包含两类模型:基础模型 MobileLLM-R1-140M-base、MobileLLM-R1-360M-base、MobileLLM-R1-950M-base 和它们相应的最终模型版。
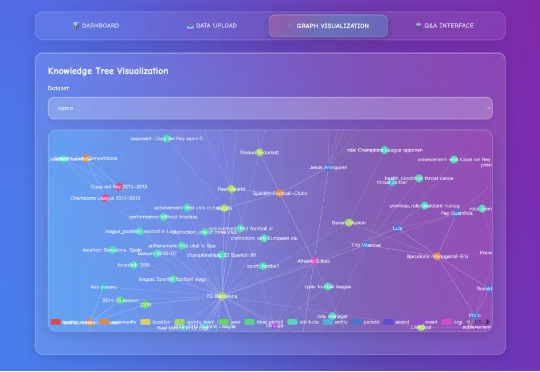
图检索增强生成(GraphRAG)已成为大模型解决复杂领域知识问答的重要解决方案之一。然而,当前学界和开源界的方案都面临着三大关键痛点: 开销巨大:通过 LLM 构建图谱及社区,Token 消耗大,耗