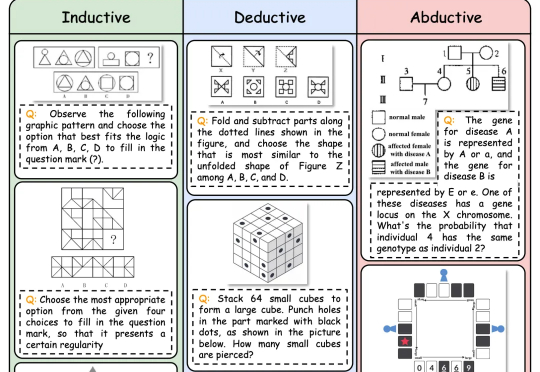
多模态推理新基准!最强Gemini 2.5 Pro仅得60分,复旦港中文上海AILab等出品
多模态推理新基准!最强Gemini 2.5 Pro仅得60分,复旦港中文上海AILab等出品逻辑推理是人类智能的核心能力,也是多模态大语言模型 (MLLMs) 的关键能力。随着DeepSeek-R1等具备强大推理能力的LLM的出现,研究人员开始探索如何将推理能力引入多模态大模型(MLLMs)
来自主题: AI技术研报
9973 点击 2025-06-07 10:35
 搜索
搜索
逻辑推理是人类智能的核心能力,也是多模态大语言模型 (MLLMs) 的关键能力。随着DeepSeek-R1等具备强大推理能力的LLM的出现,研究人员开始探索如何将推理能力引入多模态大模型(MLLMs)
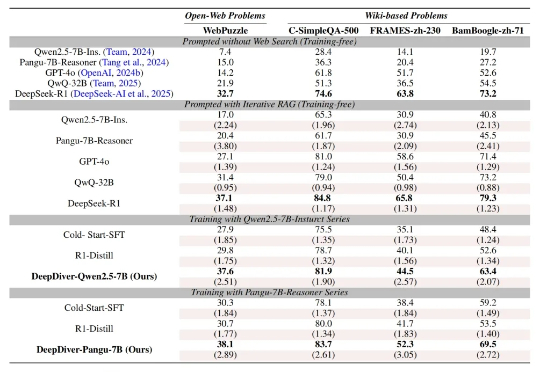
大型语言模型 (LLM) 的发展日新月异,但实时「内化」与时俱进的知识仍然是一项挑战。如何让模型在面对复杂的知识密集型问题时,能够自主决策获取外部知识的策略?

World Labs 是由著名 AI 专家、斯坦福大学教授李飞飞于 2024 年创办的初创公司,致力于开发具备“空间智能”的下一代 AI 系统。
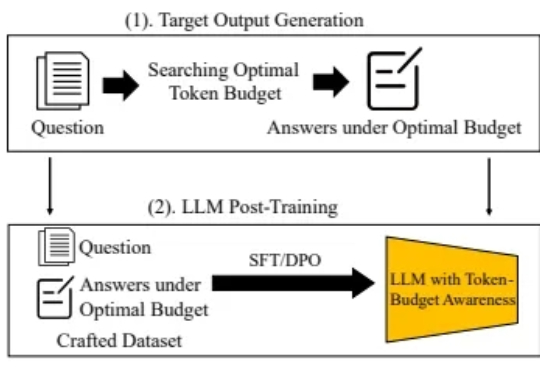
随着大型语言模型(LLM)技术的不断发展,Chain-of-Thought(CoT) 等推理增强方法被提出,以期提升模型在数学题解、逻辑问答等复杂任务中的表现,并通过引导模型逐步思考,有效提高了模型准确率。

LLM根本不会思考!LeCun团队新作直接戳破了大模型神话。最新实验揭示了,AI仅在粗糙分类任务表现优秀,却在精细任务中彻底失灵。

想象一下,你在一个陌生的房子里寻找合适的礼物盒包装泰迪熊,需要记住每个房间里的物品特征、位置关系,并根据反馈调整行动。

首个专为ALLMs(音频大语言模型)设计的多维度可信度评估基准来了。
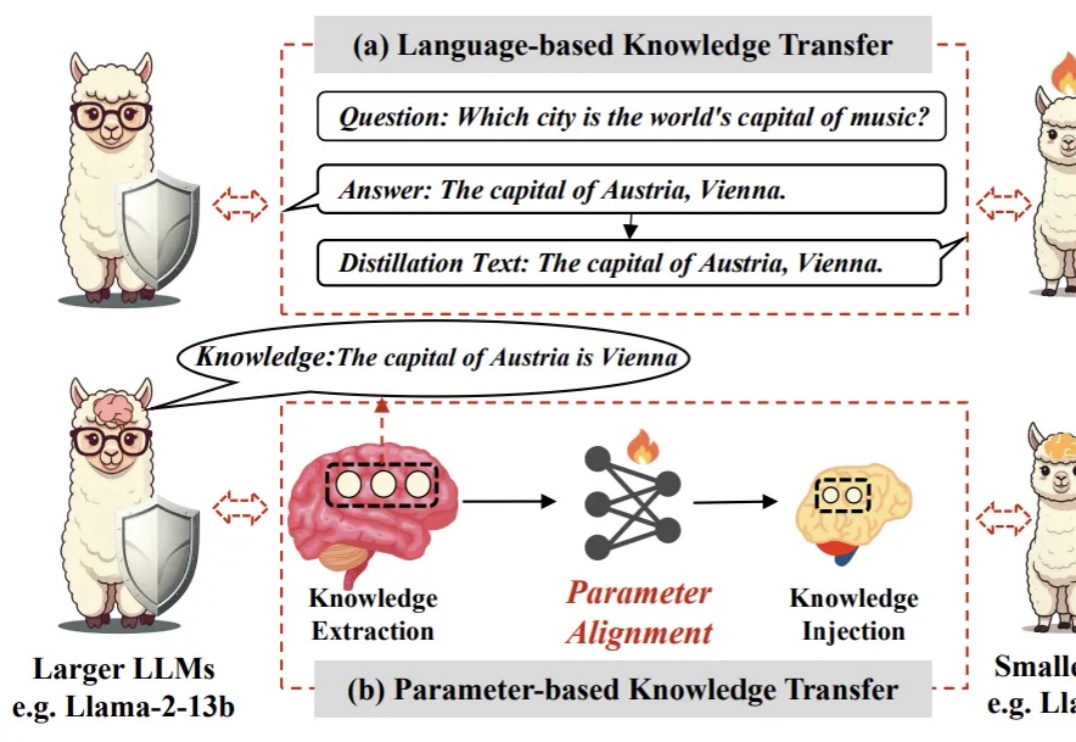
人类的思维是非透明的,没有继承的记忆,因此需要通过语言交流的环境来学习。人类的知识传递长期依赖符号语言:从文字、数学公式到编程代码,我们通过符号系统将知识编码、解码。但这种方式存在天然瓶颈,比如信息冗余、效率低下等。

大语言模型(LLMs)作为由复杂算法和海量数据驱动的产物,会不会“无意中”学会了某些类似人类进化出来的行为模式?这听起来或许有些大胆,但背后的推理其实并不难理解:
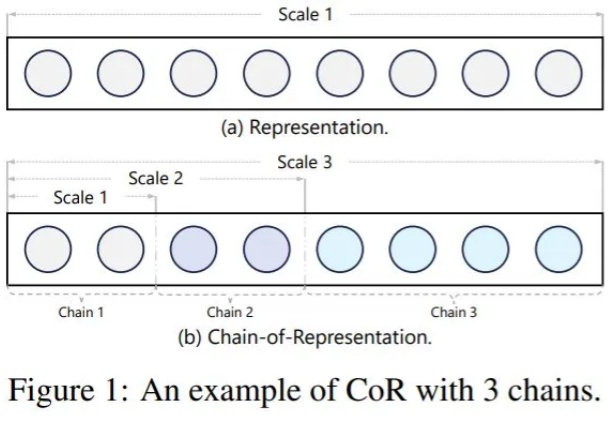
随着大语言模型 (LLM) 的出现,扩展 Transformer 架构已被视为彻底改变现有 AI 格局并在众多不同任务中取得最佳性能的有利途径。因此,无论是在工业界还是学术界,探索如何扩展 Transformer 模型日益成为一种趋势。