LSTM之父22年前构想将成真?一周内AI「自我进化」论文集中发布,新趋势涌现?
LSTM之父22年前构想将成真?一周内AI「自我进化」论文集中发布,新趋势涌现?在过去的一周,这一方向的进展尤其丰富。有人发现,几篇关于「让 LLM(或智能体)学会自我训练」的论文在 arXiv 上集中出现,其中甚至包括受「哥德尔机」构想启发而提出的「达尔文哥德尔机」。或许,AI 模型的自我进化能力正在加速提升。
来自主题: AI技术研报
9337 点击 2025-06-03 09:36
 搜索
搜索
在过去的一周,这一方向的进展尤其丰富。有人发现,几篇关于「让 LLM(或智能体)学会自我训练」的论文在 arXiv 上集中出现,其中甚至包括受「哥德尔机」构想启发而提出的「达尔文哥德尔机」。或许,AI 模型的自我进化能力正在加速提升。
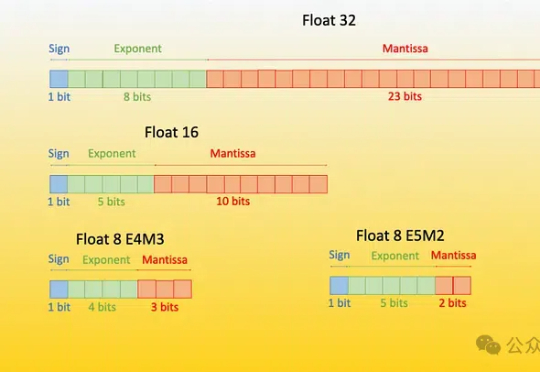
原生1bit大模型BitNet b1.58 2B4T再升级!微软公布BitNet v2,性能几乎0损失,而占用内存和计算成本显著降低。
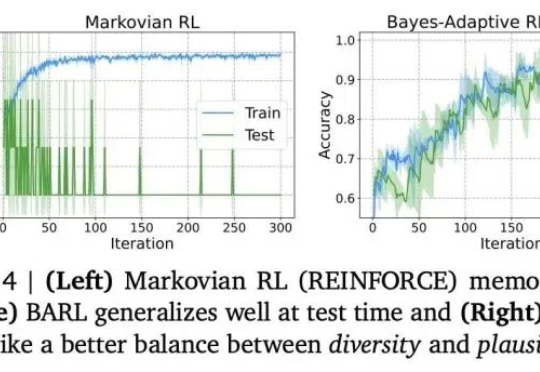
推理模型常常表现出类似自我反思的行为,但问题是——这些行为是否真的能有效探索新策略呢?

近年来,大语言模型(LLMs)的能力突飞猛进,但随之而来的隐私风险也逐渐浮出水面。
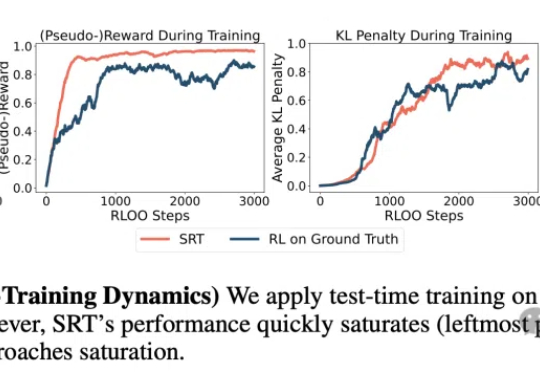
数据枯竭正成为AI发展的新瓶颈!CMU团队提出革命性方案SRT:让LLM实现无需人类标注的自我进化!SRT初期就能迭代提升数学与推理能力,甚至性能逼近传统强化学习的效果,揭示了其颠覆性潜力。

Claude团队来搞开源了——推出“电路追踪”(circuit tracing)工具,可以帮大伙儿读懂大模型的“脑回路”,追踪其思维过程。该工具的核心在于生成归因图(attribution graphs),其作用类似于大脑的神经网络示意图,通过可视化模型内部超节点及其连接关系,呈现LLM处理信息的路径。

多模态大模型(MLLM)在静态图像上已经展现出卓越的 OCR 能力,能准确识别和理解图像中的文字内容。MME-VideoOCR 致力于系统评估并推动MLLM在视频OCR中的感知、理解和推理能力。

斯坦福Hazy实验室推出新一代低延迟推理引擎「Megakernel」,将Llama-1B模型前向传播完整融合进单一GPU内核,实现推理时间低于1毫秒。在B200上每次推理仅需680微秒,比vLLM快3.5倍。

近日,NVIDIA 联合香港大学、MIT 等机构重磅推出 Fast-dLLM,以无需训练的即插即用加速方案,实现了推理速度的突破!通过创新的技术组合,在不依赖重新训练模型的前提下,该工作为扩散模型的推理加速带来了突破性进展。本文将结合具体技术细节与实验数据,解析其核心优势。

EfficientLLM项目聚焦LLM效率,提出三轴分类法和六大指标,实验包揽全架构、多模态、微调技术,可为研究人员提供效率与性能平衡的参考。