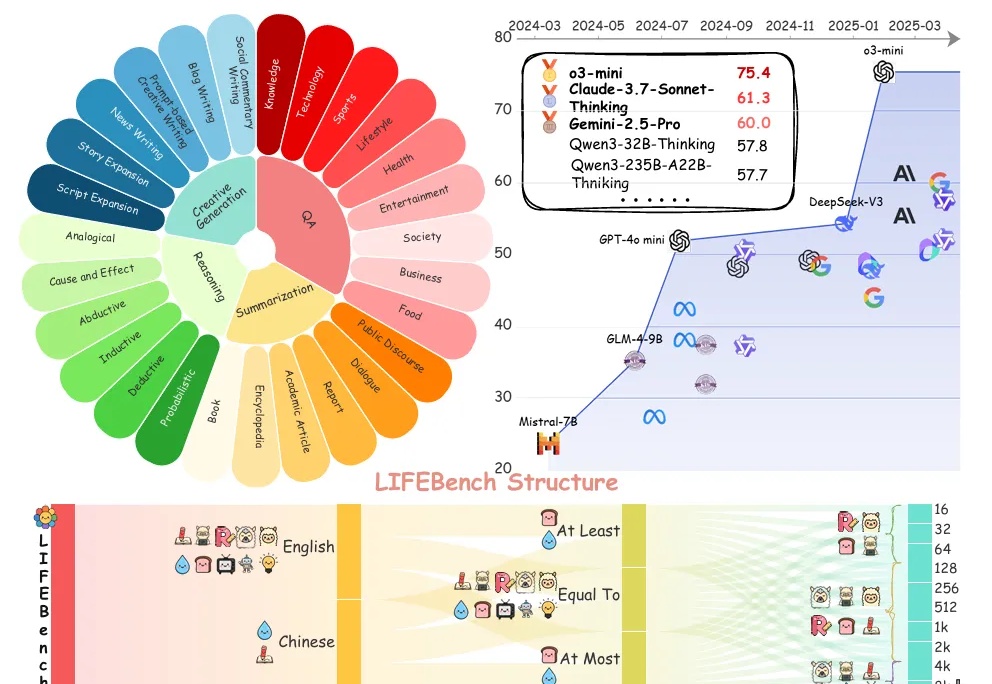
基准测试揭秘大模型“字数危机”:26个模型长文本生成普遍拉胯,最大输出长度过度宣传
基准测试揭秘大模型“字数危机”:26个模型长文本生成普遍拉胯,最大输出长度过度宣传你是否曾对大语言模型(LLMs)下达过明确的“长度指令”?
来自主题: AI技术研报
10078 点击 2025-05-29 15:12
 搜索
搜索
你是否曾对大语言模型(LLMs)下达过明确的“长度指令”?
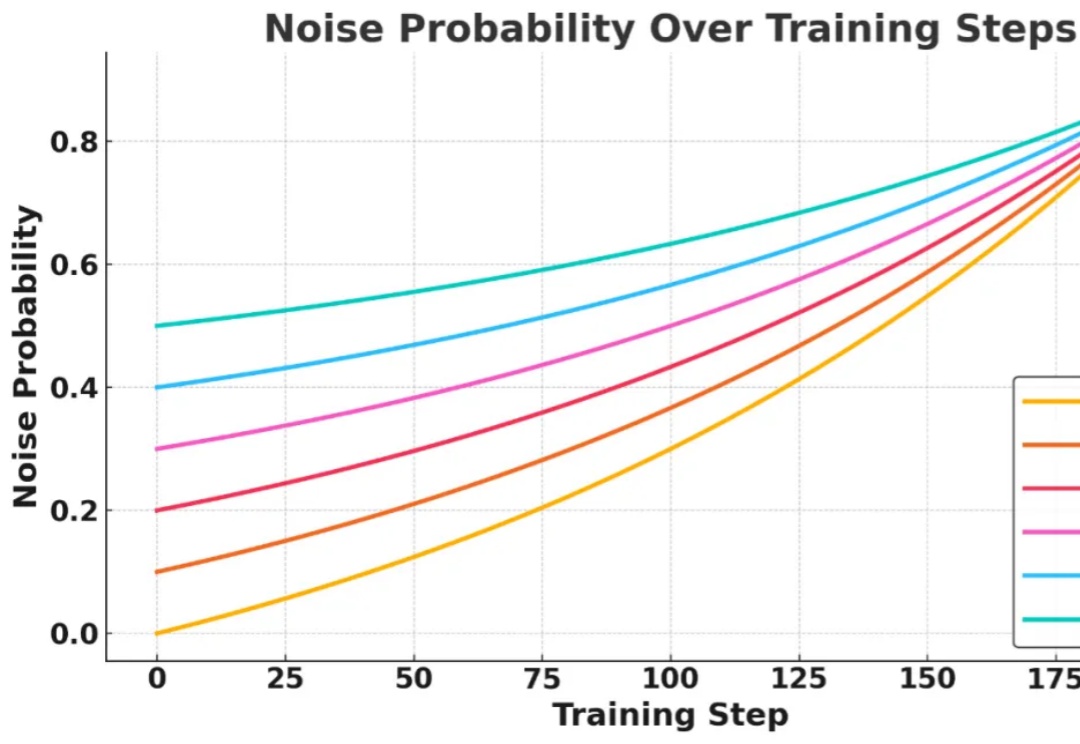
信息检索能力对提升大语言模型 (LLMs) 的推理表现至关重要,近期研究尝试引入强化学习 (RL) 框架激活 LLMs 主动搜集信息的能力,但现有方法在训练过程中面临两大核心挑战:
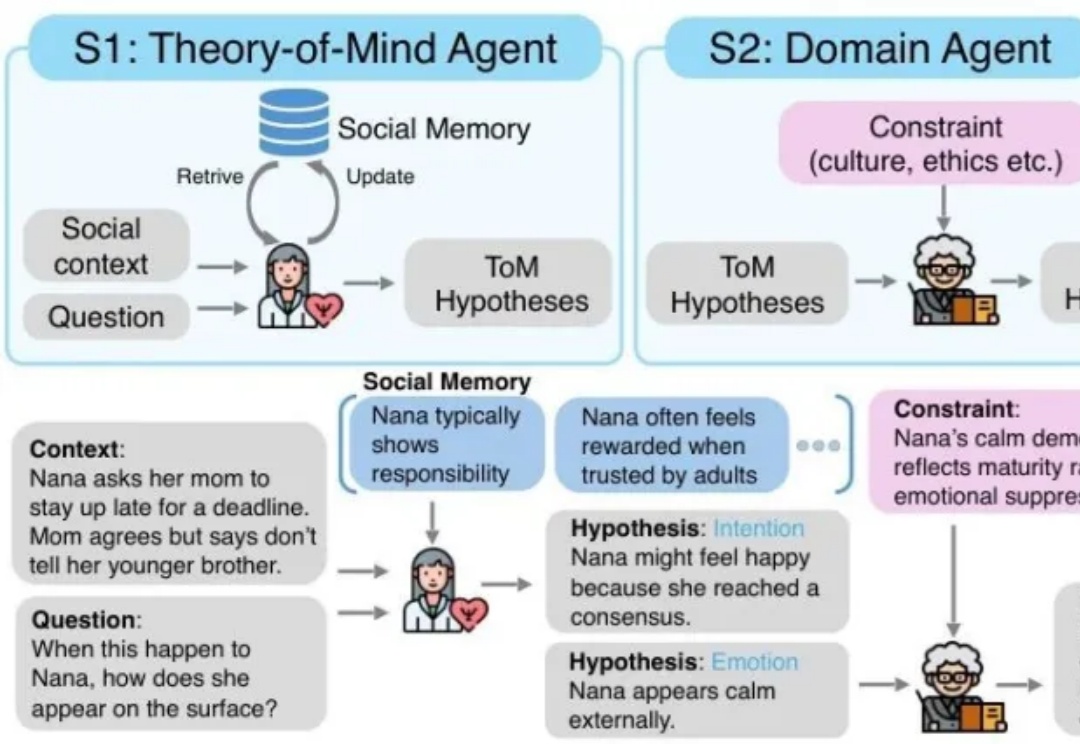
MetaMind是一个多智能体框架,专门解决大语言模型在社交认知方面的根本缺陷。传统的 LLM 常常难以应对现实世界中人际沟通中固有的模糊性和间接性,无法理解未说出口的意图、隐含的情绪或文化敏感线索。MetaMind首次使LLMs在关键心理理论(ToM)任务上达到人类水平表现。

来自华盛顿大学、AI2、UC伯克利研究团队证实,「伪奖励」(Spurious Rewards)也能带来LLM推理能力提升的惊喜。
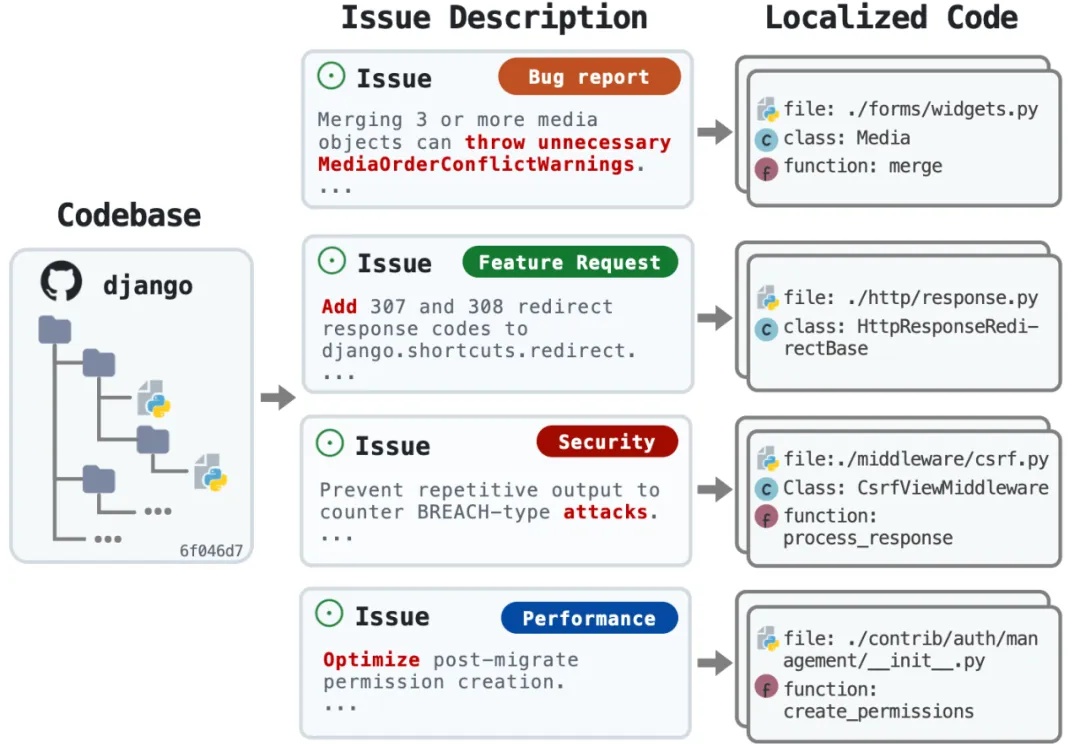
又是一个让程序员狂欢的研究!来自 OpenHands、耶鲁、南加大和斯坦福的研究团队刚刚发布了 LocAgent—— 一个专门用于代码定位的图索引 LLM Agent 框架,直接把代码定位准确率拉到了 92.7% 的新高度。该研究已被 ACL 2025 录用。
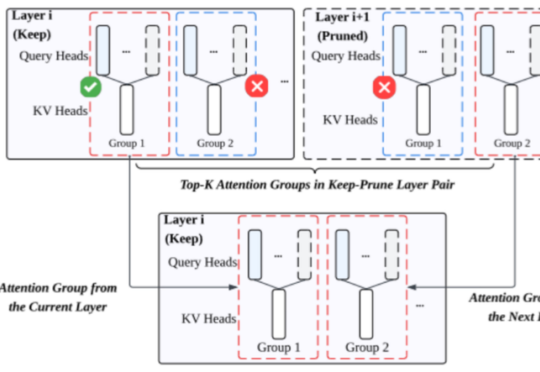
LLM发展到今天,下一步该往哪个方向探索?
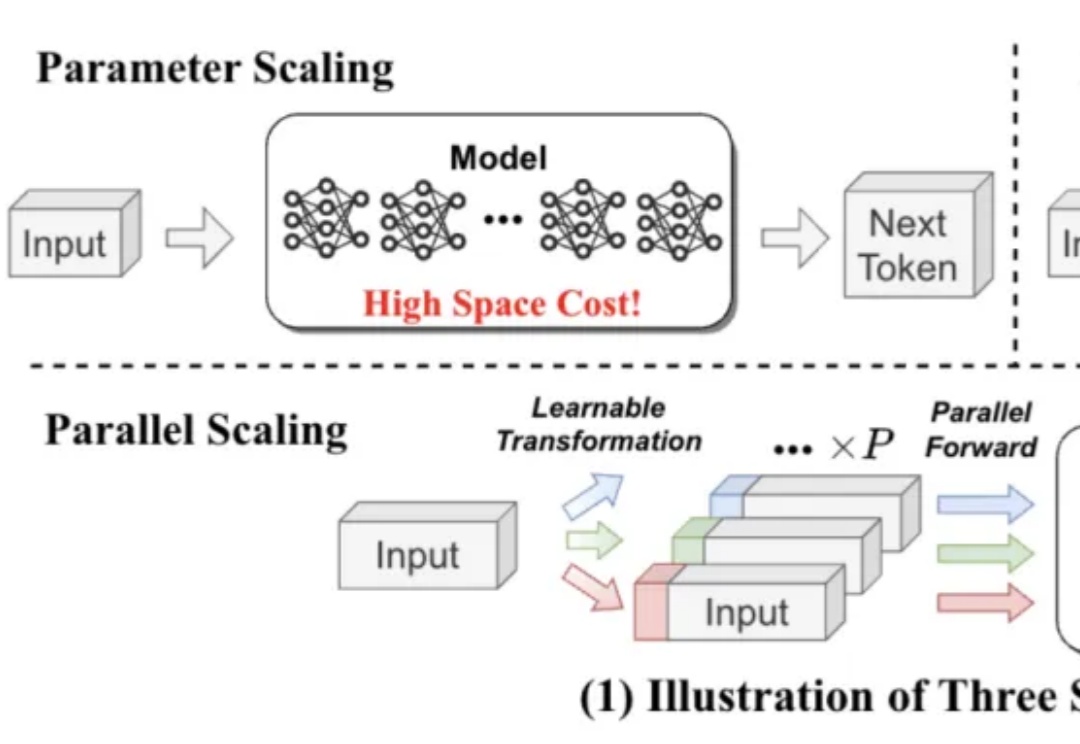
既能提升模型能力,又不显著增加内存和时间成本,LLM第三种Scaling Law被提出了。

Meta推出KernelLLM,这个基于Llama 3.1微调的8B模型,竟能将PyTorch代码自动转换为高效Triton GPU内核。实测数据显示,它的单次推理性能超越GPT-4o和DeepSeek V3,多次生成时得分飙升。
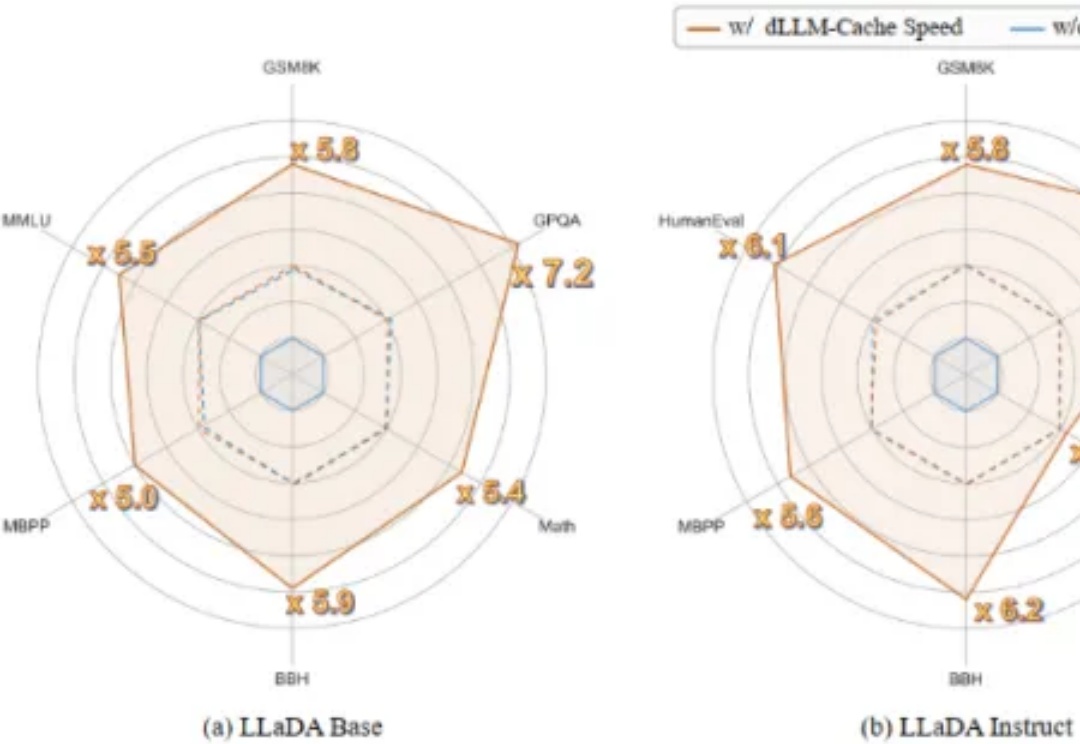
首个用于加速扩散式大语言模型(diffusion-based Large Language Models, 简称 dLLMs)推理过程的免训练方法。
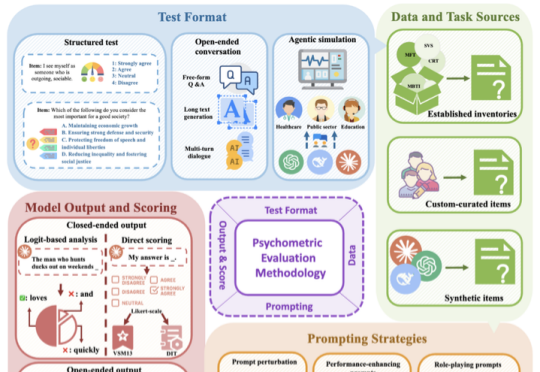
随着大语言模型(LLM)能力的快速迭代,传统评估方法已难以满足需求。如何科学评估 LLM 的「心智」特征,例如价值观、性格和社交智能?如何建立更全面、更可靠的 AI 评估体系?北京大学宋国杰教授团队最新综述论文(共 63 页,包含 500 篇引文),首次尝试系统性梳理答案。