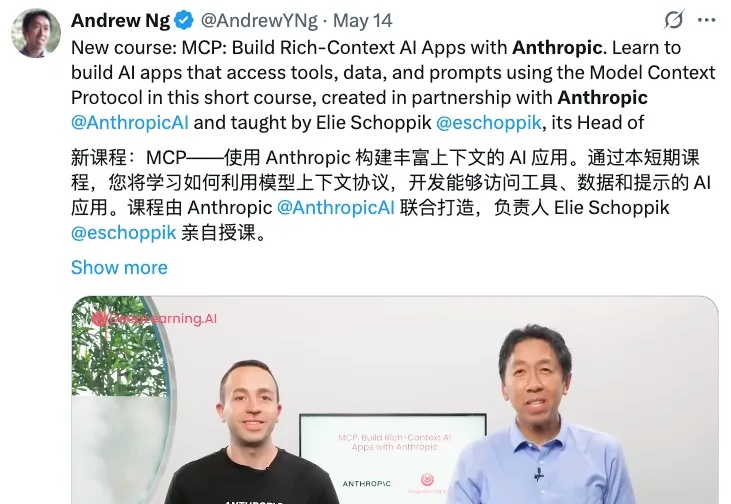
不用等了!吴恩达MCP课程来了!
不用等了!吴恩达MCP课程来了!MCP 是一种开放的技术协议,旨在标准化大型语言模型(LLM)与外部工具和服务的交互方式。你可以把 MCP 理解成像是一个 AI 世界的通用翻译官,让 AI 模型能够与各种各样的外部工具"对话"。
来自主题: AI资讯
8718 点击 2025-05-20 09:44
 搜索
搜索
MCP 是一种开放的技术协议,旨在标准化大型语言模型(LLM)与外部工具和服务的交互方式。你可以把 MCP 理解成像是一个 AI 世界的通用翻译官,让 AI 模型能够与各种各样的外部工具"对话"。

AI能写论文、画图、考高分,但连「看表读时间」「今天是星期几」都错得离谱?最新研究揭示了背后惊人的认知缺陷,提醒我们:AI很强大,但精确推理还离不开人类。
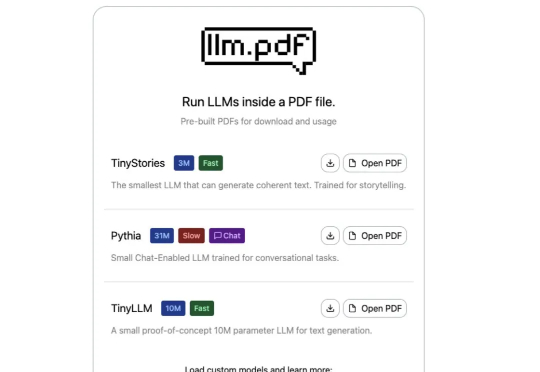
你以为PDF只是用来阅读文档的?这次它彻底颠覆了你的想象!极客Aiden Bai最新整活——直接把大语言模型(LLM)塞进PDF里,打开文件就能让AI讲故事、陪你聊天!更夸张的是,连Linux系统都能在PDF里运行。
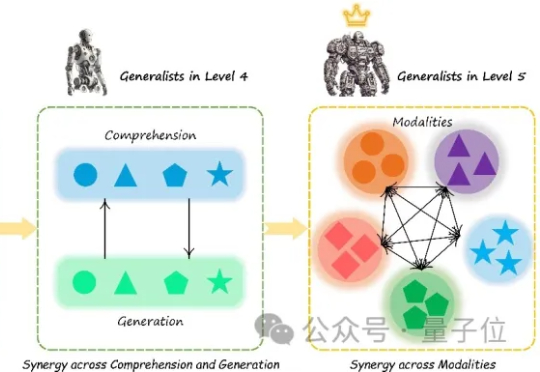
多模态大模型(Multimodal Large Language Models, MLLM)正迅速崛起,从只能理解单一模态,到如今可以同时理解和生成图像、文本、音频甚至视频等多种模态。正因如此,在AI竞赛进入“下半场”之际(由最近的OpenAI研究员姚顺雨所引发的共识观点),设计科学的评估机制俨然成为决定胜负的核心关键。

最近,Meta 公司首席 AI 科学家、图灵奖得主 LeCun 转发了他在纽约大学的同事 Kyunghyun Cho 的一篇帖子:内容是关于这位教授 2025 学年机器学习研究生课程的教学大纲和讲义。
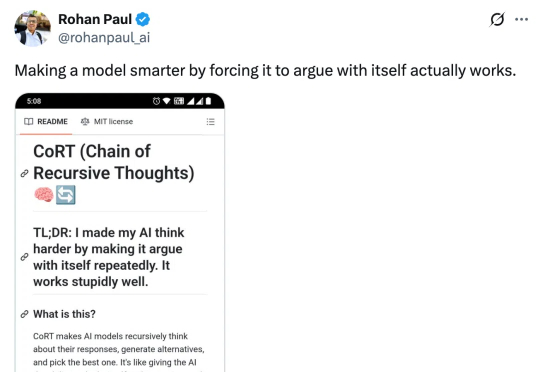
递归思考 + 自我批判,CoRT 能带来 LLM 推理力的飞跃吗?
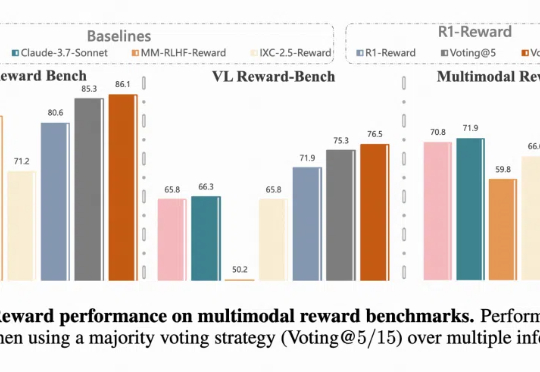
多模态奖励模型(MRMs)在提升多模态大语言模型(MLLMs)的表现中起着至关重要的作用,在训练阶段可以提供稳定的 reward,评估阶段可以选择更好的 sample 结果,甚至单独作为 evaluator。
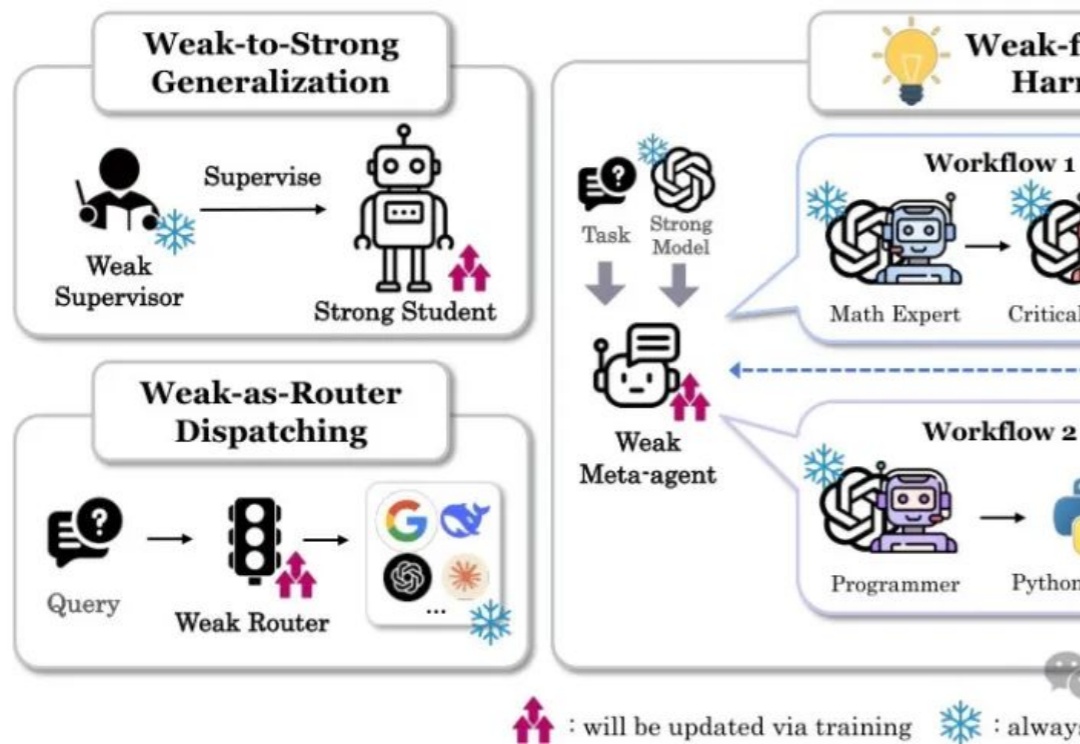
本文详细介绍了斯坦福大学最新提出的"以弱驭强"(W4S)范式,这一创新方法通过训练轻量级的弱模型来优化强大语言模型的工作流。核心亮点包括:

字节Seed首次开源代码模型!Seed-Coder,8B规模,超越Qwen3,拿下多个SOTA。它证明“只需极少人工参与,LLM就能自行管理代码训练数据”。通过自身生成和筛选高质量训练数据,可大幅提升模型代码生成能力。
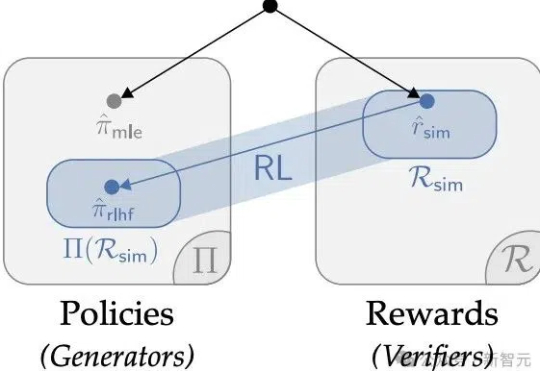
华人学者参与的一项研究,重新确立了强化学习在LLM微调的价值,深度解释了AI训练「两阶段强化学习」的原因。某种意义上,他们的论文说明RL微调就是统计。