大语言模型变身软体机器人设计「自然选择器」,GPT、Gemini、Grok争做最佳
大语言模型变身软体机器人设计「自然选择器」,GPT、Gemini、Grok争做最佳大型语言模型 (LLM) 在软体机器人设计领域展现出了令人振奋的应用潜力。
来自主题: AI技术研报
9535 点击 2025-04-06 16:27
 搜索
搜索
大型语言模型 (LLM) 在软体机器人设计领域展现出了令人振奋的应用潜力。

在人工智能飞速发展的今天,LLM 的能力令人叹为观止,但其局限性也日益凸显 —— 它们往往被困于训练数据的「孤岛」,无法直接触及实时信息或外部工具。

最新研究发现,LLM在面对人格测试时,会像人一样「塑造形象」,提升外向性和宜人性得分。AI的讨好倾向,可能导致错误的回复,需要引起警惕。
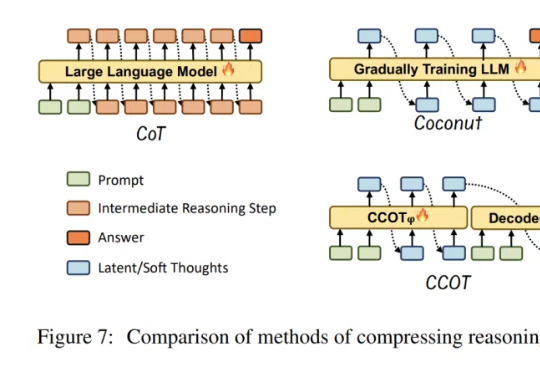
大模型虽然推理能力增强,却常常「想太多」,回答简单问题也冗长复杂。Rice大学的华人研究者提出高效推理概念,探究了如何帮助LLM告别「过度思考」,提升推理效率。

当大多数AI Agent仍在挣扎于结构化推理能力不足的困境时,本文带来了一个来自认知科学领域的突破性解决方案。

简单的任务,传统的Transformer却错误率极高。Meta FAIR团队重磅推出多token注意力机制(MTA),精准捕捉复杂信息,带来模型性能飞升!
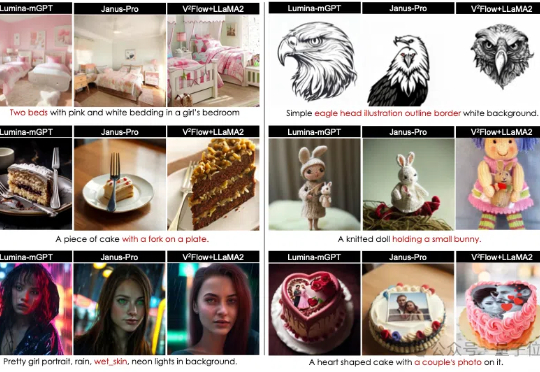
视觉Token可以与LLMs词表无缝对齐了!
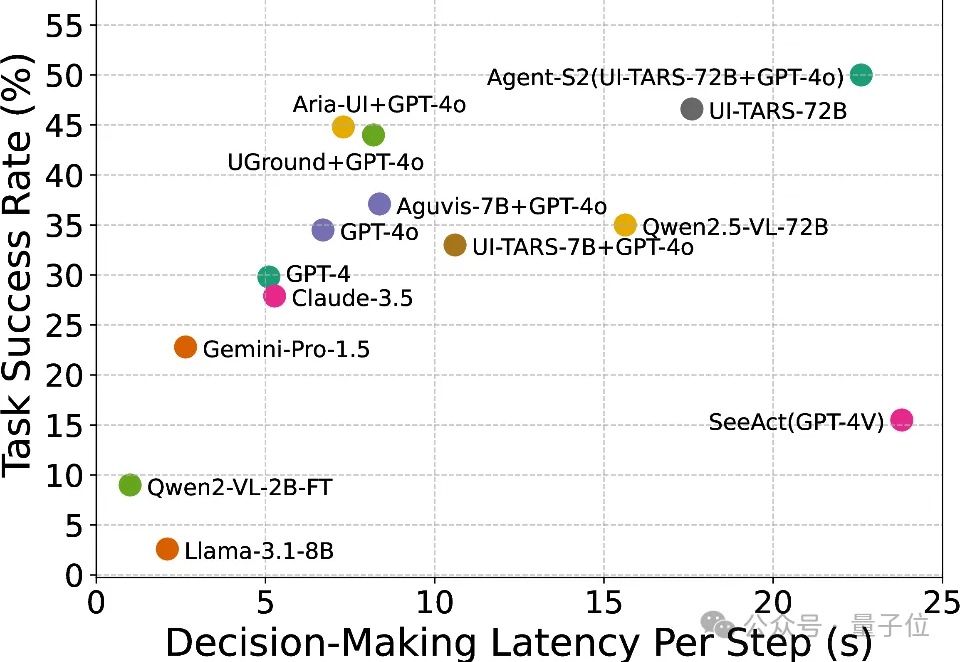
随着人工智能和大语言模型(LLMs)的不断突破,如何将其优势赋能于现实世界中可实际部署的高效工具,成为了业界关注的焦点。

在三方图灵测试中,UCSD的研究人员评估了当前的AI模型,证明LLM已通过图灵测试。在测试中,同时与人及AI系统进行5分钟对话,然后判断哪位是「真人」。结果,AI竟然比「真人」还像人:

LLM正推动推荐系统革新,以用户表征为「软提示」的范式开辟了高效推荐新路径。在此趋势下,淘天团队发布了首个基于用户表征的个性化问答基准UQABench,系统评估了用户表征的提示效能。