
不要自回归!扩散模型作者创业,首个商业级扩散LLM来了,编程秒出结果
不要自回归!扩散模型作者创业,首个商业级扩散LLM来了,编程秒出结果当前的 AI 领域,可以说 Transformer 与扩散模型是最热门的模型架构。也因此,有不少研究团队都在尝试将这两种架构融合到一起,以两者之长探索新一代的模型范式,比如我们之前报道过的 LLaDA。不过,之前这些成果都还只是研究探索,并未真正实现大规模应用。
来自主题: AI技术研报
11863 点击 2025-02-27 14:40
 搜索
搜索
当前的 AI 领域,可以说 Transformer 与扩散模型是最热门的模型架构。也因此,有不少研究团队都在尝试将这两种架构融合到一起,以两者之长探索新一代的模型范式,比如我们之前报道过的 LLaDA。不过,之前这些成果都还只是研究探索,并未真正实现大规模应用。
尽管多模态大语言模型(MLLMs)取得了显著的进展,但现有的先进模型仍然缺乏与人类偏好的充分对齐。这一差距的存在主要是因为现有的对齐研究多集中于某些特定领域(例如减少幻觉问题),是否与人类偏好对齐可以全面提升MLLM的各种能力仍是一个未知数。

本文深入解析一项开创性研究——"Logic-RL: Unleashing LLM Reasoning with Rule-Based Reinforcement Learning",该研究通过基于规则的强化学习技术显著提升了语言模型的推理能力。微软亚洲的研究团队受DeepSeek-R1成功经验的启发,利用结构化的逻辑谜题作为训练场,为模型创建了一个可以系统学习和改进推理技能的环境。
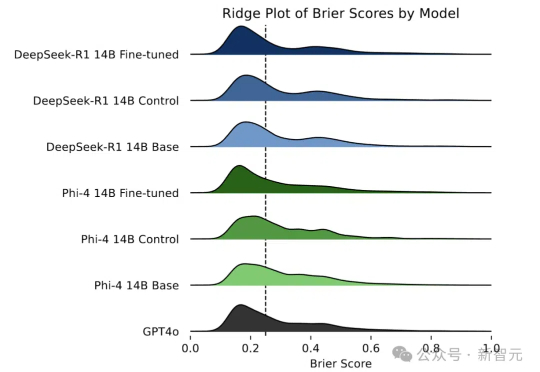
还在惊叹预言家的神奇?如今LLM也掌握了预测未来的「超能力」!研究人员通过自我博弈和直接偏好优化,让LLM摆脱人工数据依赖,大幅提升预测能力。

“放弃生成式模型,不研究LLM(大语言模型),我们没办法只通过文本训练让AI达到人类的智慧水平。”近日,Meta首席AI科学家杨立昆(Yann LeCun)在法国巴黎的2025年人工智能行动峰会上再一次炮轰了生成式AI。

我们现在使用 LLM 来处理所有的理解工作,并确保我们不会向用户发送任何生成文本,这样我们就可以完全自信地说,我们没有幻觉的风险,没有提示注入和劫持等风险。
现在写代码,最fashion的“姿势”应该是什么?答案或许就是:截图。商汤在今天GDC(全球开发者先锋大会)中办公小浣熊2.0最新升级的功能。
多位接近字节的人士对硅星人透露,字节的AI核心部门Seed正在快速调整定位和调兵遣将。刚刚从谷歌加入字节跳动的AI大牛、参与了Gemini开发的Google Fellow吴永辉博士,将成为Seed新的负责人,替换原LLM团队及Seed总负责人朱文佳,团队内部正在梳理调整汇报关系。
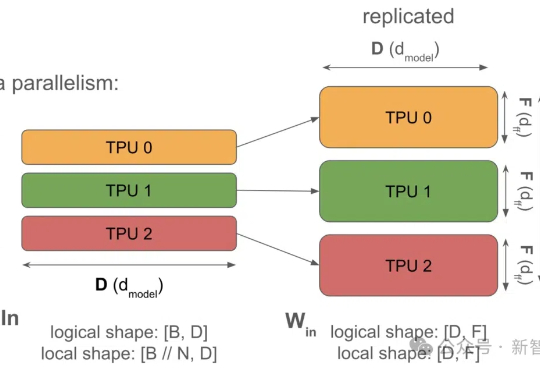
谷歌团队发布LLM硬核技术教科书,从「系统视图」揭秘LLM Scaling的神秘面纱。Jeff Dean强调书中藏着谷歌最强AI模型Gemini训练的更多信息。
最初,查询扩展是为那些靠关键词匹配来判断相关性的搜索系统设计的,比如 tf-idf 或其他稀疏向量方案。这类方法有些天然的缺陷:词语稍微变个形式,像 "ran" 和 "running",或者 "optimise" 和 "optimize",都会影响匹配结果。虽然可以用语言预处理来解决一部分问题,但远远不够。技术术语、同义词和相关词就更难处理了。