
物理直觉不再是人类专属?LeCun等新研究揭示AI可如何涌现出此能力
物理直觉不再是人类专属?LeCun等新研究揭示AI可如何涌现出此能力在当今的 AI 领域,图灵奖得主 Yann LeCun 算是一个另类。即便眼见着自回归 LLM 的能力越来越强大,能解决的任务也越来越多,他也依然坚持自己的看法:自回归 LLM 没有光明的未来。
来自主题: AI技术研报
8849 点击 2025-02-20 16:55
 搜索
搜索
在当今的 AI 领域,图灵奖得主 Yann LeCun 算是一个另类。即便眼见着自回归 LLM 的能力越来越强大,能解决的任务也越来越多,他也依然坚持自己的看法:自回归 LLM 没有光明的未来。
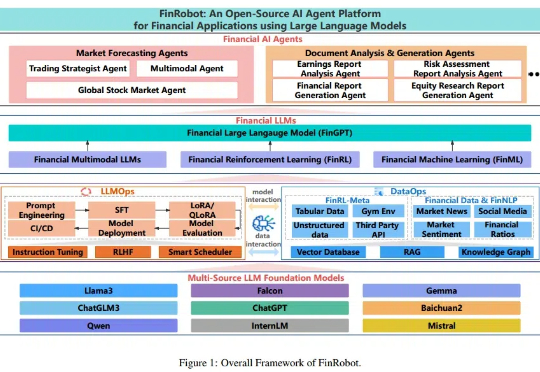
随着金融机构和专业人士越来越多地将大语言模型(LLMs)纳入其工作流程中,金融领域与人工智能社区之间依然存在显著障碍,包括专有数据和专业知识的壁垒。本文提出了 FinRobot,一种支持多个金融专业化人工智能智能体的新型开源 AI 智能体平台,每个代理均由 LLM 提供动力。
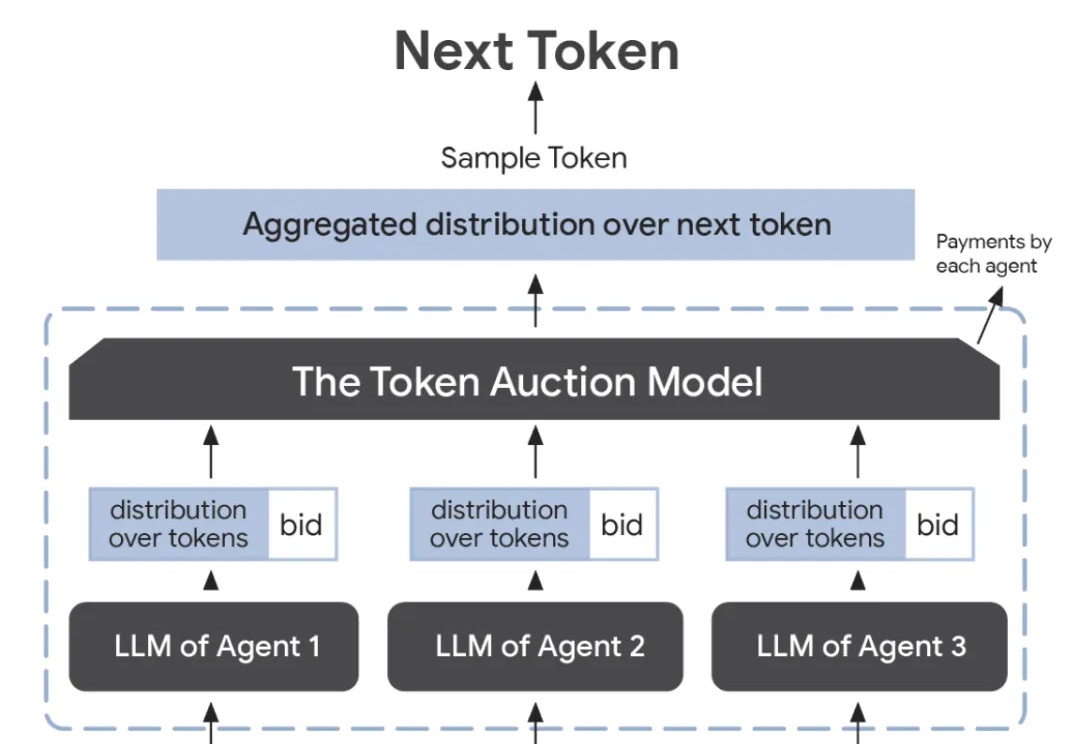
谷歌研究人员提出了一种创新的token拍卖模型,通过「竞拍」的方式,让智能体在文本生成过程中进行出价,确保最终输出能满足各方利益,实现最佳效果。这一机制优化了广告、内容创作等领域的协作。

DeepSeek团队最新力作一上线,就获得Ai2研究所大牛推荐,和DeepSeek铁粉们的热情研读!他们提出的CodeI/O全新方法,通过代码提取了LLM推理模式,在逻辑、数学等推理任务上得到显著改进。
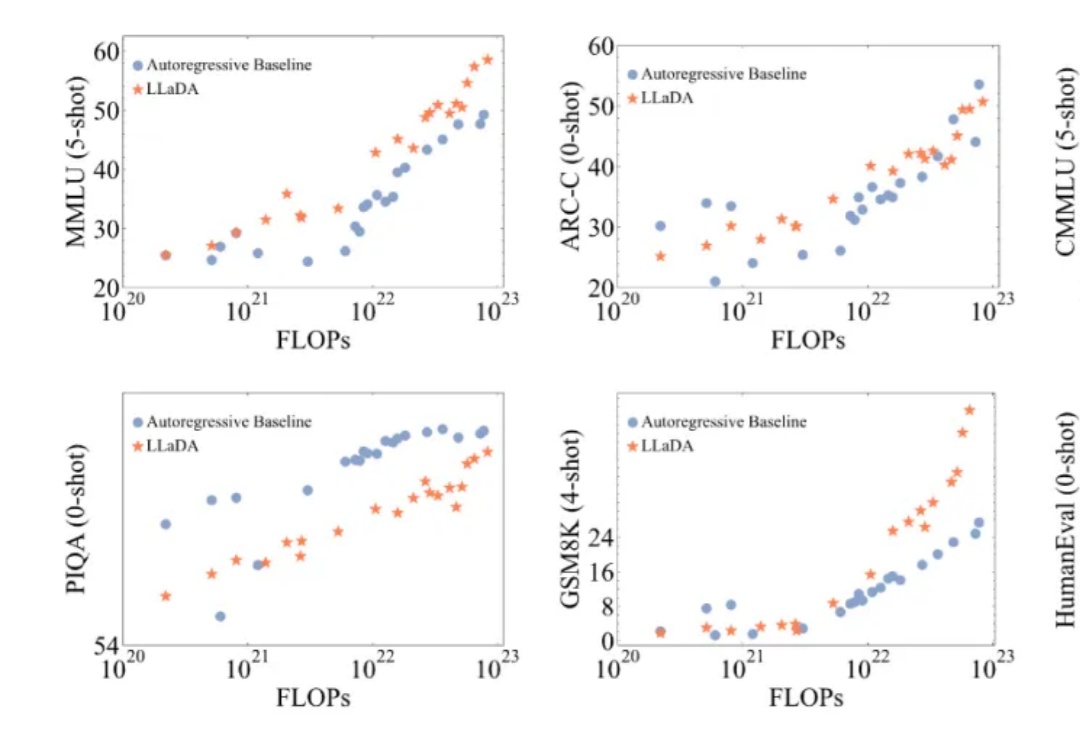
近年来,大语言模型(LLMs)取得了突破性进展,展现了诸如上下文学习、指令遵循、推理和多轮对话等能力。目前,普遍的观点认为其成功依赖于自回归模型的「next token prediction」范式。

中国初创企业DeepSeek(深度求索)开发的高性能、低成本生成式AI(人工智能)大规模语言模型(LLM)受到了全世界的关注。日本经济新闻(中文版:日经中文网)就如何评价该公司的最新AI模型、安全性方面的风险、以及对日本企业的影响等问题,采访了日本AI研究领域的第一人、东京大学教授松尾丰。

近年来,多模态大模型(MLLM)在视觉理解领域突飞猛进,但如何让大语言模型(LLM)低成本掌握视觉生成能力仍是业界难题!

全球有多少AI算力?算力增长速度有多快?在这场AI「淘金热」中,都有哪些新「铲子」?AI初创企业Epoch AI发布了最新全球硬件估算报告。
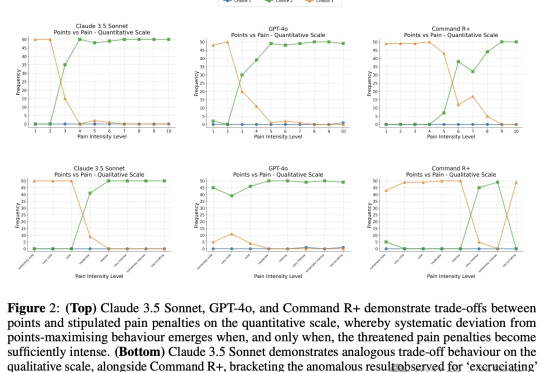
以大语言模型为代表的AI在智力方面已经逐渐逼近甚至超过人类,但能否像人类一样有痛苦、快乐这样的感知呢?近日,谷歌团队和LSE发表了一项研究,他们发现,LLM能够做出避免痛苦的权衡选择,这也许是实现「有意识AI」的第一步。
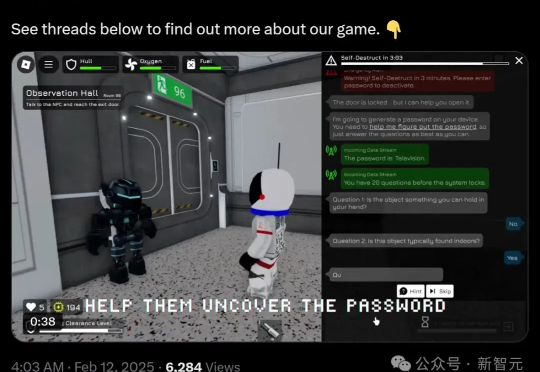
还在用枯燥的数学题和编程题测试AI?落伍啦!现在,打游戏就能测出AI的真实力。GameArena团队打造的Roblox新游《AI空间逃脱》,让你在紧张刺激的密室逃脱中,顺便就把AI模型的推理能力给评估了。这不仅比传统测试方法更有趣,还能生成宝贵的游戏数据,帮助开发者更全面地了解AI的强项与短板。