
微软发明全新「LLM语言」,AI智能体交互效率翻倍!
微软发明全新「LLM语言」,AI智能体交互效率翻倍!对于LLM来说,人类语言可能不是最好的交流媒介,正如《星战》中的机器人有自己的一套语言,近日,来自微软的研究人员改进了智能体间的交互方式,使模型的通信速度翻倍且不损失精度。
来自主题: AI技术研报
7223 点击 2024-12-01 15:30
 搜索
搜索
对于LLM来说,人类语言可能不是最好的交流媒介,正如《星战》中的机器人有自己的一套语言,近日,来自微软的研究人员改进了智能体间的交互方式,使模型的通信速度翻倍且不损失精度。

教育一直被认为是会被LLM改变最大的行业之一。ChatGPT 的使用场景中,教育占据了很大比重,其用量常随开学和假期规律波动。而 Andrej Karpathy 也选择了教育作为他的创业方向。人们都期待能够有全能的AI Tutor,因材施教,提供给每个人最好、最个性化的教育。
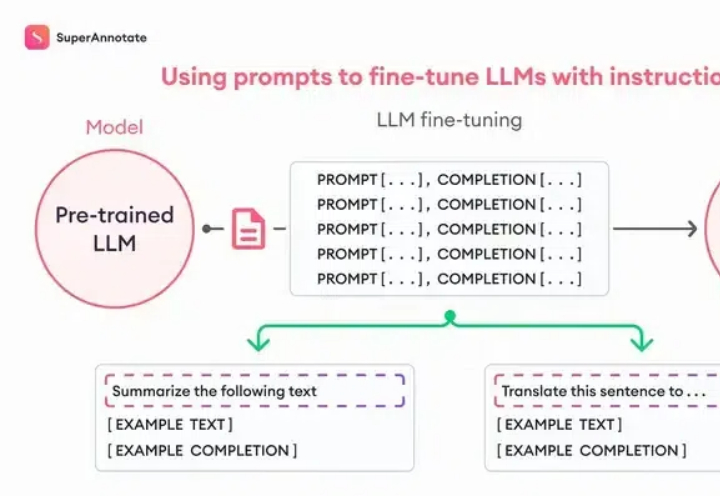
Fine-tuning理论上很复杂,但是OpenAI把这个功能完善到任何一个人看了就能做出来的程度。我们先从原理入手,你看这张图,左边是Pre-trained LLM (预训练大模型模型),也就是像ChatGPT这样的模型;右边是Fine-tuned LLM (微调过的语言大模型),中间就是进行微调的过程,它需要我们提供一些「ChatGPT提供不了但是我们需要的东西」。

LLM 规模扩展的一个根本性挑战是缺乏对涌现能力的理解。特别是,语言模型预训练损失是高度可预测的。然而,下游能力的可预测性要差得多,有时甚至会出现涌现跳跃(emergent jump),这使得预测未来模型的能力变得具有挑战性。
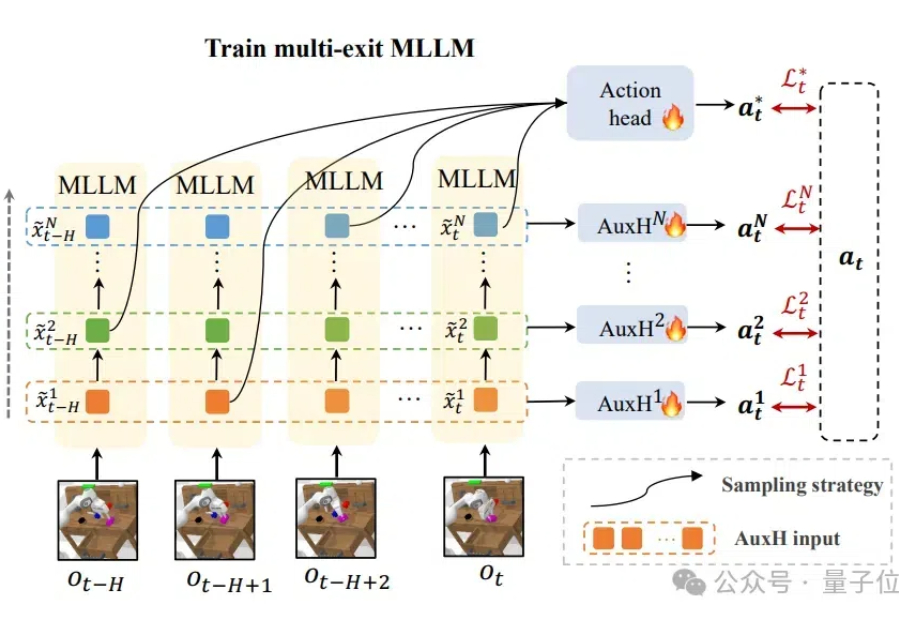
计算、存储消耗高,机器人使用多模态模型的障碍被解决了! 来自清华大学的研究者们设计了DeeR-VLA框架,一种适用于VLA的“动态推理”框架,能将LLM部分的相关计算、内存开销平均降低4-6倍。

2024 年即将结束,今年行业对 AI 的论调也基本尘埃落定.相比 2023 年的多个重磅发布,2024 年是模型能力的小年,但 AI Agent 却是实在的大年。

当前,生成式AI正席卷整个社会,大语言模型(LLMs)在文本(ChatGPT)和图像(DALL-E)生成方面取得了令人惊叹的成就,仅仅依赖零星几个提示词,它们就能生成超出预期的内容

就在刚刚,LeCun一反常态地表示:AGI离我们只有5到10年了!这个说法,跟之前的「永远差着10到20年」大相径庭。当然,他还是把LLM打为死路,坚信自己的JEPA路线。至此,各位大佬们的口径是对齐了,有眼力见儿的投资人该继续投钱了。
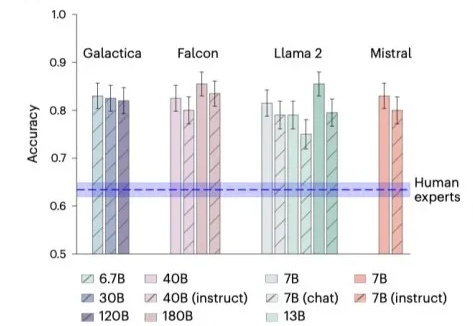
LLM可以比科学家更准确地预测神经学的研究结果!
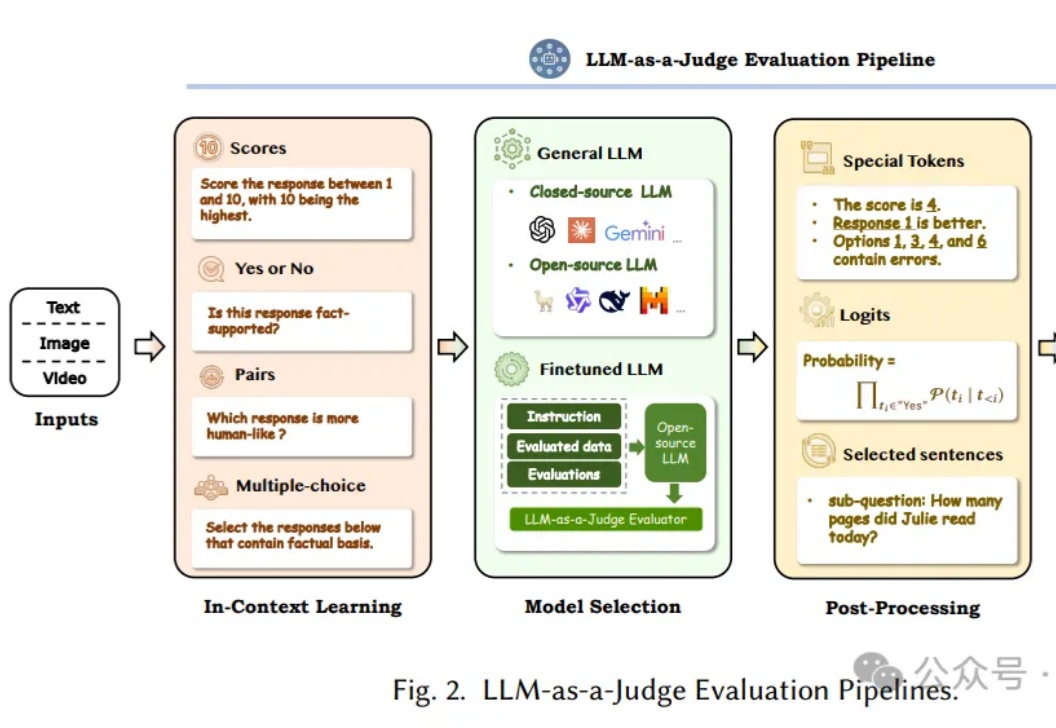
让AI来评判AI,即利用大语言模型(LLM)作为评判者,已经成为近半年的Prompt热点领域。这个方向不仅代表了AI评估领域的重要突破,更为正在开发AI产品的工程师们提供了一个全新的思路。