
开源1.6B小模型「小狐狸」,表现超同类模型Qwen和Gemma
开源1.6B小模型「小狐狸」,表现超同类模型Qwen和Gemma自从 Chatgpt 诞生以来,LLM(大语言模型)的参数量似乎就成为了各个公司的竞赛指标。GPT-1 参数量为 1.17 亿(1.17M),而它的第四代 GPT-4 参数量已经刷新到了 1.8 万亿(1800B)。
来自主题: AI技术研报
9412 点击 2024-12-08 12:20
 搜索
搜索
自从 Chatgpt 诞生以来,LLM(大语言模型)的参数量似乎就成为了各个公司的竞赛指标。GPT-1 参数量为 1.17 亿(1.17M),而它的第四代 GPT-4 参数量已经刷新到了 1.8 万亿(1800B)。
人类离AGI究竟还有多远?最新一期Nature文章,从以往研究分析、多位大佬言论深入探讨了LLM在智能化道路上突破与局限。

以 GPT4V 为代表的多模态大模型(LMMs)在大语言模型(LLMs)上增加如同视觉的多感官技能,以实现更强的通用智能。虽然 LMMs 让人类更加接近创造智慧,但迄今为止,我们并不能理解自然与人工的多模态智能是如何产生的。
最近从由大型语言模型(LLM)驱动的聊天机器人向如今该领域所定义的 Agent 系统或 Agentic AI 的转变,可以用一句老话来概括:“少说话,多做事。”
Yoshua Bengio最近在《金融时报》的专栏文章中表示,「AI可以在说话之前学会思考」,实现内部的深思熟虑将成为AGI道路的里程碑。无独有偶,就在几个月前,Yann LeCun也多次表达过类似的观点。
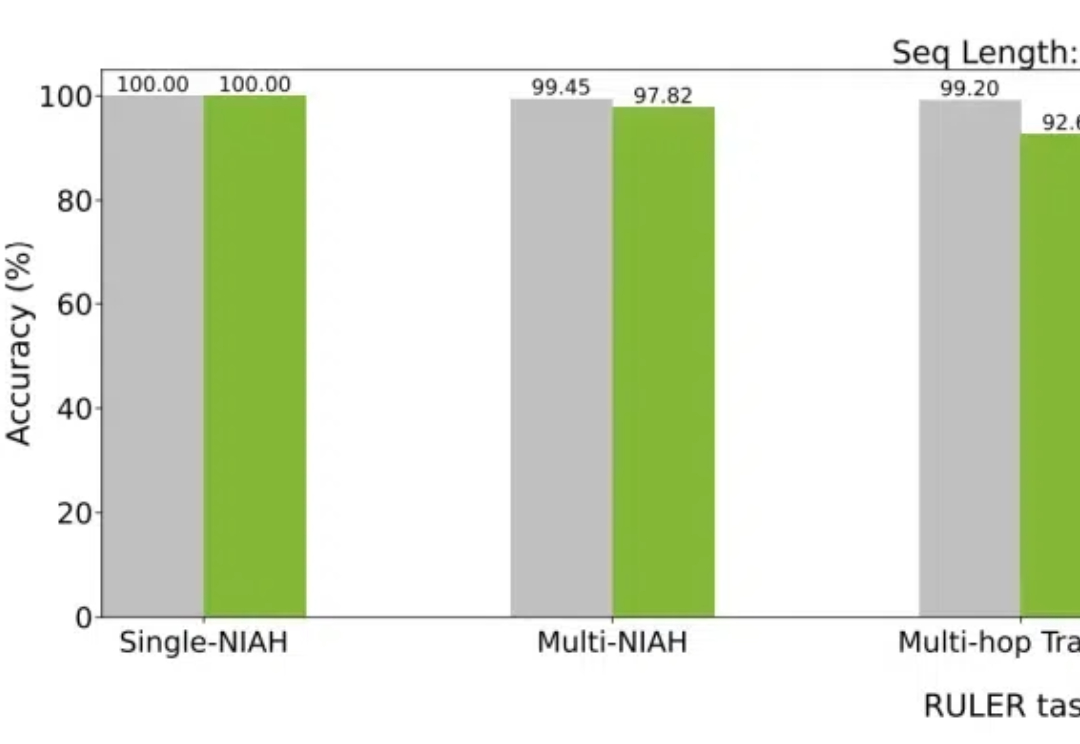
大模型如今已具有越来越长的上下文,而与之相伴的是推理成本的上升。英伟达最新提出的Star Attention,能够在不损失精度的同时,显著减少推理计算量,从而助力边缘计算。
评估和评价长期以来一直是人工智能 (AI) 和自然语言处理 (NLP) 中的关键挑战。然而,传统方法,无论是基于匹配还是基于词嵌入,往往无法判断精妙的属性并提供令人满意的结果。

LLM在推理时,竟是通过一种「程序性知识」,而非照搬答案?可以认为这是一种变相的证明:LLM的确具备某种推理能力。然而存在争议的是,这项研究只能提供证据,而非证明。
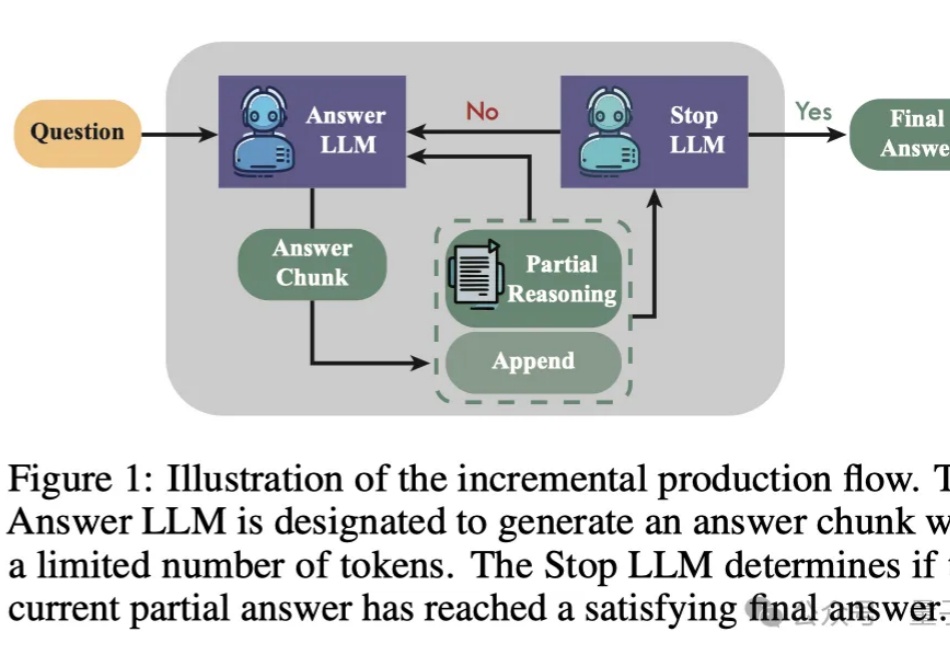
提升LLM数学能力的新方法来了——
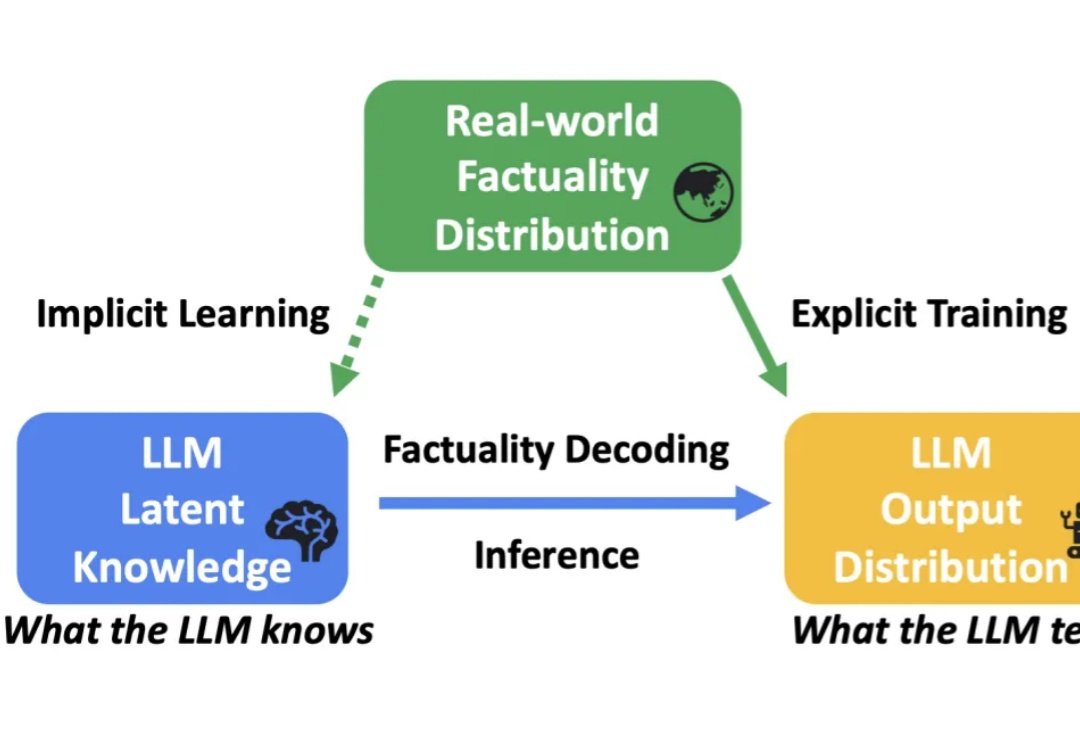
大语言模型(LLM)在各种任务上展示了卓越的性能。然而,受到幻觉(hallucination)的影响,LLM 生成的内容有时会出现错误或与事实不符,这限制了其在实际应用中的可靠性。