RAG真能提升LLM推理能力?人大最新研究:数据有噪声,RAG性能不升反降
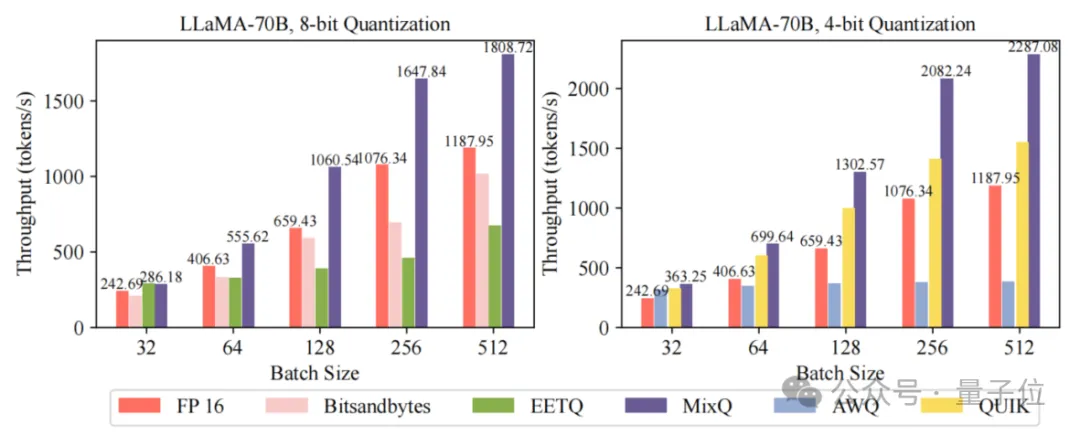
RAG真能提升LLM推理能力?人大最新研究:数据有噪声,RAG性能不升反降RAG通过纳入外部文档可以辅助LLM进行更复杂的推理,降低问题求解所需的推理深度,但由于文档噪声的存在,其提升效果可能会受限。中国人民大学的研究表明,尽管RAG可以提升LLM的推理能力,但这种提升作用并不是无限的,并且会受到文档中噪声信息的影响。通过DPrompt tuning的方法,可以在一定程度上提升LLM在面对噪声时的性能。
来自主题: AI技术研报
4346 点击 2024-10-23 10:32