
它来了,剑桥最新LLM提示词压缩调查报告
它来了,剑桥最新LLM提示词压缩调查报告别说Prompt压缩不重要,你可以不在乎Token成本,但总要考虑内存和LLM响应时间吧?一个显著的问题逐渐浮出水面:随着任务复杂度增加,提示词(Prompt)往往需要变得更长,以容纳更多详细需求、上下文信息和示例。这不仅降低了推理速度,还会增加内存开销,影响用户体验。
来自主题: AI资讯
11069 点击 2024-10-29 12:28
 搜索
搜索
别说Prompt压缩不重要,你可以不在乎Token成本,但总要考虑内存和LLM响应时间吧?一个显著的问题逐渐浮出水面:随着任务复杂度增加,提示词(Prompt)往往需要变得更长,以容纳更多详细需求、上下文信息和示例。这不仅降低了推理速度,还会增加内存开销,影响用户体验。
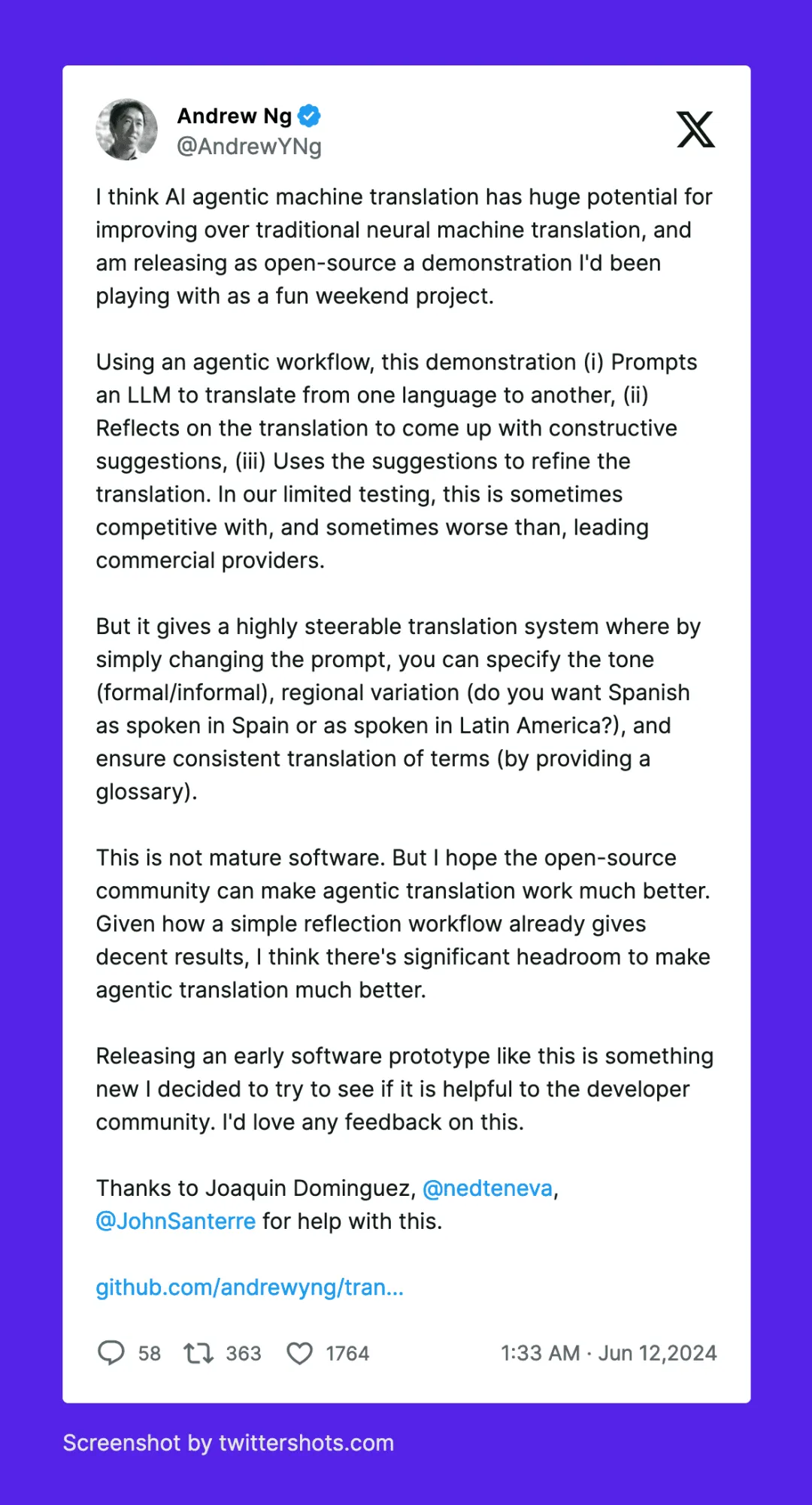
吴恩达老师提出了一种反思翻译的大语言模型 (LLM) AI 翻译工作流程

10月28日,澎湃新闻记者获悉,字节跳动准备在欧洲设立AI研发中心,已开始在欧洲积极招募LLM(大语言模型)和AI领域的顶尖技术人才,以加强其在全球第二大经济体中的人工智能研发能力。

在人工智能技术快速发展的今天,大语言模型(LLM)已经展现出惊人的能力。然而,让这些模型生成规范的结构化输出仍然是一个难以攻克的技术难题。不论是在开发自动化工具、构建特定领域的解决方案,还是在进行开发工具集成时,都迫切需要LLM能够产生格式严格、内容可靠的输出。
今年 4 月,斯坦福大学推出了一款利用大语言模型(LLM)辅助编写类维基百科文章的神器。它就是开源的 STORM,可以在三分钟左右将你输入的主题转换为长篇文章或者研究论文,并能够以 PDF 格式直接下载。

这两天,Claude 3.5 Sonnet升级版刷爆了朋友圈,满屏都是:它能像人一样操作电脑。 大语言模型(Large Language Model,LLM)能够像人一样操作电脑这件事,看起来蛮炸裂的,但在AI Agent圈子里早已经见多不怪了。

哈佛大学研究了大型语言模型在回答晦涩难懂和有争议问题时产生「幻觉」的原因,发现模型输出的准确性高度依赖于训练数据的质量和数量。研究结果指出,大模型在处理有广泛共识的问题时表现较好,但在面对争议性或信息不足的主题时则容易产生误导性的回答。

北京大学的研究人员开发了一种新型多模态框架FakeShield,能够检测图像伪造、定位篡改区域,并提供基于像素和图像语义错误的合理解释,可以提高图像伪造检测的可解释性和泛化能力。

现如今,大型语言模型(LLM)生成的内容已经充斥了整个互联网,并且这些模型还能模仿各种类似真人的语气和行文风格,让人难以分辨眼前的文本究竟来自人类还是 AI。

TL;DR:DuoAttention 通过将大语言模型的注意力头分为检索头(Retrieval Heads,需要完整 KV 缓存)和流式头(Streaming Heads,只需固定量 KV 缓存),大幅提升了长上下文推理的效率,显著减少内存消耗、同时提高解码(Decoding)和预填充(Pre-filling)速度,同时在长短上下文任务中保持了准确率。