
当大模型汲取进化记忆,它离“人性”还有多远?
当大模型汲取进化记忆,它离“人性”还有多远?大语言模型(LLMs)作为由复杂算法和海量数据驱动的产物,会不会“无意中”学会了某些类似人类进化出来的行为模式?这听起来或许有些大胆,但背后的推理其实并不难理解:
来自主题: AI资讯
6251 点击 2025-06-03 10:57
 搜索
搜索
大语言模型(LLMs)作为由复杂算法和海量数据驱动的产物,会不会“无意中”学会了某些类似人类进化出来的行为模式?这听起来或许有些大胆,但背后的推理其实并不难理解:

近年来,大语言模型(LLMs)的能力突飞猛进,但随之而来的隐私风险也逐渐浮出水面。
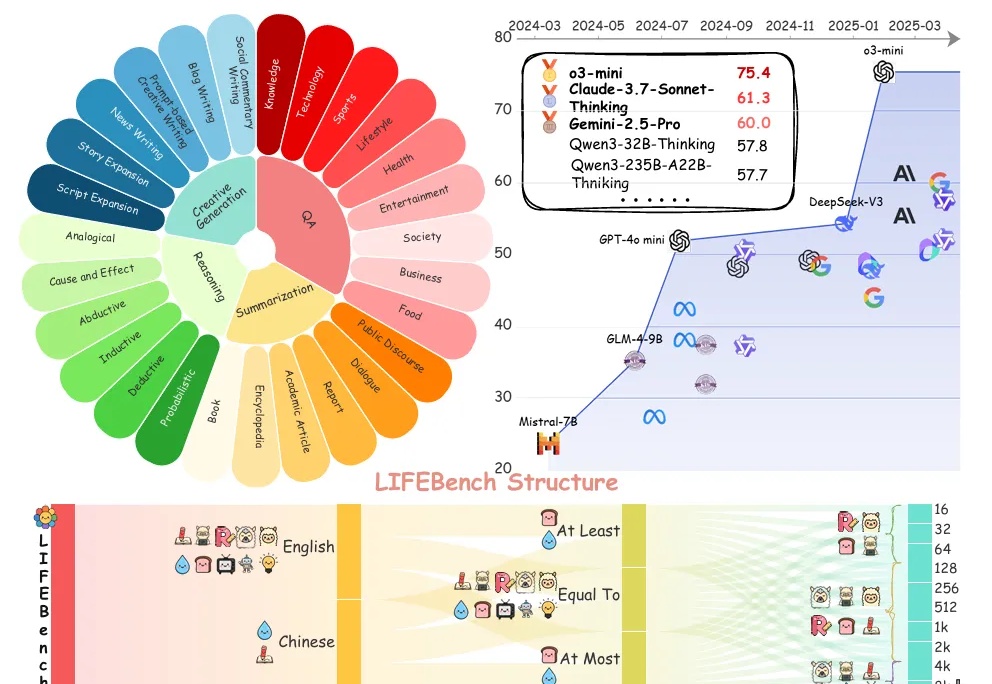
你是否曾对大语言模型(LLMs)下达过明确的“长度指令”?
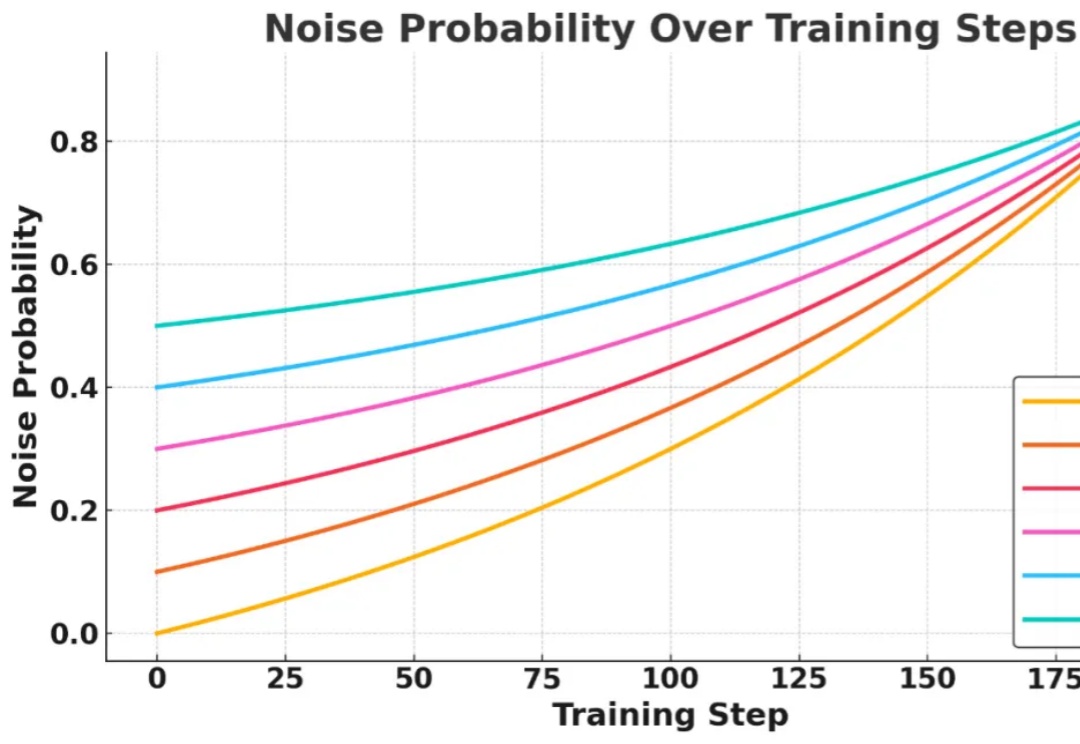
信息检索能力对提升大语言模型 (LLMs) 的推理表现至关重要,近期研究尝试引入强化学习 (RL) 框架激活 LLMs 主动搜集信息的能力,但现有方法在训练过程中面临两大核心挑战:
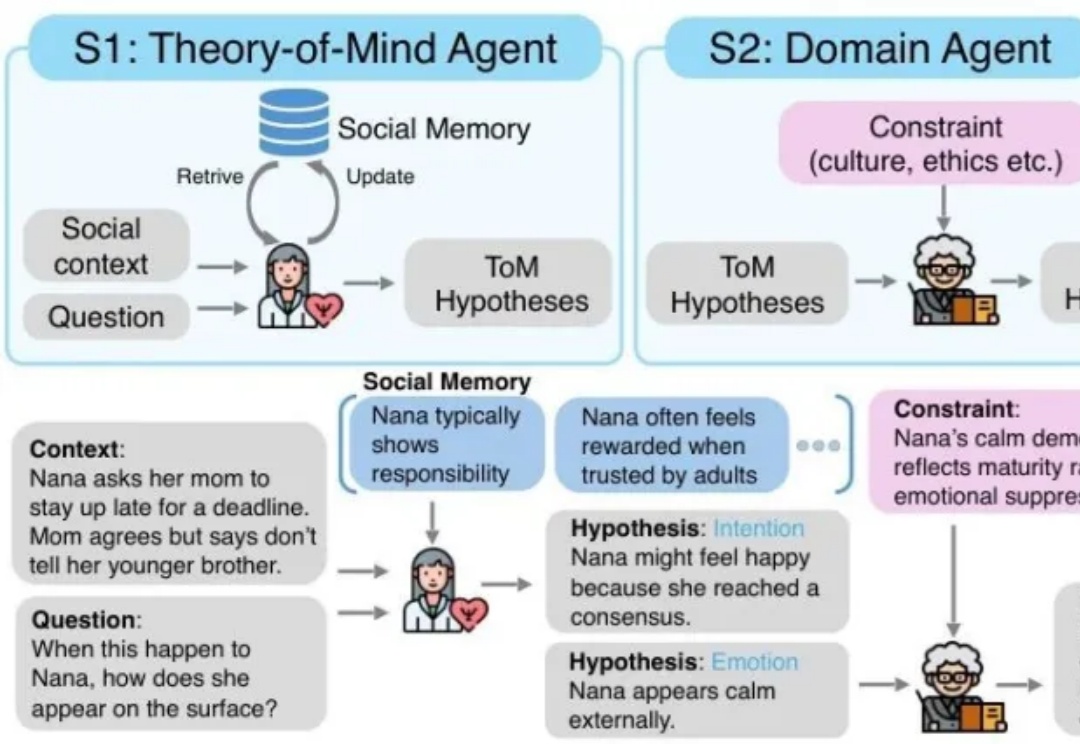
MetaMind是一个多智能体框架,专门解决大语言模型在社交认知方面的根本缺陷。传统的 LLM 常常难以应对现实世界中人际沟通中固有的模糊性和间接性,无法理解未说出口的意图、隐含的情绪或文化敏感线索。MetaMind首次使LLMs在关键心理理论(ToM)任务上达到人类水平表现。
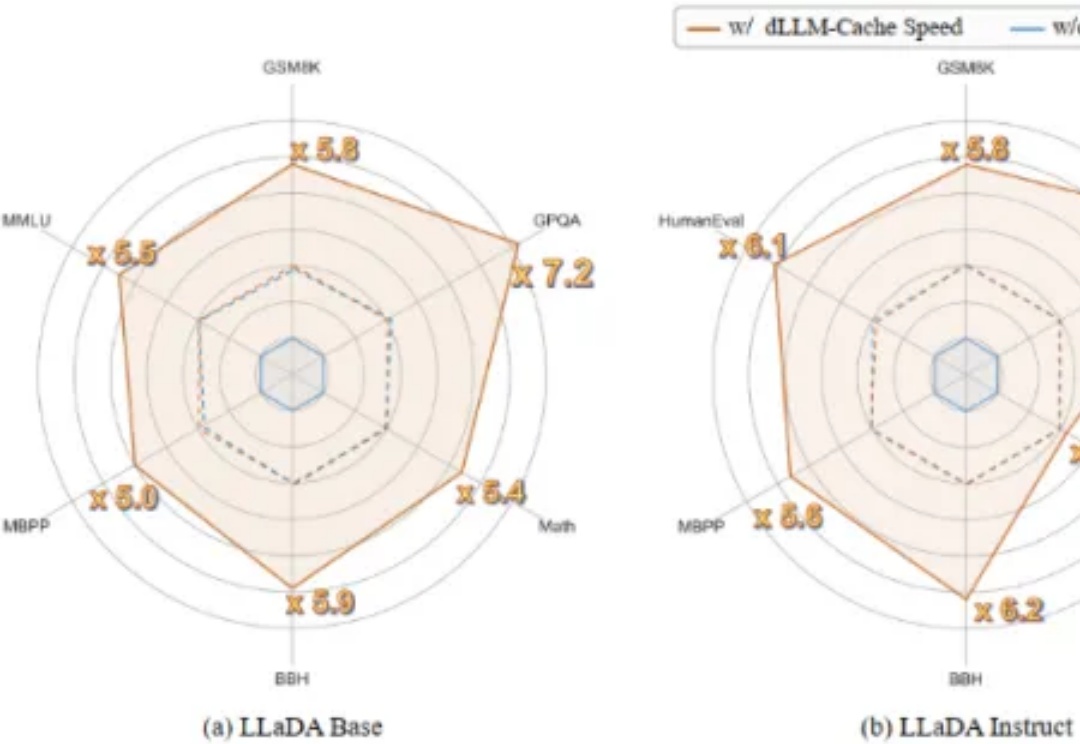
首个用于加速扩散式大语言模型(diffusion-based Large Language Models, 简称 dLLMs)推理过程的免训练方法。
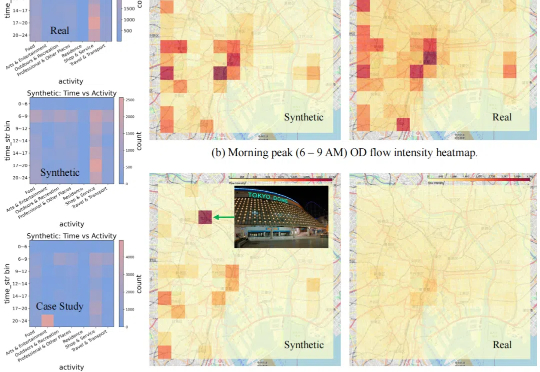
现有的数据合成方法在合理性和分布一致性方面存在不足,且缺乏自动适配不同数据的能力,扩展性较差。

在文档理解领域,多模态大模型(MLLMs)正以惊人的速度进化。从基础文档图像识别到复杂文档理解,它们在扫描或数字文档基准测试(如 DocVQA、ChartQA)中表现出色,这似乎表明 MLLMs 已很好地解决了文档理解问题。然而,现有的文档理解基准存在两大核心缺陷:
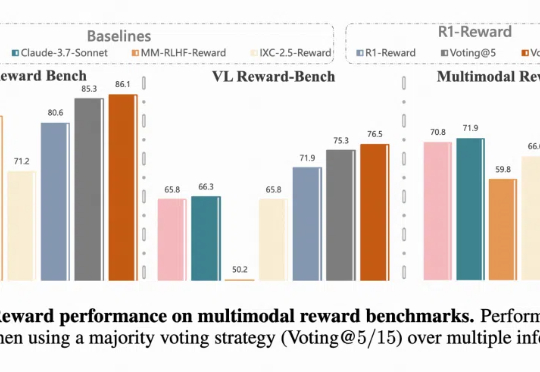
多模态奖励模型(MRMs)在提升多模态大语言模型(MLLMs)的表现中起着至关重要的作用,在训练阶段可以提供稳定的 reward,评估阶段可以选择更好的 sample 结果,甚至单独作为 evaluator。
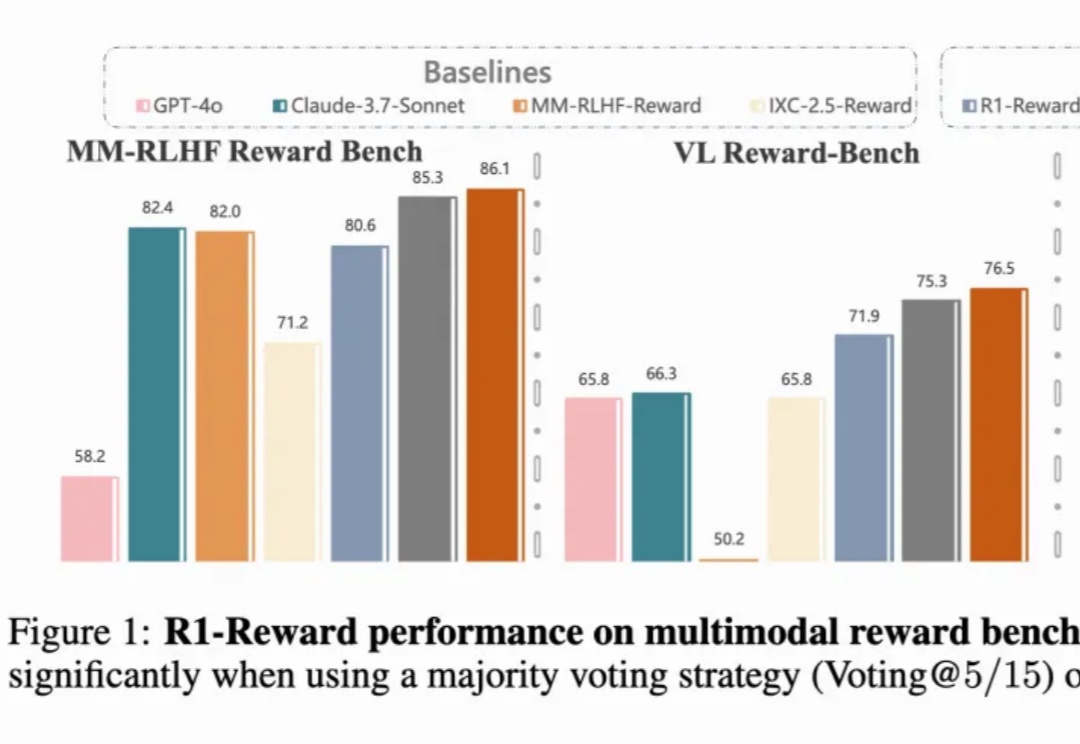
多模态奖励模型(MRMs)在提升多模态大语言模型(MLLMs)的表现中起着至关重要的作用: