# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
本文的共同第一作者为字节跳动算法工程师王安澜和廖蕾,本文的通讯作者为字节跳动算法工程师唐景群。
在文档理解领域,多模态大模型(MLLMs)正以惊人的速度进化。从基础文档图像识别到复杂文档理解,它们在扫描或数字文档基准测试(如 DocVQA、ChartQA)中表现出色,这似乎表明 MLLMs 已很好地解决了文档理解问题。然而,现有的文档理解基准存在两大核心缺陷:

这些缺陷引出了一个关键疑问:当前 MLLMs 模型距离在自然环境中实现全面且鲁棒的文档理解能力到底还有多远?
为了揭开这个谜底,字节跳动 OCR 团队联合华中科技大学打造了 WildDoc—— 首个真实世界场景文档理解的基准数据集。
WildDoc 选取了 3 个常用的具有代表性的文档场景作为基准(Document/Chart/Table), 包含超过 12,000 张手动拍摄的图片,覆盖了环境、光照、视角、扭曲和拍摄效果等五个影响真实世界文档理解效果的因素,且可与现有的电子基准数据集表现进行对比。
为了严格评估模型的鲁棒性,WildDoc 构建了一致性评估指标(Consistency Score)。实验发现主流 MLLMs 在 WildDoc 上性能显著下降,揭示了现有模型在真实场景文档理解的性能瓶颈,并为技术改进提供可验证的方向。本工作不仅填补了真实场景基准的空白,更推动文档理解研究向「实用化、泛化性」迈出关键一步。

WildDoc 数据构造与组成
WildDoc 数据包含超 1.2 万张手动采集的真实文档图像,模拟自然环境中的复杂挑战,并引入一致性分数指标,量化评估模型在跨场景下的鲁棒性。WildDoc 目前已开源全部 12K + 图像与 48K + 问答对,其构造过程如下:
1、数据采集:
2、多条件拍摄:
3、标注与验证:

实验结果
研究团队对众多具有代表性的 MLLMs 进行了测试,包括通用 MLLMs(如 Qwen2.5-VL、InternVL2.5)、专注文档理解的 MLLMs(如 Monkey、TextHarmony)和领先的闭源 MLLMs(如 GPT4o、Doubao-1.5-pro)。实验结果揭示了当前多模态大模型在真实场景下的诸多不足。
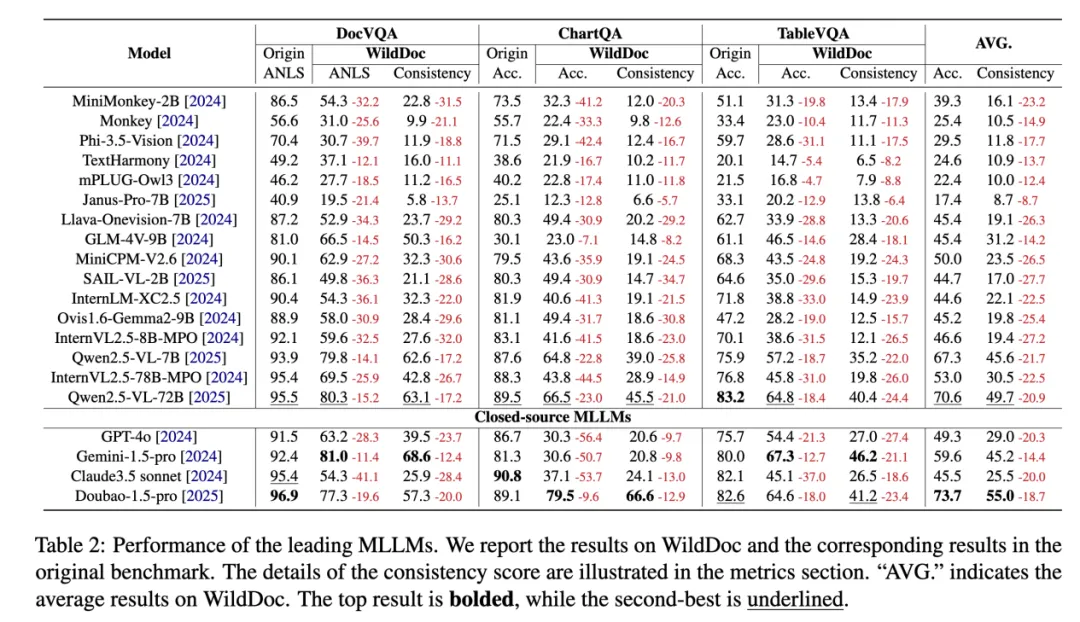
首先,现有 MLLMs 在 WildDoc 上的性能相比传统文档基准(如 DocVQA)测试大幅下降。例如,GPT-4o 平均准确率下降 35.3,ChartQA 子集下降达 56.4;开源模型 Qwen2.5-VL-72B 平均准确率 70.6,为开源最佳,但仍低于原始基准约 15%。目前最优的闭源模型为 Doubao-1.5-pro 表现最优(平均准确率 73.7%),但其一致性分数仅 55.0,这也意味着它在一半多的情况下都不能在不同条件下保持准确回答。这表明,当前 MLLMs 模型在面对真实场景的变化时,缺乏足够的稳定性和适应性。
实验结果揭示了在真实世界文档理解中 MLLMs 模型的表现,有以下几点发现:

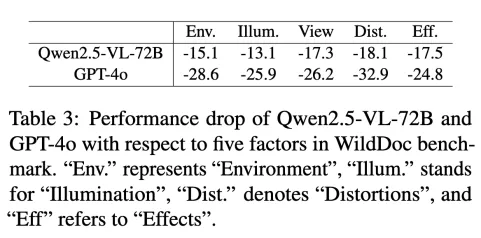
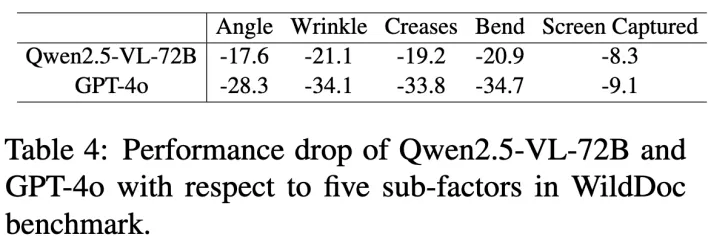
另外,一些模型在原始基准测试上表现差异不大,甚至已经接近饱和,但在 WildDoc 上却出现了显著的性能差异。这说明传统基准测试已经难以区分模型的真实能力,而 WildDoc 则能更敏锐地捕捉到模型在真实场景下的不足。
未来之路:如何让 MLLMs 更好地理解真实世界的文档?
面对这些挑战,研究团队提出了几点改进策略,为未来的研究指明了方向。
WildDoc 数据集有效揭示了 MLLMs 在真实文档理解中的不足,为后续研究提供了关键基准和优化方向,更推动文档理解研究向「实用化、泛化性」迈出关键一步。
文章来自微信公众号 “ 机器之心 ”



【免费】ffa.chat是一个完全免费的GPT-4o镜像站点,无需魔法付费,即可无限制使用GPT-4o等多个海外模型产品。
在线使用:https://ffa.chat/
