
突破86%,解耦LLM的记忆与推理,首个超越GPT-4o的推理框架(含prompt) | 最新
突破86%,解耦LLM的记忆与推理,首个超越GPT-4o的推理框架(含prompt) | 最新这是一个不容小觑的最新推理框架,它解耦了LLM的记忆与推理,用此框架Fine-tuned过的LLaMa-3.1-8B在TruthfulQA数据集上首次超越了GPT-4o。
来自主题: AI技术研报
8447 点击 2024-11-28 11:26
 搜索
搜索
这是一个不容小觑的最新推理框架,它解耦了LLM的记忆与推理,用此框架Fine-tuned过的LLaMa-3.1-8B在TruthfulQA数据集上首次超越了GPT-4o。

只要改一行代码,就能让大模型训练效率提升至1.47倍。

如果给LLM做MBTI,会得到什么结果?UC伯克利的最新研究就发现,不同模型真的有自己独特的性格
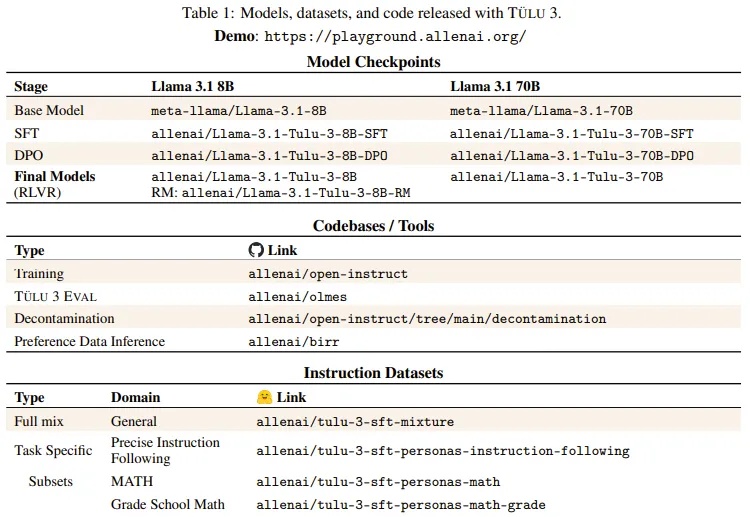
开源模型阵营又迎来一员猛将:Tülu 3。它来自艾伦人工智能研究所(Ai2),目前包含 8B 和 70B 两个版本(未来还会有 405B 版本),并且其性能超过了 Llama 3.1 Instruct 的相应版本!长达 73 的技术报告详细介绍了后训练的细节。
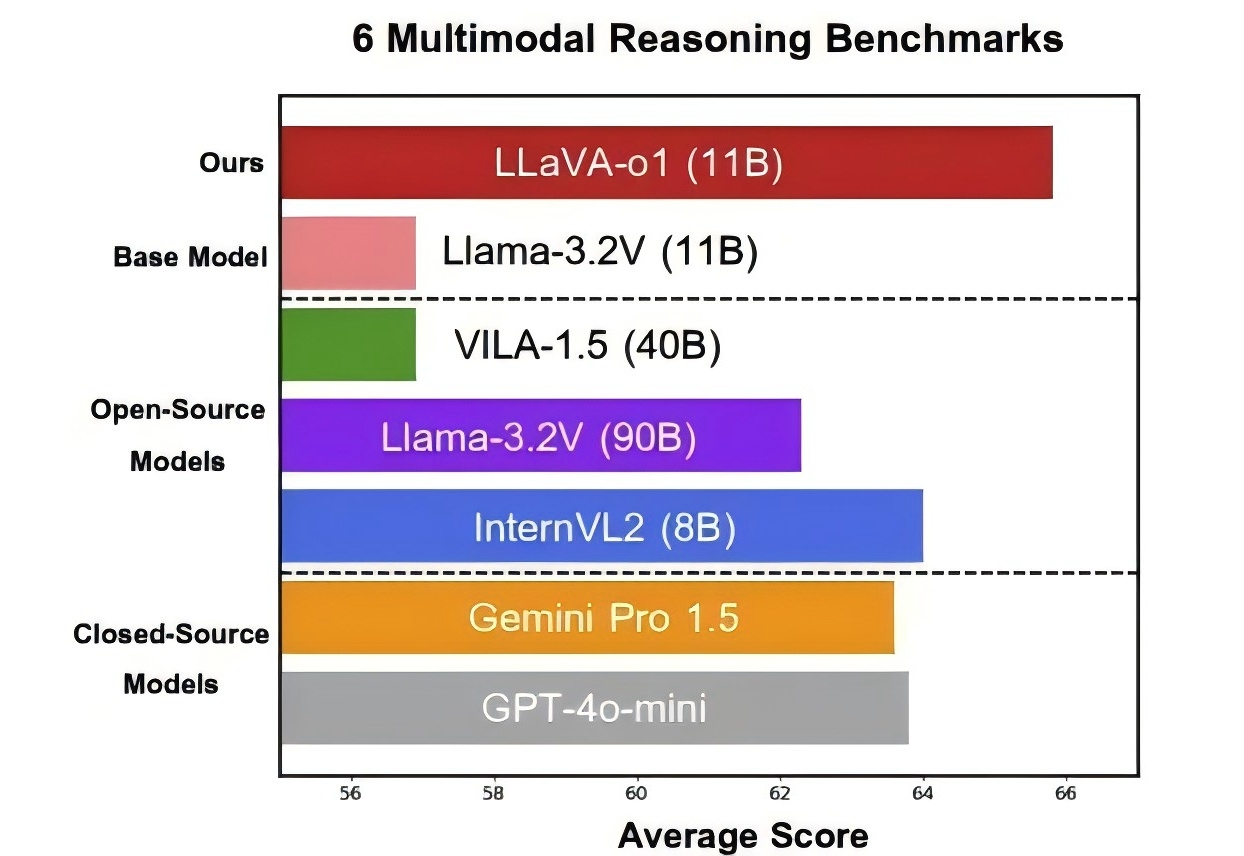
北大等出品,首个多模态版o1开源模型来了—— 代号LLaVA-o1,基于Llama-3.2-Vision模型打造,超越传统思维链提示,实现自主“慢思考”推理。 在多模态推理基准测试中,LLaVA-o1超越其基础模型8.9%,并在性能上超越了一众开闭源模型。
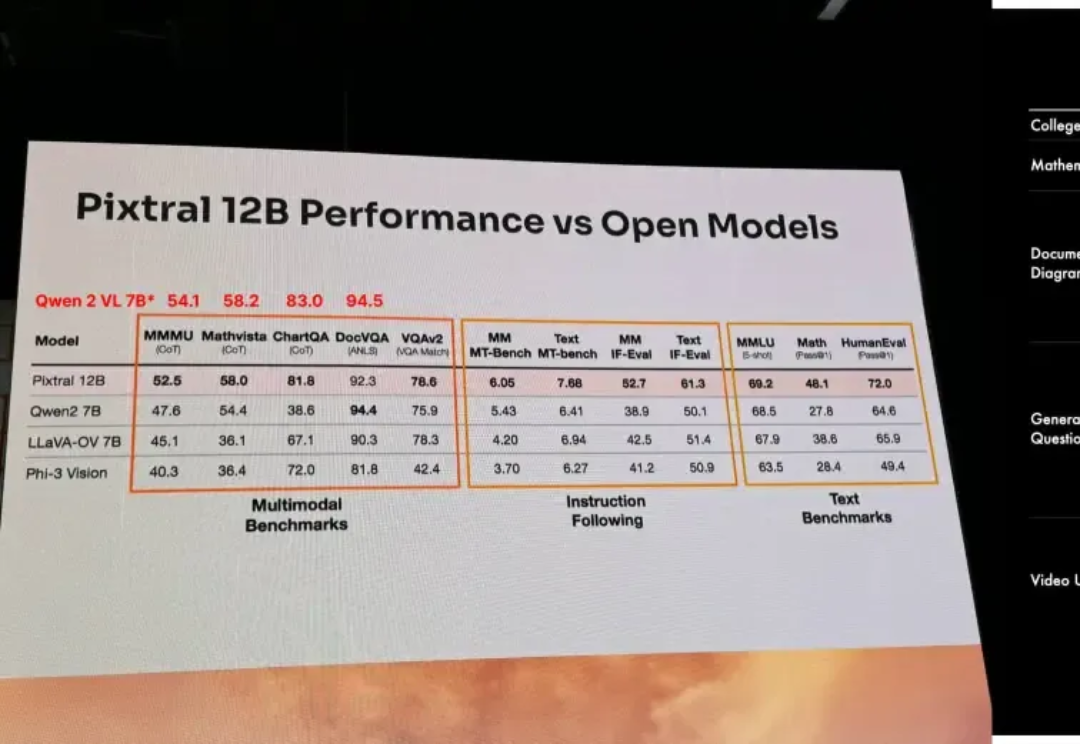
以开源极客之姿杀入江湖的Mistral AI,在9月份甩出了自家的首款多模态大模型Pixtral 12B,如今,报告之期已至,技术细节全公开。

研究人员通过案例研究,利用大型语言模型(LLMs)如GPT-4、Claude 3和Llama 3.1,探索了思维链(CoT)提示在解码移位密码任务中的表现;CoT提示虽然提升了模型的推理能力,但这种能力并非纯粹的符号推理,而是结合了记忆和概率推理的复杂过程。

大模型的记忆限制被打破了,变相实现“无限长”上下文。最新成果,来自清华、厦大等联合提出的LLMxMapReduce长本文分帧处理技术。
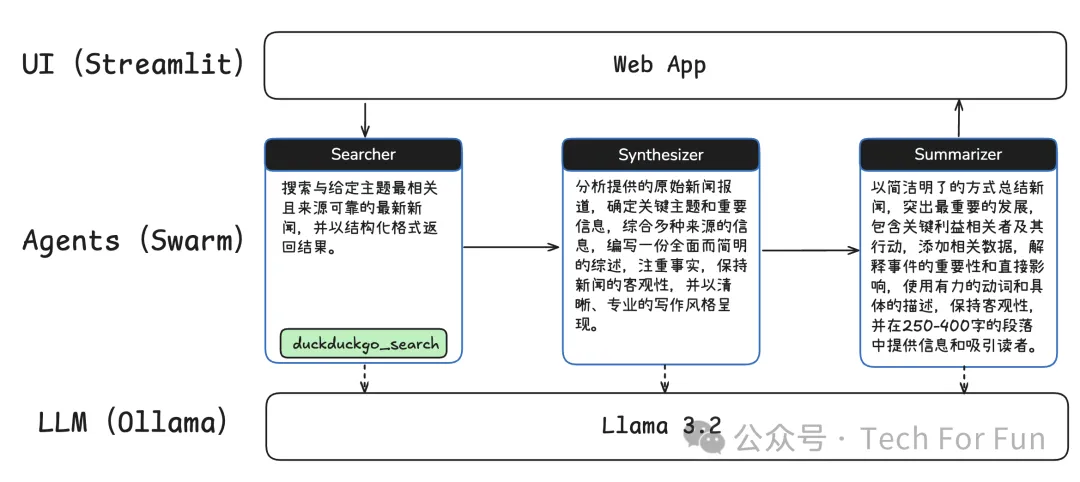
本文将带你构建一个多智能体新闻助理,利用 OpenAI 的 Swarm 框架和 Llama 3.2 来自动化新闻处理工作流。在本地运行环境下,我们将实现一个多智能体系统,让不同的智能体各司其职,分步完成新闻搜索、信息综合与摘要生成等任务,而无需付费使用外部服务。

复刻OpenAI o1推理大模型,开源界传来最新进展: LLaMA版o1项目刚刚发布,来自上海AI Lab团队。