大模型玩你画我猜:Claude6局3胜,GPT-4o表现迷惑
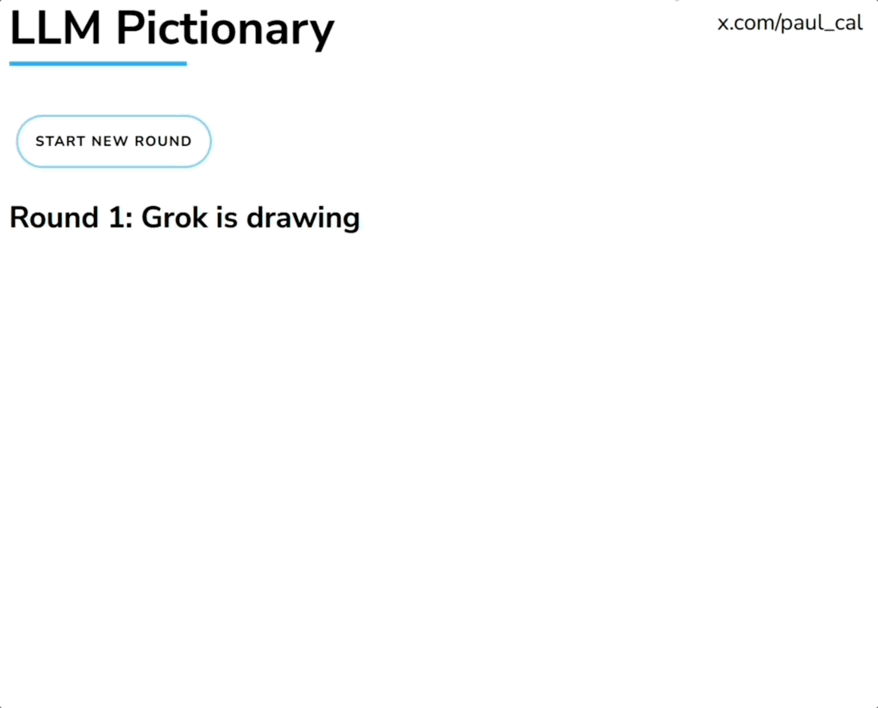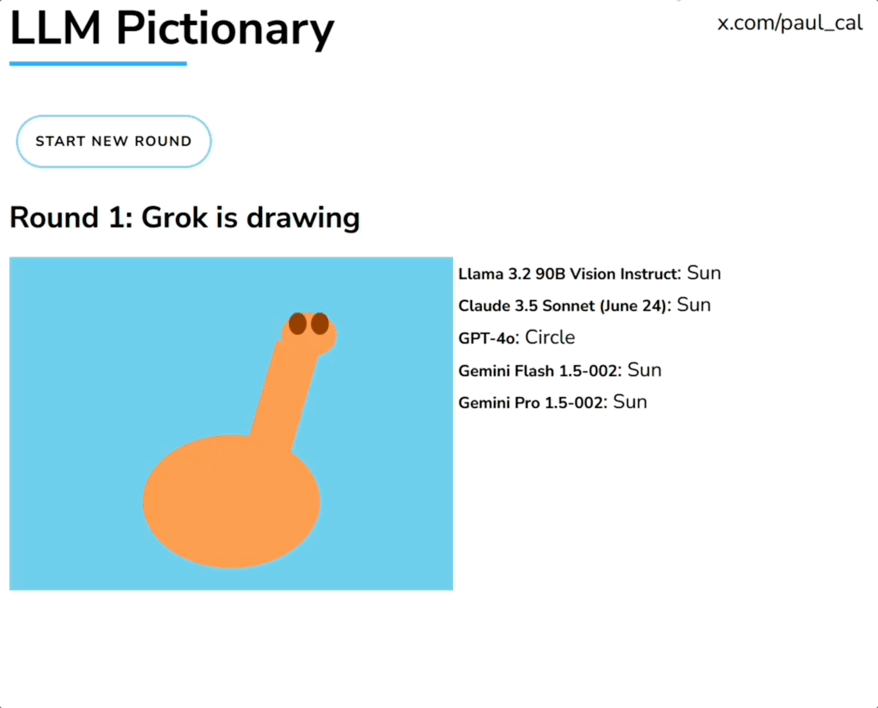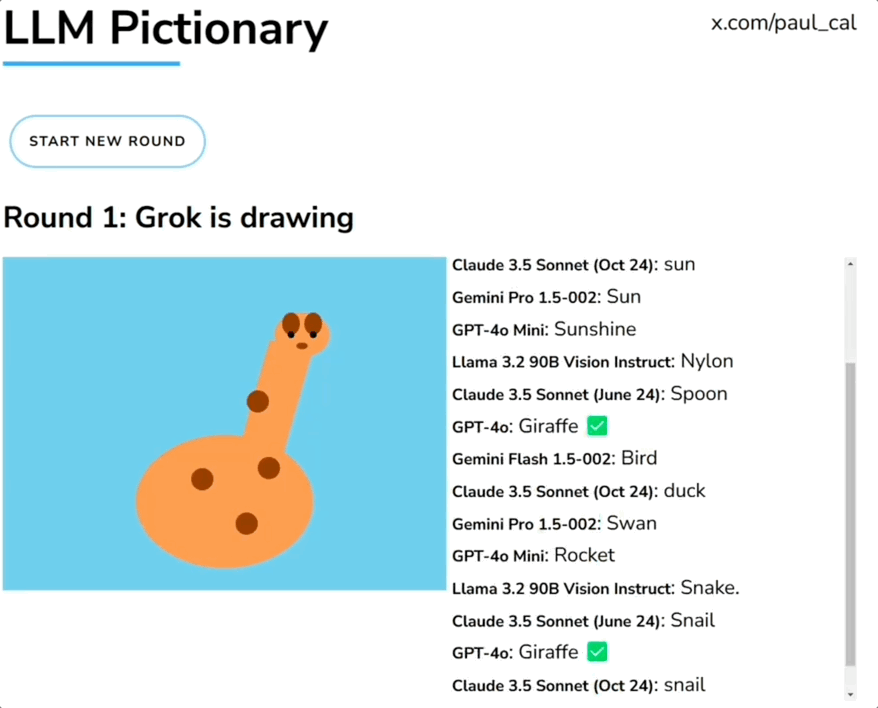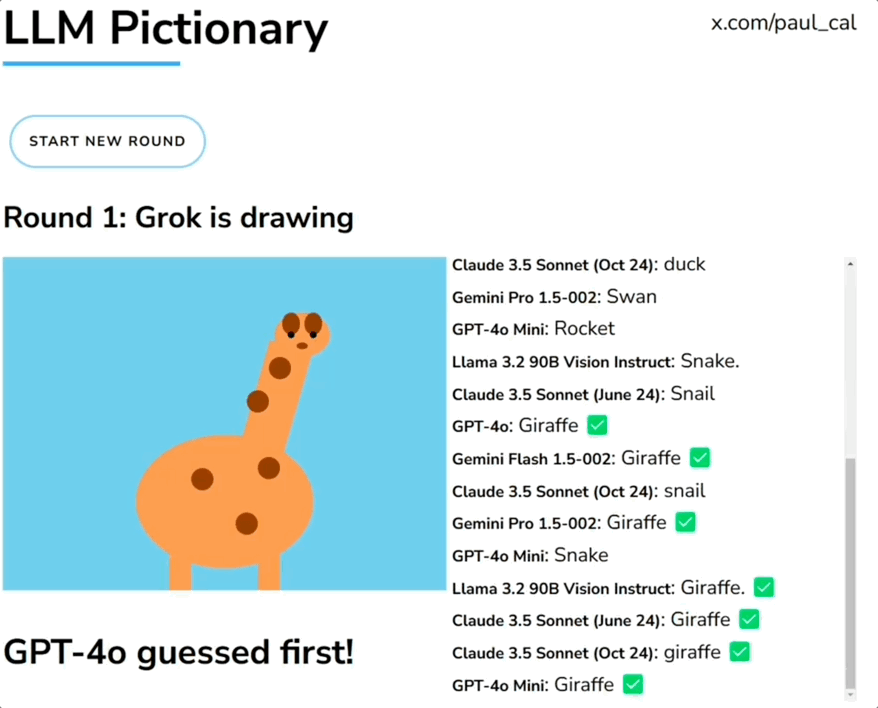
大模型玩你画我猜:Claude6局3胜,GPT-4o表现迷惑一群大模型玩你画我猜,人类一旁围观超起劲儿。 就像下面这张图展示的,由Grok画长颈鹿,一堆大模型根据生成内容猜答案。参赛选手包括GPT-4o、Claude、Llama、Gemini、Grok等。
来自主题: AI资讯
5361 点击 2024-11-03 15:02
 搜索
搜索
一群大模型玩你画我猜,人类一旁围观超起劲儿。 就像下面这张图展示的,由Grok画长颈鹿,一堆大模型根据生成内容猜答案。参赛选手包括GPT-4o、Claude、Llama、Gemini、Grok等。
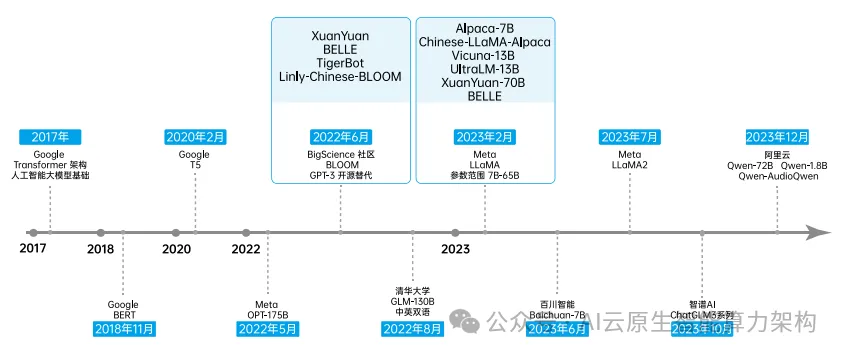
随着开源技术占据各大新兴领域的技术路线,其不断丰富人工智能领域的应用场景。 2023年,Meta 相继发布 Llama 和 Llama2,很快成为广受欢迎的开源大模型,也成为许多模型的基座模型。

北京时间 10 月 30 日,GitHub Universe 2024 如约而至,而今年正值大会十周年纪念日。本文将从 GitHub 发布的 AI 新进展入手,围绕开源模型、用户数量、盈利模式、发展历程等几个方面,全面梳理 GitHub 与 Hugging Face 两大开源平台的异同。

大模型开源的口号,不是随便说说的。

随着谷歌和 Meta 相继推出基于大语言模型的 AI 播客功能,将极大地丰富人类用户与 AI 智能体互动的体验。
Zamba2-7B是一款小型语言模型,在保持输出质量的同时,通过创新架构实现了比同类模型更快的推理速度和更低的内存占用,在图像描述等任务上表现出色,能在各种边缘设备和消费级GPU上高效运行。

Mistral 7B诞生一周年之际,法国AI初创公司Mistral再次连发两个轻量级模型Ministral 3B和Ministral 8B,性能赶超Llama 3 8B。
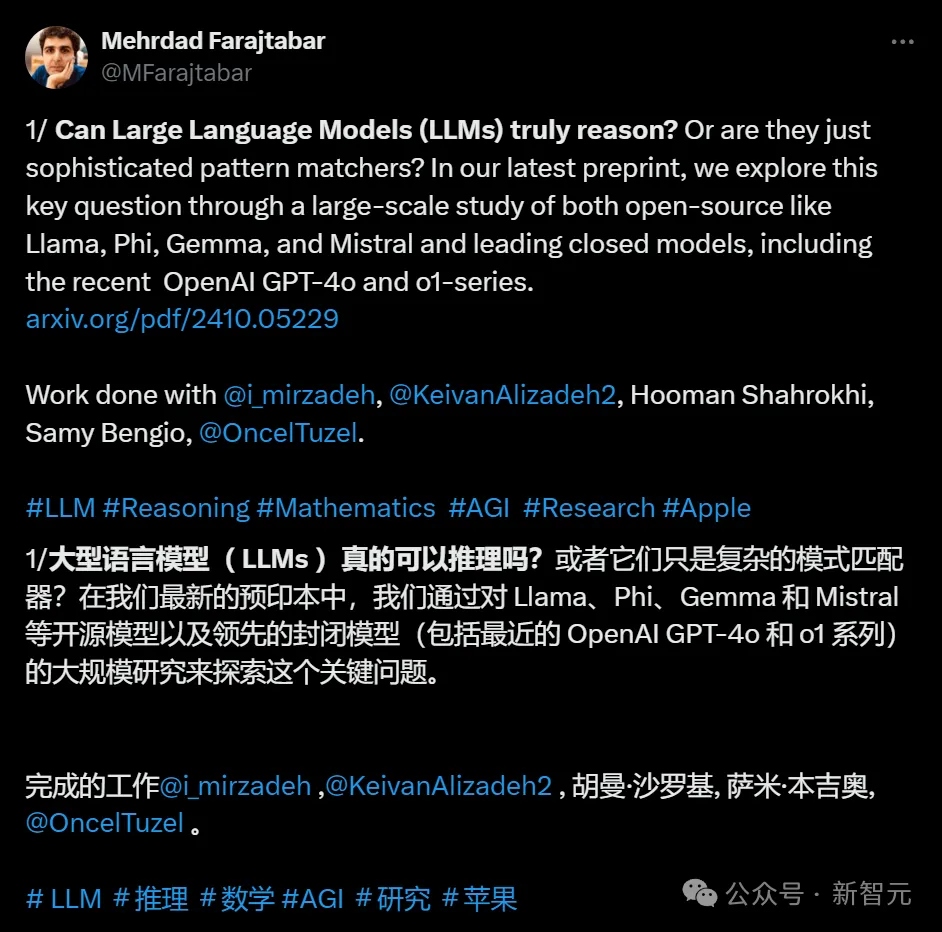
苹果研究者发现:无论是OpenAI GPT-4o和o1,还是Llama、Phi、Gemma和Mistral等开源模型,都未被发现任何形式推理的证据,而更像是复杂的模式匹配器。无独有偶,一项多位数乘法的研究也被抛出来,越来越多的证据证实:LLM不会推理!

大型语言模型 (LLM) 在各种自然语言处理和推理任务中表现出卓越的能力,某些应用场景甚至超越了人类的表现。然而,这类模型在最基础的算术问题的表现上却不尽如人意。
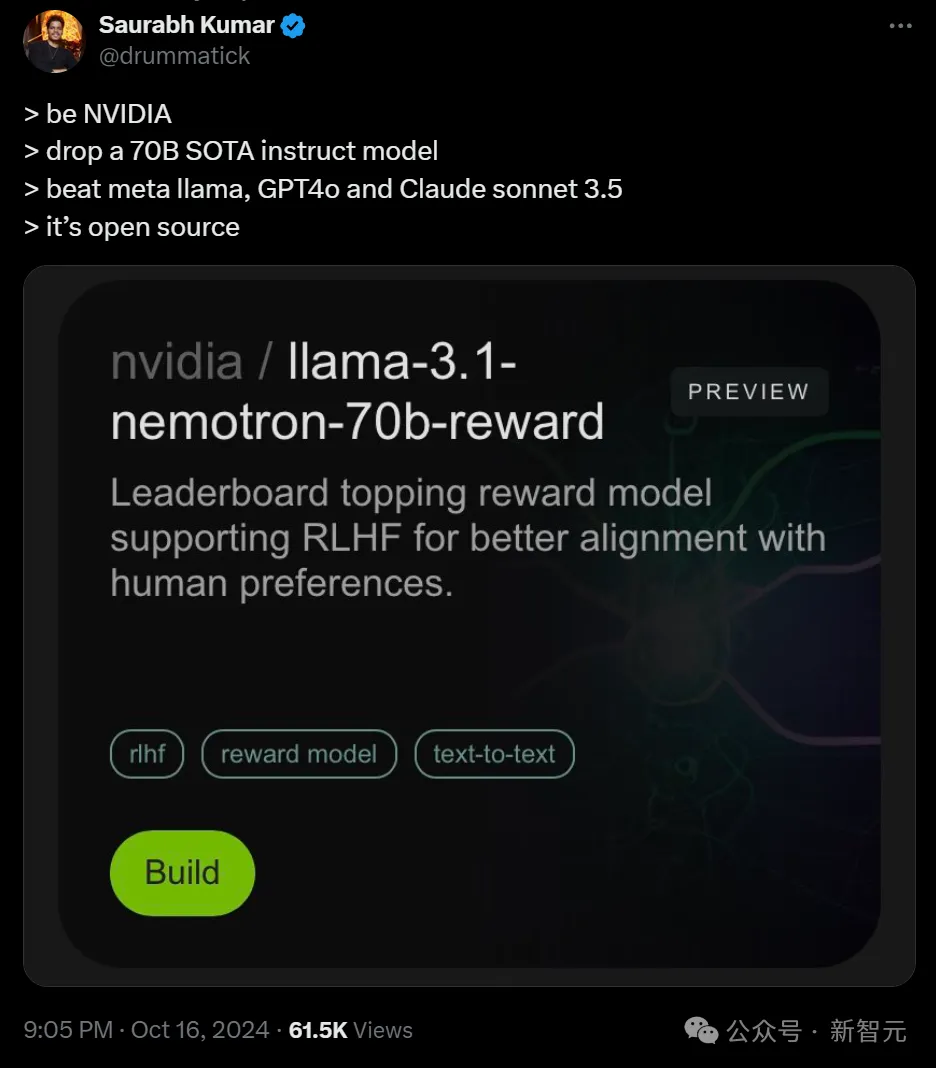
英伟达开源了超强模型Nemotron-70B,后者一经发布就超越了GPT-4o和Claude 3.5 Sonnet,仅次于OpenAI o1!AI社区惊呼:新的开源王者又来了?业内直呼:用Llama 3.1训出小模型吊打GPT-4o,简直是神来之笔!