
143亿美金买来一场空!小扎向谷歌OpenAI低头,史上最大AI赌注失速
143亿美金买来一场空!小扎向谷歌OpenAI低头,史上最大AI赌注失速从Llama 4「作弊刷分」丑闻,到143亿美元收购Scale AI,扎克伯格疯狂挖角,却换来团队内讧;上亿美元年薪,没能留住顶尖人才。Meta的超级智能实验室(MSL),到底是未来引擎,还是人心崩盘的深坑?
来自主题: AI资讯
11921 点击 2025-09-01 10:06
 搜索
搜索
从Llama 4「作弊刷分」丑闻,到143亿美元收购Scale AI,扎克伯格疯狂挖角,却换来团队内讧;上亿美元年薪,没能留住顶尖人才。Meta的超级智能实验室(MSL),到底是未来引擎,还是人心崩盘的深坑?
Meta在半年内第四次重组AI部门,将超级智能实验室拆分为四个团队,全面押注「超级智能」。新成立的TBD Lab由Alexandr Wang领衔,或放弃Llama 4并转向闭源模型,Meta开源旗帜动摇。Meta内部人心浮动,几家欢喜几家愁。
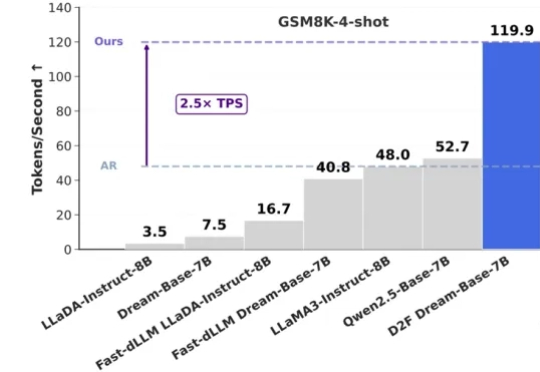
在大语言模型(LLMs)领域,自回归(AR)范式长期占据主导地位,但其逐 token 生成也带来了固有的推理效率瓶颈。此前,谷歌的 Gemini Diffusion 和字节的 Seed Diffusion 以每秒千余 Tokens 的惊人吞吐量,向业界展现了扩散大语言模型(dLLMs)在推理速度上的巨大潜力。

加拿大AI新贵Cohere获5亿美元融资、估值68亿美元,前Meta FAIR副总裁、PyTorch与Llama重要推手Joelle Pineau加盟出任首席AI官,或将开启企业AI新战局。
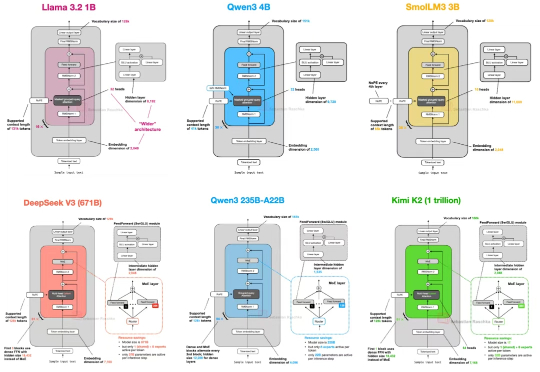
自首次提出 GPT 架构以来,转眼已经过去了七年。 如果从 2019 年的 GPT-2 出发,回顾至 2024–2025 年的 DeepSeek-V3 和 LLaMA 4,不难发现一个有趣的现象:尽管模型能力不断提升,但其整体架构在这七年中保持了高度一致。
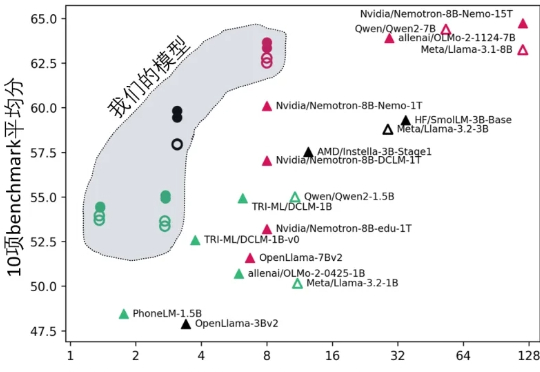
《Physics of Language Models(语言模型物理学)》,正是将AI研究带入“物理学范式”的项目,由Meta FAIR研究院的朱泽园概念化发起,并统筹设计。
众所周知,老黄不仅卖铲子(GPU),还自己下场开矿(造模型)。
从GPT-2到Llama 4,大模型这几年到底「胖」了多少?从百亿级密集参数到稀疏MoE架构,从闭源霸权到开源反击,Meta、OpenAI、Mistral、DeepSeek……群雄割据,谁能称王?
Llama惨遭抛弃!据Meta工程师透露,现在Meta内部开发都已经换掉了自家的Llama,改用Claude Sonnet写代码。

还记得今年最大风口AI与情趣用品市场碰撞出的火花吗?如广东中山的成人玩偶制造商金三玩美(WMDoll),凭借一款接入ChatGPT、Llama等大模型的AI硅胶娃娃MetaBox,惊艳了整个市场。