# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
即便是最顶尖的大模型,依然会在简单推理和常识问题上犯错。这是算法极限,还是训练范式出了问题?我们能否像物理学家一样,用客观、可控的实验揭示“AGI”本质?
《Physics of Language Models(语言模型物理学)》,正是将AI研究带入“物理学范式”的项目,由Meta FAIR研究院的朱泽园概念化发起,并统筹设计。朱泽园是LoRA技术合作者、Katyusha优化算法发明者、清华本科,麻省理工博士、Google Codejam全球编程大赛第二名、IOI两届国际金牌,论文引用超三万。他从优化理论深耕多年,现专注于AI基础理论和智能本质的科学探索。


Physics of Language Models主张,AI进步应像物理学一样,追求可复现、可归纳、可解释的“普适规律”。如牛顿和开普勒用观测与归纳总结自然定律,AI也需建立“理想实验田”:
这种范式革新,获将为后续模型设计奠定坚实理论基础。
本次开源,是Physics of Language Models自诞生以来首次将理论体系落地到实际大模型,堪称一个里程碑。用42,000 GPU小时(不到Llama3-8B的10%),从零训练出在多项benchmark上全面超越同量级真开源模型,并且超越了Llama3-8B这样的数据闭源模型。最重要的是,全链路开源数据、代码、权重和详细实验,任何人均可复现。
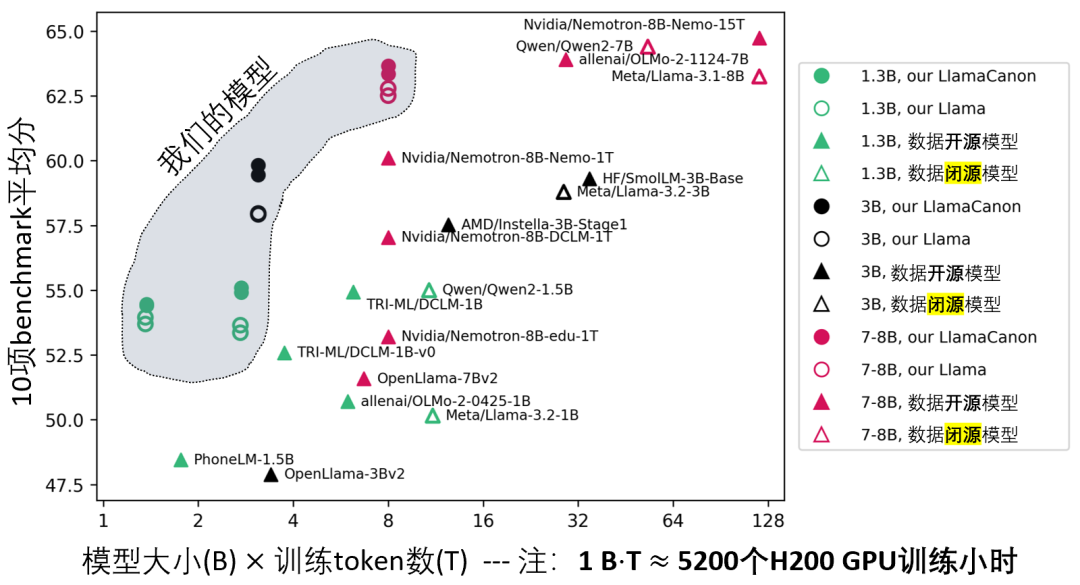
策略一(Part 3.1):多样重写+QA混合预训练,重构知识提取机制
2023年发表的Physics of LM系列 Part 3.1论文,首次揭示知识提取的极限与突破口:只有在预训练阶段引入多样化重写和QA混合数据,才能让大模型学会知识的抽取与迁移。这一发现已在2024年ICLM大会上获得高度关注,朱泽园受邀做2小时tutorial,系统讲解了LLM基础模型训练中的现象与理论,获得广泛好评。YouTube链接
值得一提的是,这两项理论指导已经在2024年12月被Nvidia团队实现,并发表为名为Nemotron-CC的开源数据。
策略二(Part 4.1):Canon层,横向信息流的革命
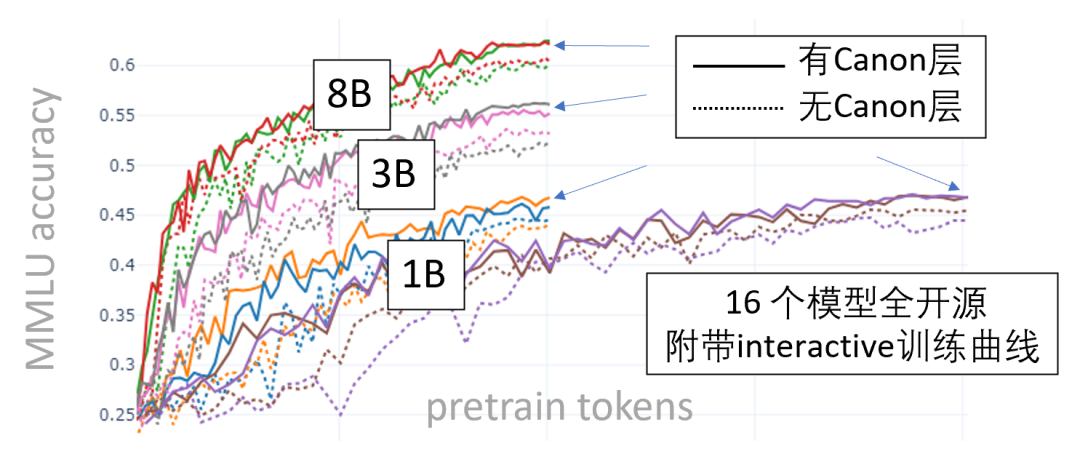
如MMLU曲线所示,仅用简单的Canon层结构,模型能力大量提升。这一发现,正是两个月前Physics of LM系列Part 4.1论文首次提出。
卡农(Canon)层的核心,是在模型内部引入横向残差连接——即使只是前几个token的简单平均,也能让Transformer推理深度提升2-4倍,推理广度和结构学习能力同步增强。Canon层极易集成主流架构,零调参、成本极低,且能显著提升长度泛化(甚至可大量替代RoPE等位置编码)。

“这或许是LLM设计的‘伽利略时刻’——可控的合成预训练实验揭示了大模型结构的极限,有望成为领域发展的分水岭。”
《Physics of Language Models》致敬科学本源。它以物理学般的客观性和学术思想传承,把AI从“只会刷榜”带入“可验证、可解释、可积累”的科学新阶段。希望每一个关注智能本质的你,都能在这个全开源实验田里,发现属于自己的规律与灵感。
请注意,此次内容已经过精心编辑,并得到了朱泽园博士的认可。欲了解更多关于朱泽园的信息,敬请访问其网站http://zeyuan.allen-zhu.com/。我们也欢迎读者通过留言互动,分享您对本文的看法。
Z Tech 将继续提供更多关于人工智能、全球化市场、机器人技术等领域的独家技术分析与学术Talk。我们诚邀对未来充满憧憬的您加入我们的Phd/Reseachers的实名社群!,与我们共同分享、学习、成长。
文章来自于微信公众号“Z Potentials”。


