LLaVA-Mini来了!每张图像所需视觉token压缩至1个,兼顾效率内存
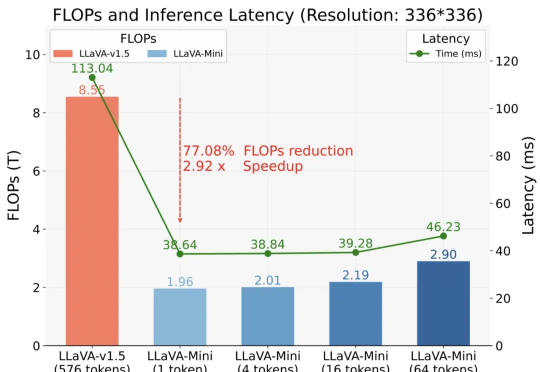
LLaVA-Mini来了!每张图像所需视觉token压缩至1个,兼顾效率内存以 GPT-4o 为代表的实时交互多模态大模型(LMMs)引发了研究者对高效 LMM 的广泛关注。现有主流模型通过将视觉输入转化为大量视觉 tokens,并将其嵌入大语言模型(LLM)上下文来实现视觉信息理解。
来自主题: AI技术研报
5219 点击 2025-02-06 15:26
 搜索
搜索
以 GPT-4o 为代表的实时交互多模态大模型(LMMs)引发了研究者对高效 LMM 的广泛关注。现有主流模型通过将视觉输入转化为大量视觉 tokens,并将其嵌入大语言模型(LLM)上下文来实现视觉信息理解。