开源模型新纪录:超越Mixtral 8x7B Instruct的模型来了
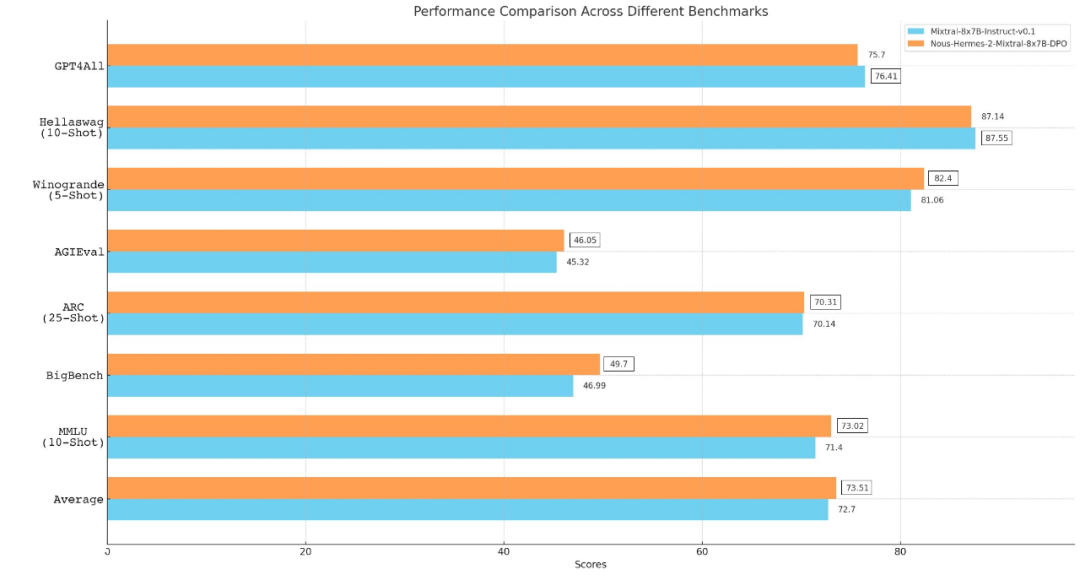
开源模型新纪录:超越Mixtral 8x7B Instruct的模型来了从 Llama、Llama 2 到 Mixtral 8x7B,开源模型的性能记录一直在被刷新。由于 Mistral 8x7B 在大多数基准测试中都优于 Llama 2 70B 和 GPT-3.5,因此它也被认为是一种「非常接近 GPT-4」的开源选项。
来自主题: AI技术研报
8422 点击 2024-01-16 14:18
 搜索
搜索
从 Llama、Llama 2 到 Mixtral 8x7B,开源模型的性能记录一直在被刷新。由于 Mistral 8x7B 在大多数基准测试中都优于 Llama 2 70B 和 GPT-3.5,因此它也被认为是一种「非常接近 GPT-4」的开源选项。

ChatGPT、OpenAI这两个名字无疑是2023年科技圈最为炙手可热的存在,但投入AI大模型赛道的显然远远不止OpenAI一家,例如谷歌有Gemini、Meta有开源的Llama 2、亚马逊也有Titan。

爆火社区的Mixtral 8x7B模型,今天终于放出了arXiv论文!所有模型细节全部公开了。

无需微调,只要四行代码就能让大模型窗口长度暴增,最高可增加3倍!而且是“即插即用”,理论上可以适配任意大模型,目前已在Mistral和Llama2上试验成功。

Vista-LLaMA 在处理长视频内容方面的显著优势,为视频分析领域带来了新的解决框架。

当大家都在研究大模型(LLM)参数规模达到百亿甚至千亿级别的同时,小巧且兼具高性能的小模型开始受到研究者的关注。

华为盘古系列,带来架构层面上新!量子位获悉,华为诺亚方舟实验室等联合推出新型大语言模型架构:盘古-π。

混合专家模型(MoE)成为最近关注的热点。

大模型打开AI新世界,Vision Pro引领空间计算,智能电车超越油车,拼多多“新王”已立,智能手机狂卷创新,新硬件层出不穷,鸿蒙系统加速壮大,AI芯片驱动万物……2023年,科技产业发生了太多重大事件。

都快到年底了,大模型领域还在卷,今天,Microsoft发布了参数量为2.7B的Phi-2——不仅13B参数以内没有对手,甚至还能和Llama 70B掰手腕!