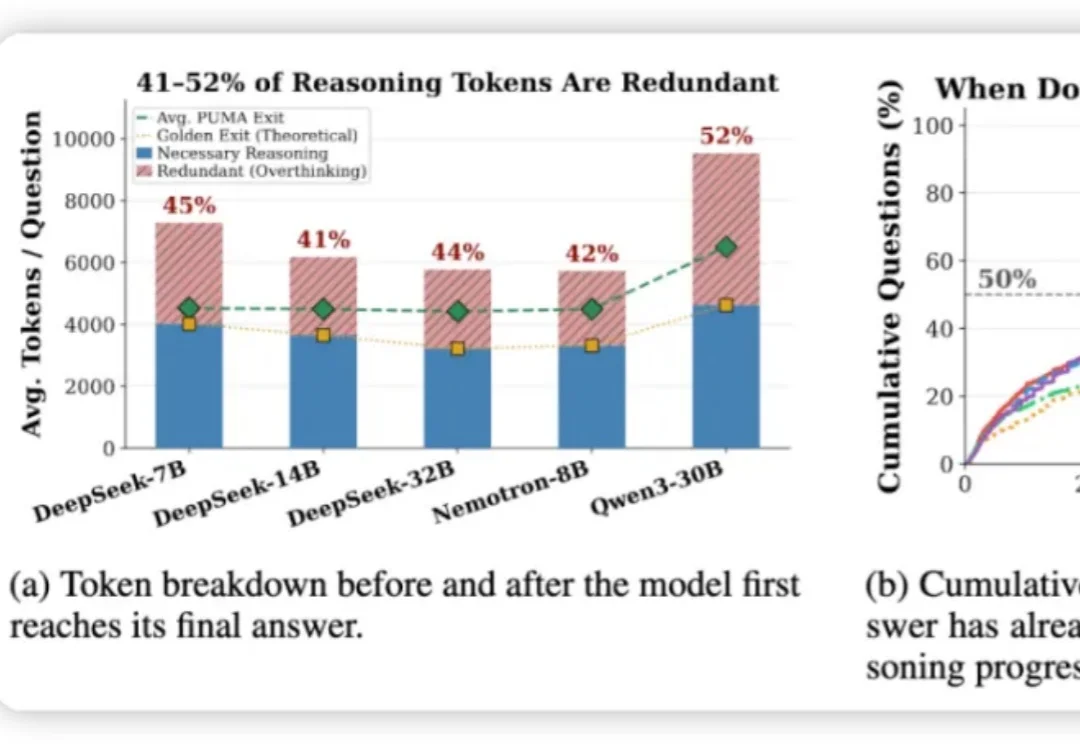
用推理步骤的「语义冗余」给LRM过度思考踩刹车
用推理步骤的「语义冗余」给LRM过度思考踩刹车推理大模型 (如 DeepSeek-R1、o1) 靠长思维链拿高分,却普遍「想太多」: 研究统计了五个代表性模型里,发现有 41–52% 的 token 是在模型给出它的最终答案之后生成的。
来自主题: AI技术研报
5898 点击 2026-07-16 10:08
 搜索
搜索
推理大模型 (如 DeepSeek-R1、o1) 靠长思维链拿高分,却普遍「想太多」: 研究统计了五个代表性模型里,发现有 41–52% 的 token 是在模型给出它的最终答案之后生成的。

当前的训练与评测范式存在一个根本性的局限:几乎所有主流 Benchmark(如 MATH500、AIME)都聚焦于孤立的单步问题,问题之间相互独立,模型只需「回答一个问题,然后结束」。但真实世界的推理场景往往截然不同: 为填补这一空白,复旦大学与美团 LongCat Team 联合推出 R-HORIZON—— 首个系统性评估与增强 LRMs 长链推理能力的方法与基准。

Tool-Calling作为Agent的核心模块,智能体的双手,这项关键能力允许 LLM 调用外部函数,例如应用程序接口(APIs)、数据库、计算器和搜索引擎,决定了AI Agent的可执行边界。
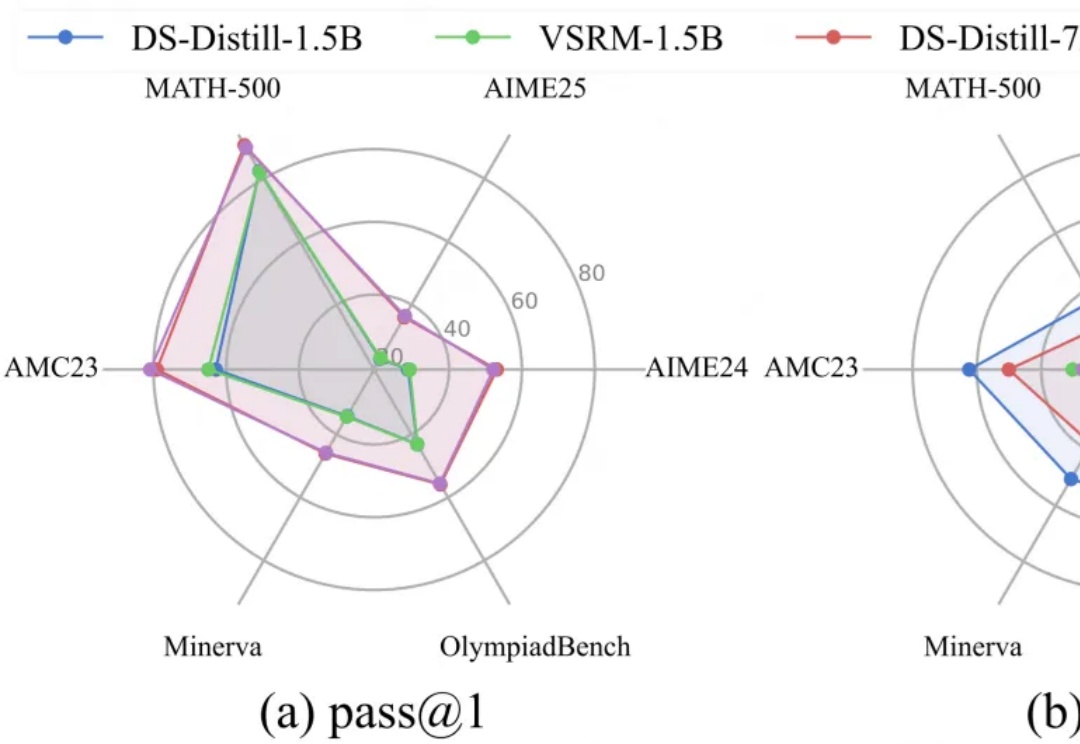
LRM通过简单却有效的RLVR范式,培养了强大的CoT推理能力,但伴随而来的冗长的输出内容,不仅显著增加推理开销,还会影响服务的吞吐量,这种消磨用户耐心的现象被称为“过度思考”问题。
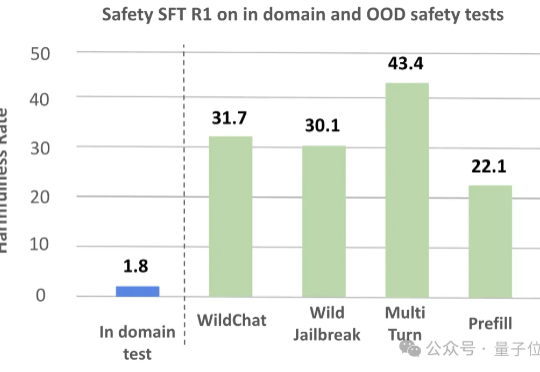
大型推理模型(LRMs)在解决复杂任务时展现出的强大能力令人惊叹,但其背后隐藏的安全风险不容忽视。
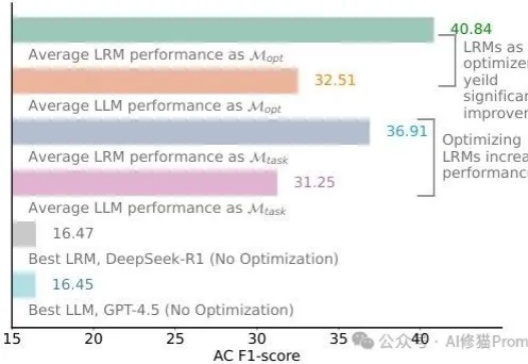
还记得DeepSeek-R1发布时AI圈的那波狂欢吗?"提示工程已死"、"再也不用费心写复杂提示了"、"推理模型已经聪明到不再需要学习提示词了"......这些观点在社交媒体上刷屏,连不少技术大佬都在转发。再到最近,“提示词写死了”......现实总是来得这么快——乔治梅森大学的研究者们用一个严谨得让人无法反驳的实验,狠狠打了所有人的脸!
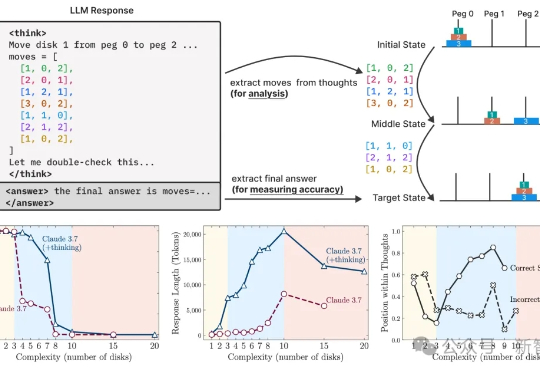
苹果最新研究揭示大推理模型(LRM)在高复杂度任务中普遍「推理崩溃」:思考路径虽长,却常在关键时刻放弃。即便给予明确算法提示,模型亦无法稳定执行,暴露推理机制的局限性。
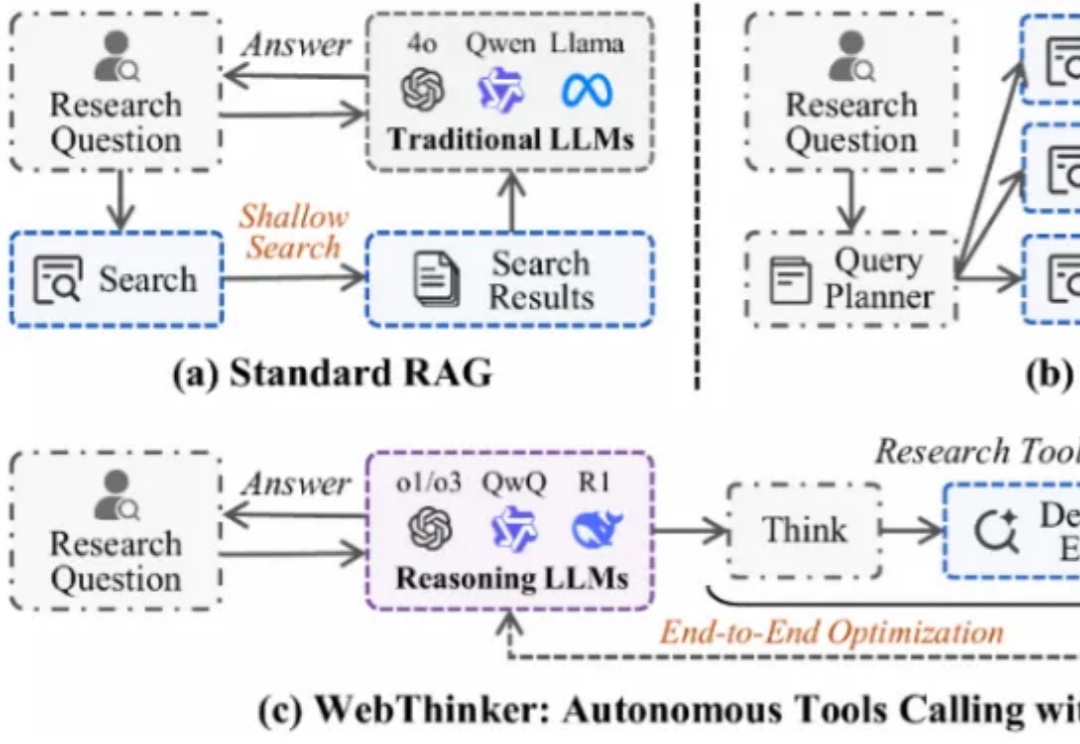
大型推理模型(如 OpenAI-o1、DeepSeek-R1)展现了强大的推理能力,但其静态知识限制了在复杂知识密集型任务及全面报告生成中的表现。为应对此挑战,深度研究智能体 WebThinker 赋予 LRM 在推理中自主搜索网络、导航网页及撰写报告的能力。
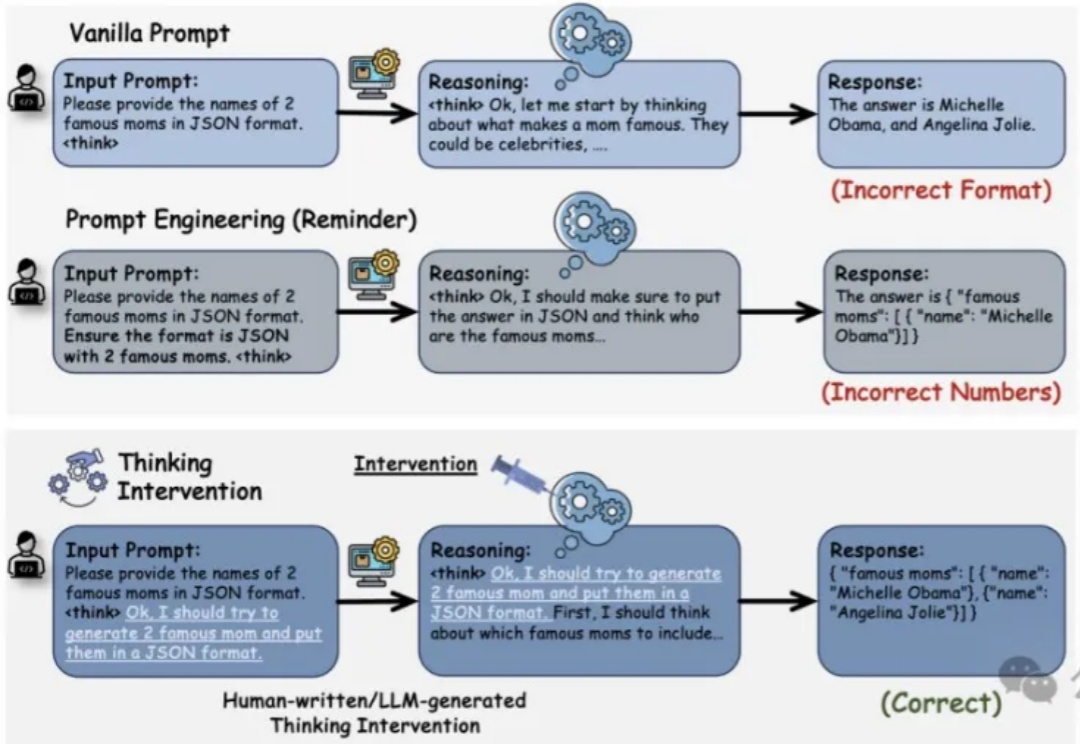
推理增强型大语言模型LRM(如OpenAI的o1、DeepSeek R1和Google的Flash Thinking)通过在生成最终答案前显式生成中间推理步骤,在复杂问题解决方面展现了卓越性能。然而,对这类模型的控制仍主要依赖于传统的输入级操作,如提示工程(Prompt Engineering)等方法,而你可能已经发现这些方法存在局限性。
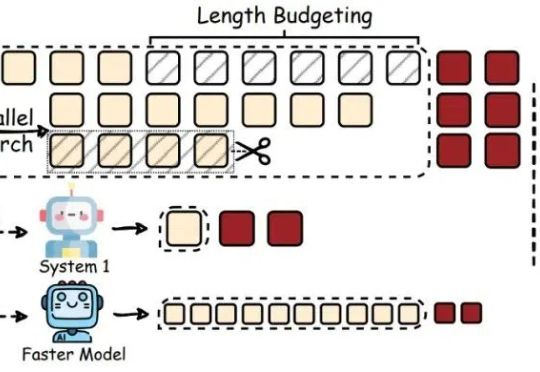
最近,像 OpenAI o1/o3、DeepSeek-R1 这样的大型推理模型(Large Reasoning Models,LRMs)通过加长「思考链」(Chain-of-Thought,CoT)在推理任务上表现惊艳。