Claude Code 破译了一门 3500 年前的语言
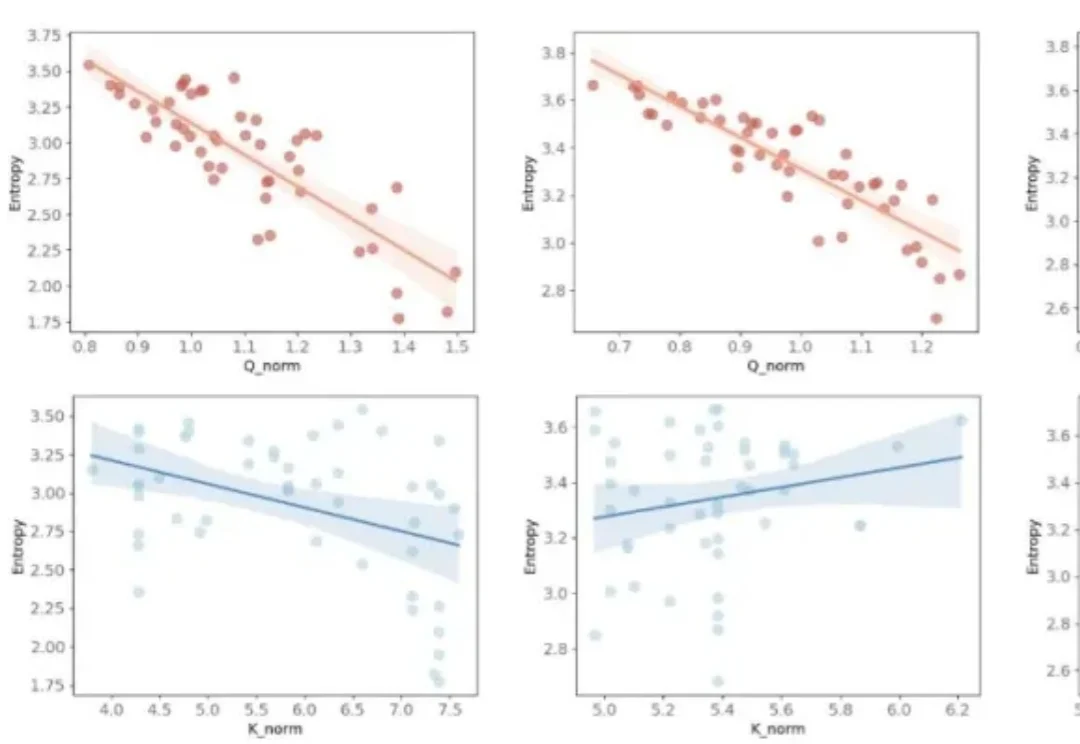
Claude Code 破译了一门 3500 年前的语言有人声称用 Claude Code 破译了 Linear A,一种来自克里特岛、已经沉默了 3500 年的古老文字。Claude Code 之父 Boris Cherny,也发文宣告了这个酷炫玩法:它是青铜时代米诺斯文明使用的书写系统,大约从公元前 1800 年开始出现,一直用到公元前 1450 年迈锡尼希腊人征服克里特岛为止。
来自主题: AI资讯
10195 点击 2026-06-20 14:55