
「越狱」事件频发,如何教会大模型「迷途知返」而不是「将错就错」?
「越狱」事件频发,如何教会大模型「迷途知返」而不是「将错就错」?大型语言模型(LLM)展现出了令人印象深刻的智能水平。因此,确保其安全性显得至关重要。已有研究提出了各种策略,以使 LLM 与人类伦理道德对齐。然而,当前的先进模型例如 GPT-4 和 LLaMA3-70b-Instruct 仍然容易受到越狱攻击,并被用于恶意用途。
来自主题: AI技术研报
10553 点击 2024-07-30 16:55
 搜索
搜索
大型语言模型(LLM)展现出了令人印象深刻的智能水平。因此,确保其安全性显得至关重要。已有研究提出了各种策略,以使 LLM 与人类伦理道德对齐。然而,当前的先进模型例如 GPT-4 和 LLaMA3-70b-Instruct 仍然容易受到越狱攻击,并被用于恶意用途。

24点游戏、几何图形、一步将死问题,这些推理密集型任务,难倒了一片大模型,怎么破?北大、UC伯克利、斯坦福研究者最近提出了一种全新的BoT方法,用思维模板大幅增强了推理性能。而Llama3-8B在BoT的加持下,竟多次超越Llama3-70B!
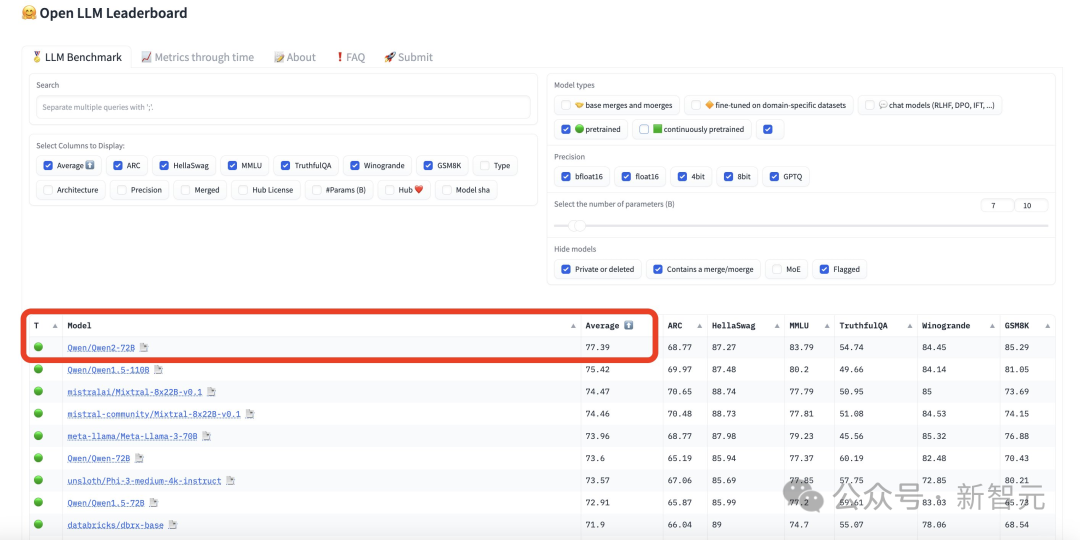
一夜之间,全球最强开源模型再次易主。万众瞩目的Qwen2-72B一出世,火速杀进开源LLM排行榜第一,美国最强开源模型Llama3-70B直接被碾压!全球开发者粉丝狂欢:果然没白等。

两周前,OpenBMB开源社区联合面壁智能发布领先的开源大模型「Eurux-8x22B 」。相比口碑之作 Llama3-70B,Eurux-8x22B 发布时间更早,综合性能相当,尤其是拥有更强的推理性能——刷新开源大模型推理性能 SOTA,堪称开源大模型中「理科状元」。