
Mamba作者新作:将Llama3蒸馏成混合线性 RNN
Mamba作者新作:将Llama3蒸馏成混合线性 RNNTransformer 在深度学习领域取得巨大成功的关键是注意力机制。注意力机制让基于 Transformer 的模型关注与输入序列相关的部分,实现了更好的上下文理解。然而,注意力机制的缺点是计算开销大,会随输入规模而二次增长,Transformer 也因此难以处理非常长的文本。
来自主题: AI技术研报
9984 点击 2024-08-31 14:54
 搜索
搜索
Transformer 在深度学习领域取得巨大成功的关键是注意力机制。注意力机制让基于 Transformer 的模型关注与输入序列相关的部分,实现了更好的上下文理解。然而,注意力机制的缺点是计算开销大,会随输入规模而二次增长,Transformer 也因此难以处理非常长的文本。

Meta的开源大模型Llama 3在市场上遇冷,进一步加剧了大模型开源与闭源之争的关注热度。
Llama3.1系列模型的开源,真让大模型格局大震,指标上堪比最好的闭源模型比如GPT 4o和Claude3.5,让开源追赶闭源成为现实。

把Llama 3.1 405B和Claude 3超大杯Opus双双送进小黑屋,你猜怎么着——

伴随大模型迭代速度越来越快,训练集群规模越来越大,高频率的软硬件故障已经成为阻碍训练效率进一步提高的痛点,检查点(Checkpoint)系统在训练过程中负责状态的存储和恢复,已经成为克服训练故障、保障训练进度和提高训练效率的关键。

从前两年的百模大战到大语言模型 LLM(Large Language Model)的逐步落地应用,端侧AI始终是人工智能技术发展中至关重要的一环。 所谓的端侧AI,即用户在使用过程中不依赖云服务器,直接在终端设备本地使用AI服务。相比于ChatGPT4.0和最新推出的Llama3.1等依赖于云端接口的主流大语言模型,设备端边缘应用的紧凑模型有较强的私密性,也具有个性化操作和节省成本等诸多优势。

大模型作为当下 AI 工业界和学术界当之无愧的「流量之王」,吸引了大批学者和企业投入资源去研究与训练。随着规模越做越大,系统和工程问题已经成了大模型训练中绕不开的难题。例如在 Llama3.1 54 天的训练里,系统会崩溃 466 次,平均 2.78 小时一次!
不同类型的数据配比如何配置:先通过小规模实验确定最优配比,然后将其应用到大模型的训练中。 Token配比结论:通用知识50%;数学与逻辑25%;代码17%;多语言8%。

大型语言模型(LLM)展现出了令人印象深刻的智能水平。因此,确保其安全性显得至关重要。已有研究提出了各种策略,以使 LLM 与人类伦理道德对齐。然而,当前的先进模型例如 GPT-4 和 LLaMA3-70b-Instruct 仍然容易受到越狱攻击,并被用于恶意用途。
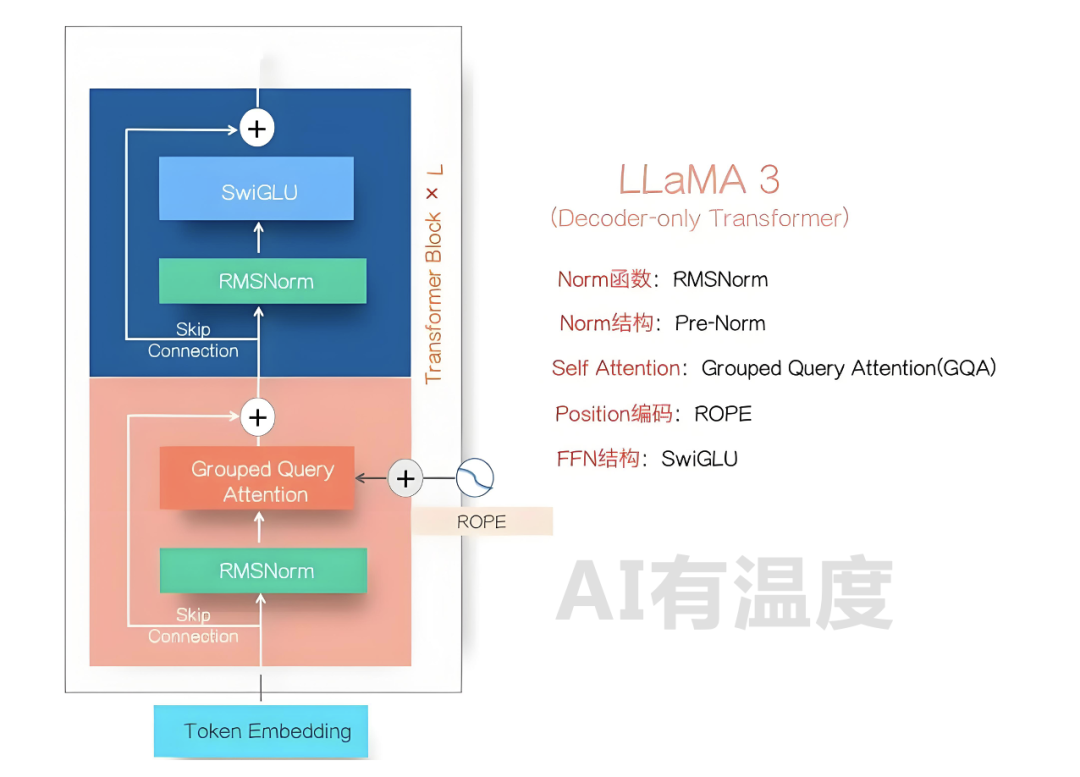
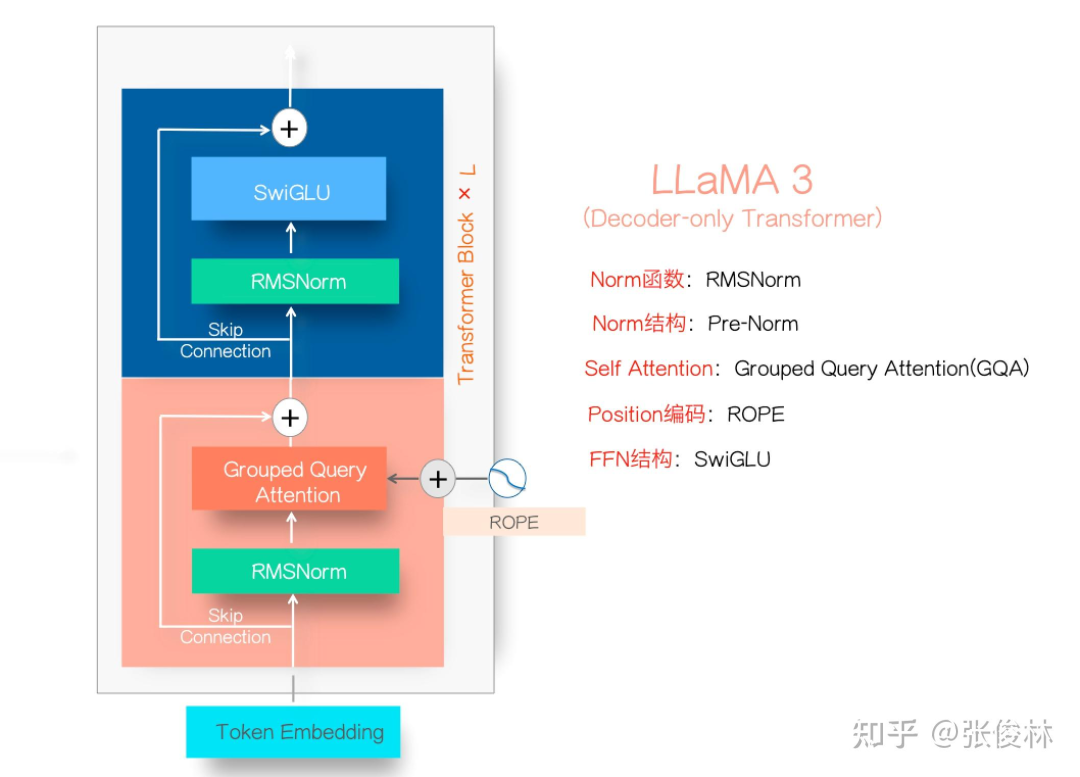
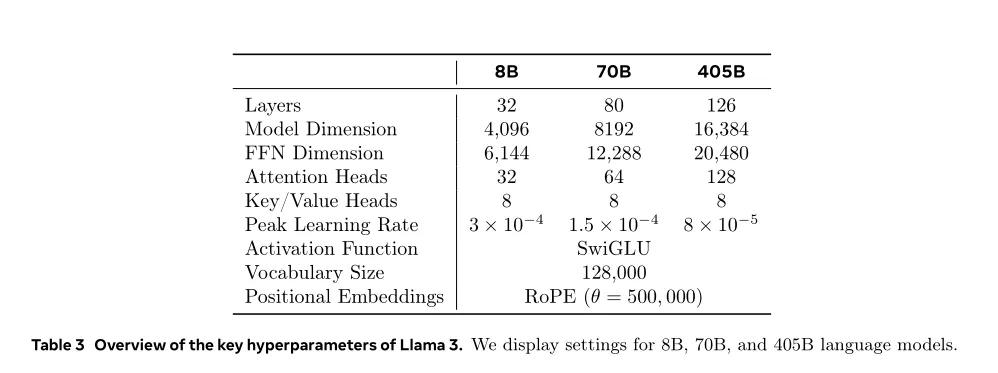
LLaMA3-405B的模型效果已经赶上目前最好的闭源模型GPT-4o和Claude-3.5,这可能是未来大模型开源与闭源的拐点,这里就LLaMA3的模型结构、训练过程与未来影响等方面说说我的看法。