“在线版FLUX”已支持ControlNet,无需部署开箱即用,还能在线训练LoRA模块
“在线版FLUX”已支持ControlNet,无需部署开箱即用,还能在线训练LoRA模块“FLUX在线版”,新增一系列重磅功能!
来自主题: AI资讯
12689 点击 2024-08-16 21:19
 搜索
搜索
“FLUX在线版”,新增一系列重磅功能!

低秩适应(Low-Rank Adaptation,LoRA)通过可插拔的低秩矩阵更新密集神经网络层,是当前参数高效微调范式中表现最佳的方法之一。此外,它在跨任务泛化和隐私保护方面具有显著优势。
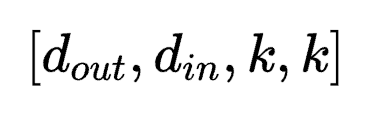
为了让大模型在特定任务、场景下发挥更大作用,LoRA这样能够平衡性能和算力资源的方法正在受到研究者们的青睐。

大模型应用开卷,连一向保守的苹果,都已释放出发展端侧大模型的信号。

美国东北大学的计算机科学家 David Bau 非常熟悉这样一个想法:计算机系统变得如此复杂,以至于很难跟踪它们的运行方式。

本文介绍了香港科技大学(广州)的一篇关于大模型高效微调(LLM PEFT Fine-tuning)的文章「Parameter-Efficient Fine-Tuning with Discrete Fourier Transform」
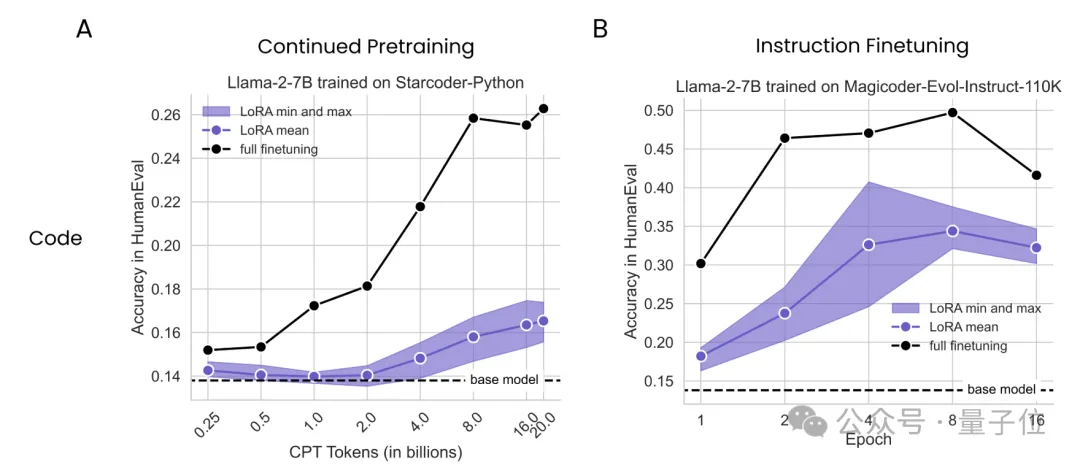
大数据巨头Databricks与哥伦比亚大学最新研究发现,在数学和编程任务上,LoRA干不过全量微调。
堂堂开源之王Llama 3,原版上下文窗口居然只有……8k,让到嘴边的一句“真香”又咽回去了。

我们知道,Meta 推出的 Llama 3、Mistral AI 推出的 Mistral 和 Mixtral 模型以及 AI21 实验室推出的 Jamba 等开源大语言模型已经成为 OpenAI 的竞争对手。

随着大模型的参数量日益增长,微调整个模型的开销逐渐变得难以接受。 为此,北京大学的研究团队提出了一种名为 PiSSA 的参数高效微调方法,在主流数据集上都超过了目前广泛使用的 LoRA 的微调效果。