纯文本驱动视频编辑,清华&华为&中科大实现无需掩码/参考帧就能精准移除/添加对象
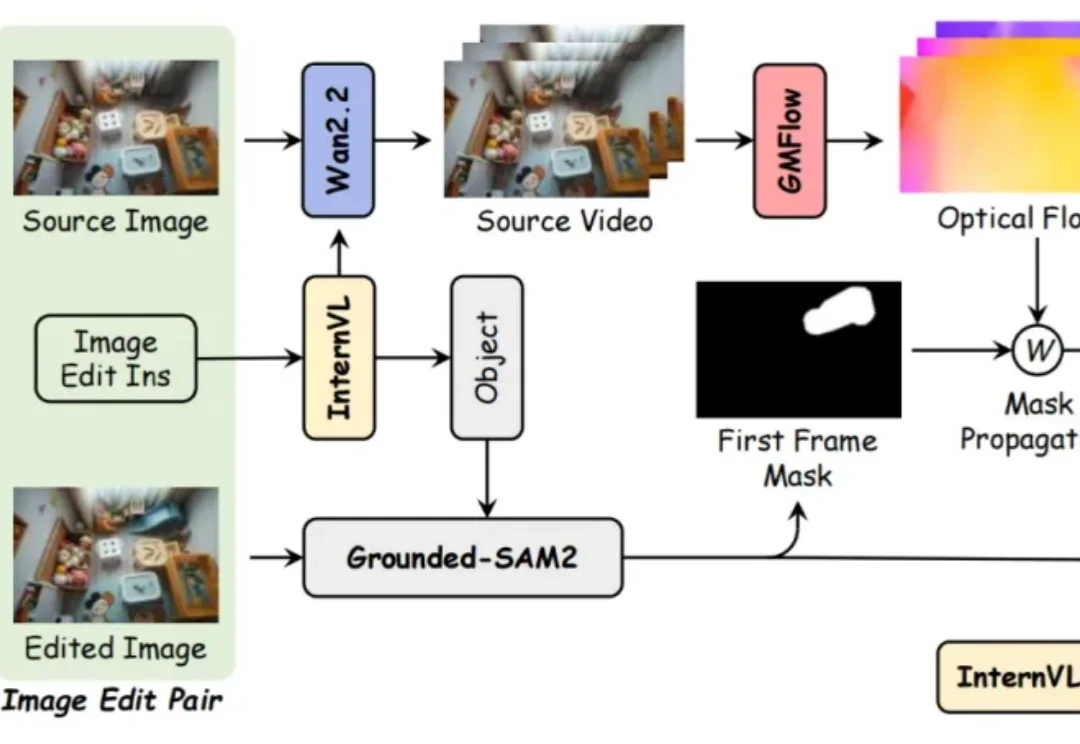
纯文本驱动视频编辑,清华&华为&中科大实现无需掩码/参考帧就能精准移除/添加对象近年来,基于扩散的视频生成模型的最新进展极大地提高了视频编辑的真实感和可控性。然而,文字驱动的视频对象移除添加依然面临巨大挑战:
来自主题: AI技术研报
8478 点击 2025-12-12 09:37
 搜索
搜索
近年来,基于扩散的视频生成模型的最新进展极大地提高了视频编辑的真实感和可控性。然而,文字驱动的视频对象移除添加依然面临巨大挑战: