
MBench: 清华x腾讯联合定义视频世界模型的长期记忆能力
MBench: 清华x腾讯联合定义视频世界模型的长期记忆能力随着视频生成技术的发展,模型正在从短视频片段合成,向流式长视频生成演进。然而,仅仅做到视觉上的逼真是不够的。一个功能完备的视频世界模型,必须能够在长时序交互中保持稳定的内部状态,并遵循真实世界的物理定律与逻辑规则。
来自主题: AI技术研报
9728 点击 2026-06-11 14:30
 搜索
搜索
随着视频生成技术的发展,模型正在从短视频片段合成,向流式长视频生成演进。然而,仅仅做到视觉上的逼真是不够的。一个功能完备的视频世界模型,必须能够在长时序交互中保持稳定的内部状态,并遵循真实世界的物理定律与逻辑规则。
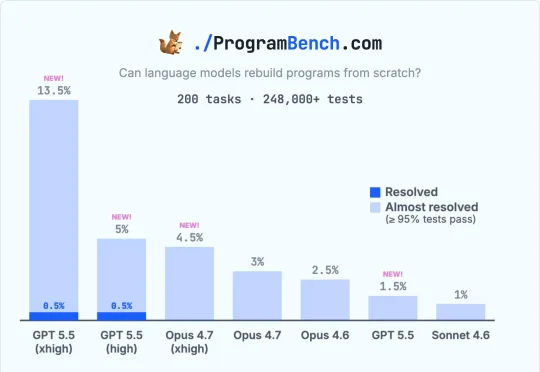
全网AI交白卷的地狱级基准,被GPT-5.5拿下一血!开局0源码盲写程序,拉满推理算力直接满血通关。传统代码测试已废,通往ASI的算力狂飙正式打响。

SWE-Bench上能拿72%的模型,换张考卷直接归零!Meta联合斯坦福、哈佛放出ProgramBench,200个项目从零手写,9大顶级模型完整通过率0%。最强的Claude Opus 4.7平均通过率也才51.2%。更离谱的是一联网,就有模型在36%的任务里跑去GitHub扒源码。
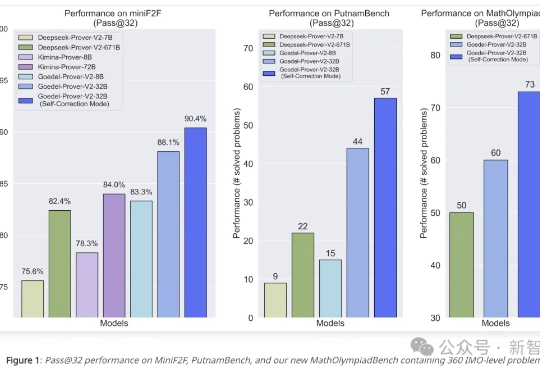
迄今为止最强大的开源定理证明器登场!Goedel-Prover-V2仅用8B参数击败671B的DeepSeek-Prover,并再次夺下数学PutnamBench冠军。十位核心贡献者,八大顶尖机构,让AI形式化证明再破纪录。

近来风头正盛的GPT-4.5,不仅在日常问答中展现出惊人的上下文连贯性,在设计、咨询等需要高度创造力的任务中也大放异彩。
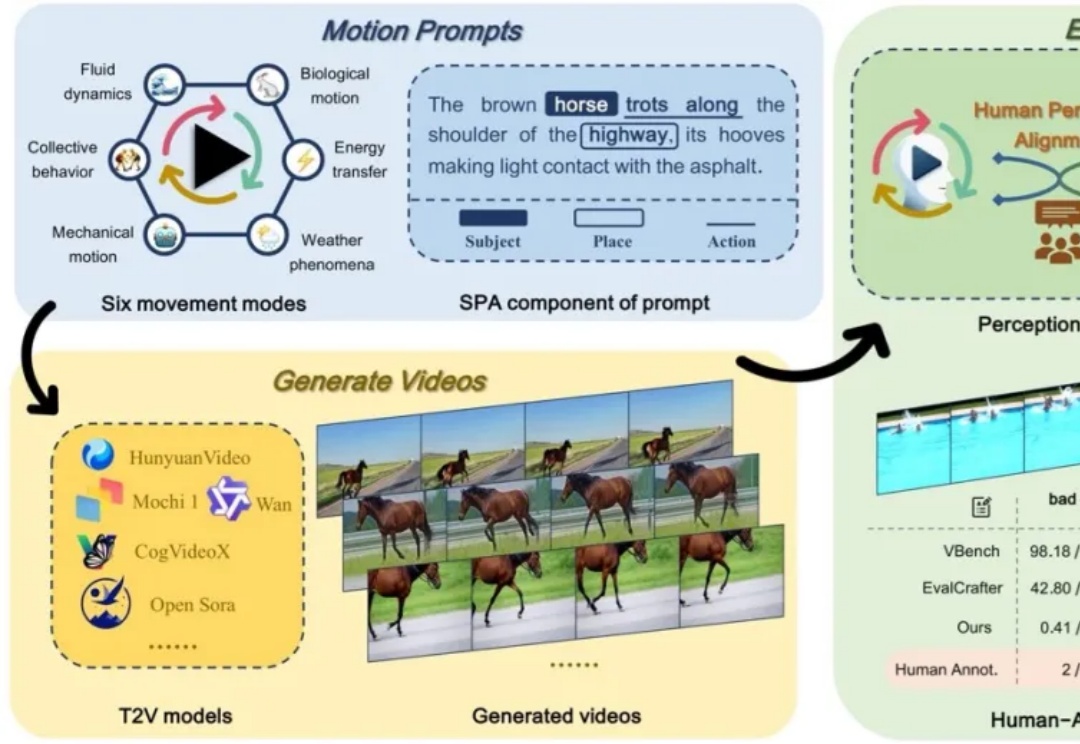
测一测现有AI生成视频是否符合物理运动规律!

GPT-4o 四月发布会掀起了视频理解的热潮,而开源领军者Qwen2也对视频毫不手软,在各个视频评测基准上狠狠秀了一把肌肉。

面对层出不穷的个性化图像生成技术,一个新问题摆在眼前:缺乏统一标准来衡量这些生成的图片是否符合人们的喜好。对此,来自清华、西交大、伊利诺伊厄巴纳-香槟分校、中科院、旷视的研究人员共同推出了一项新基准DreamBench++。