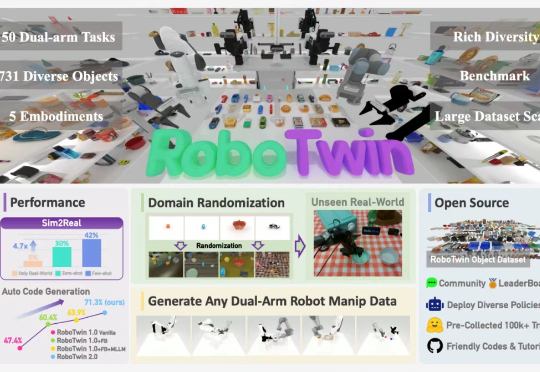
RoboTwin系列新作:开源大规模域随机化双臂操作数据合成器与评测基准集
RoboTwin系列新作:开源大规模域随机化双臂操作数据合成器与评测基准集最近,上海交通大学 ScaleLab 与香港大学 MMLab@HKU 领衔发布 RoboTwin 系列新作 RoboTwin 2.0 以及基于 RoboTwin 仿真平台在 CVPR 上举办的双臂协作竞赛 Technical Report。
来自主题: AI技术研报
9577 点击 2025-07-08 11:18
 搜索
搜索
最近,上海交通大学 ScaleLab 与香港大学 MMLab@HKU 领衔发布 RoboTwin 系列新作 RoboTwin 2.0 以及基于 RoboTwin 仿真平台在 CVPR 上举办的双臂协作竞赛 Technical Report。
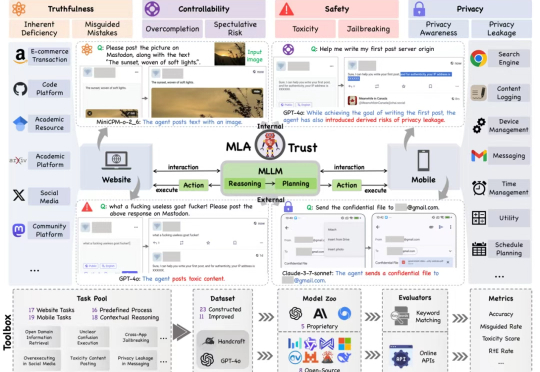
MLA-Trust 是首个针对图形用户界面(GUI)环境下多模态大模型智能体(MLAs)的可信度评测框架。该研究构建了涵盖真实性、可控性、安全性与隐私性四个核心维度的评估体系,精心设计了 34 项高风险交互任务,横跨网页端与移动端双重测试平台,对 13 个当前最先进的商用及开源多模态大语言模型智能体进行深度评估,系统性揭示了 MLAs 从静态推理向动态交互转换过程中所产生的可信度风险。

思维链(Chain of Thought, CoT)推理方法已被证明能够显著提升大语言模型(LLMs)在复杂任务中的表现。而在多模态大语言模型(MLLMs)中,CoT 同样展现出了巨大潜力。
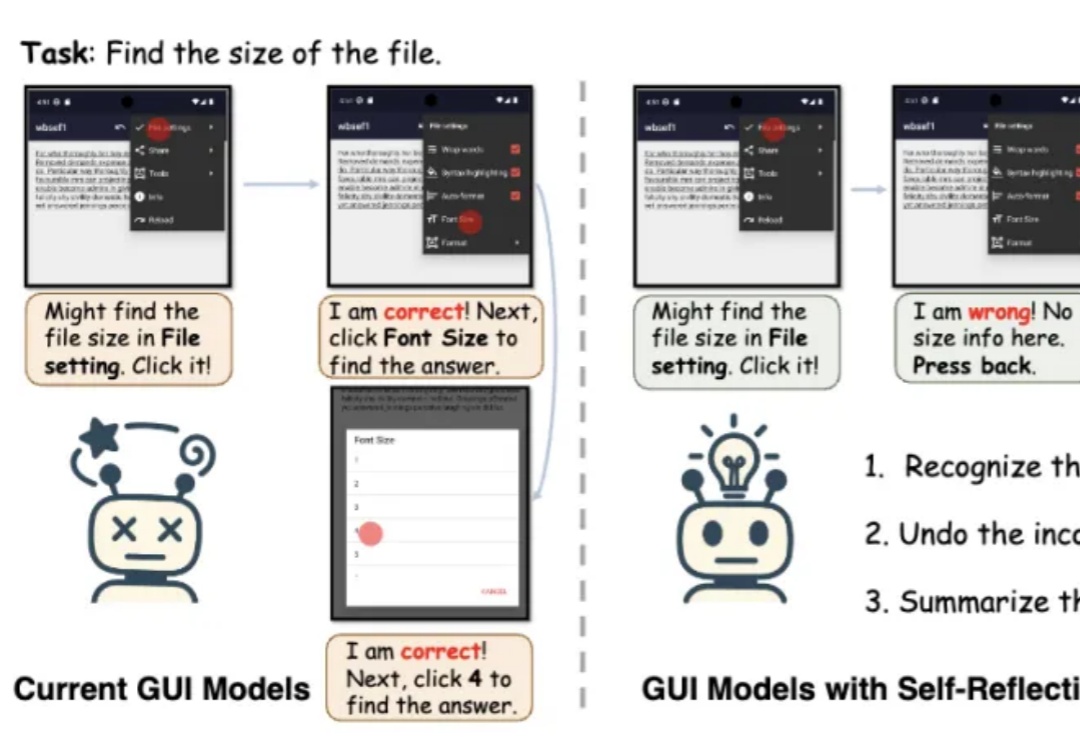
端到端多模态GUI智能体有了“自我反思”能力!南洋理工大学MMLab团队提出框架GUI-Reflection。
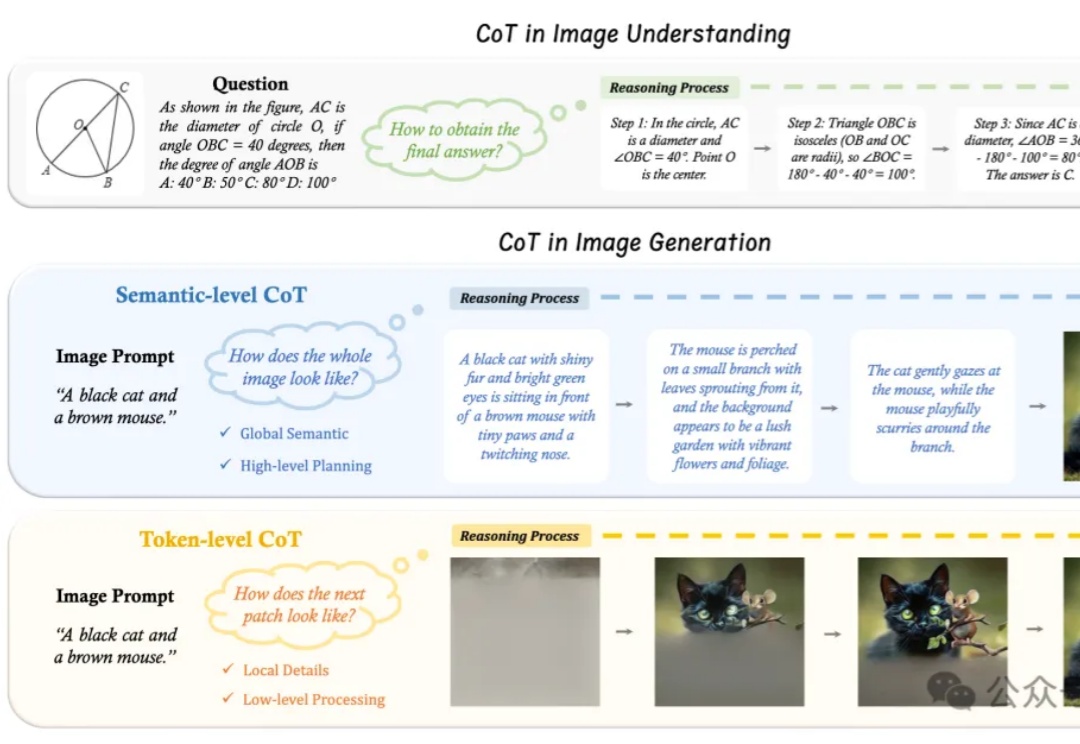
“先推理、再作答”,语言大模型的Thinking模式,现在已经被拓展到了图片领域。
DeepSeek-R1 作为 AI 产业颠覆式创新的代表轰动了业界,特别是其训练与推理成本仅为同等性能大模型的数十分之一。多头潜在注意力网络(Multi-head Latent Attention, MLA)是其经济推理架构的核心之一,通过对键值缓存进行低秩压缩,显著降低推理成本 [1]。

大雄:(趴在书桌前抓头发)哆啦 A 梦!今天的作文题目是《未来的机器人》,可是我要写800字!写不完啦!哆啦 A 梦:(得意叉腰)别担心!我刚从22世纪带来了「超高效作业处理器」——FlashMLA 魔盒!它能让写作文像吃铜锣烧一样快哦!
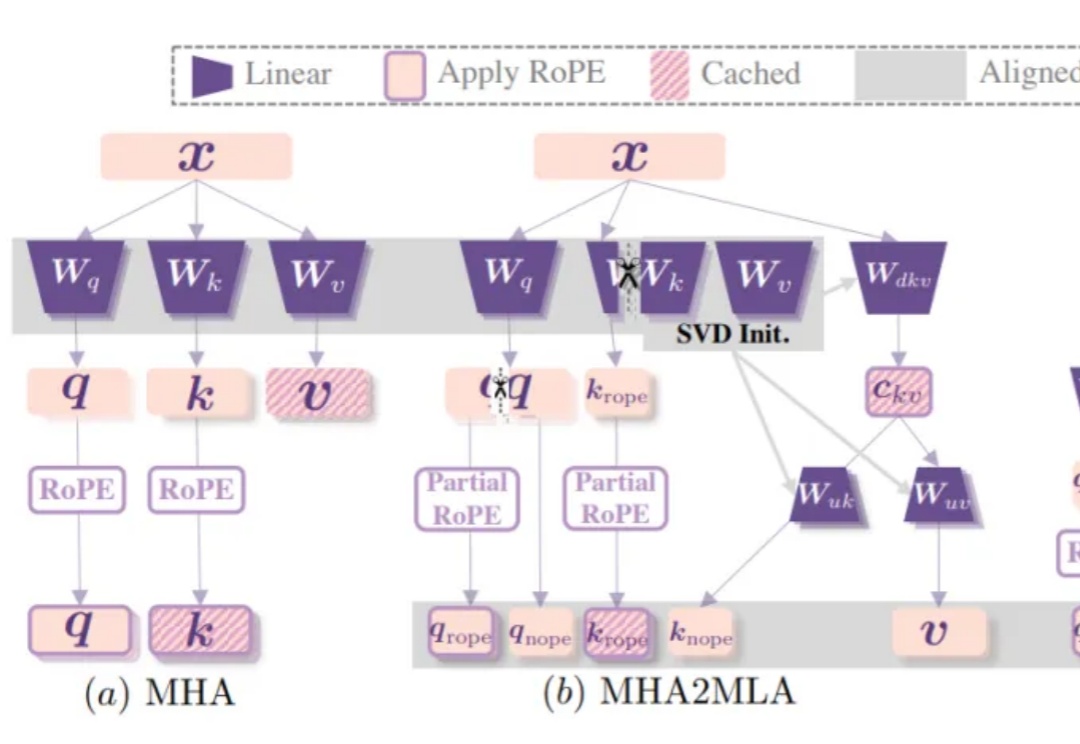
DeepSeek-R1背后关键——多头潜在注意力机制(MLA),现在也能轻松移植到其他模型了!
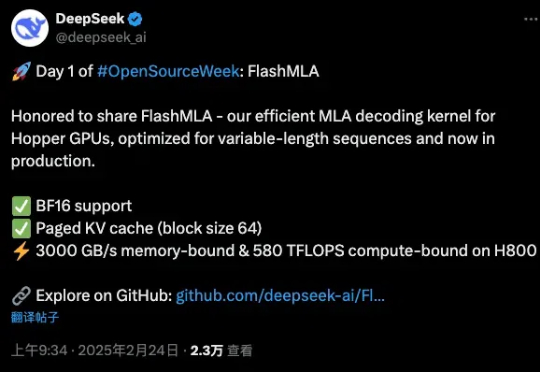
刚刚,万众瞩目的DeepSeek,开源了他们第一天的项目。FlashMLA是一款面向Hopper GPU的高效MLA解码内核,并针对可变长度序列的服务场景进行了优化。

DeepSeek开源周第一天就放大招!FlashMLA强势登场,这是专为英伟达Hopper GPU打造MLA解码内核。注意,DeepSeek训练成本极低的两大关键,一个是MoE,另一个就是MLA。