# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
刚刚,万众瞩目的DeepSeek,开源了他们第一天的项目。
开源地址在此:
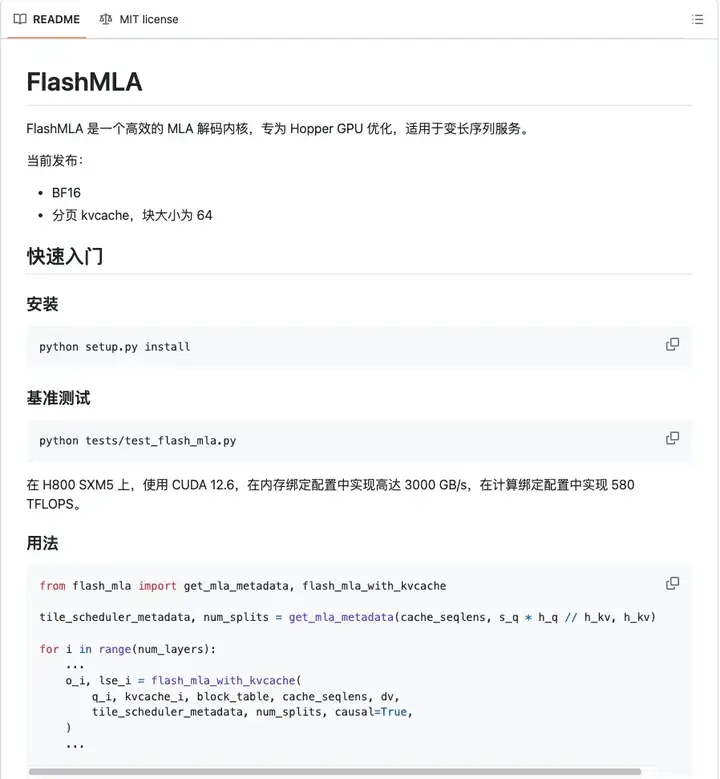
https://github.com/deepseek-ai/FlashMLA
开源的是一个叫FlashMLA的东西。
不到半小时,Github已经已经300多Star了。
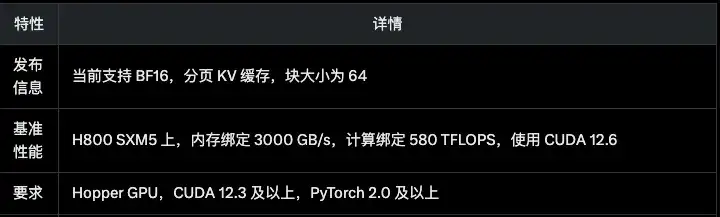
几个参数:
核心的一句话是:
“FlashMLA is an efficient MLA decoding kernel for Hopper GPUs, optimized for variable-length sequences serving.”
翻译过来就是:FlashMLA是一款面向Hopper GPU的高效MLA解码内核,并针对可变长度序列的服务场景进行了优化。
因为确实比较硬核,我只能说用我仅有的知识,给大家简单科普一下这是个啥,可能会有错误,不保证对,如果出现错误欢迎大佬评论区拍砖。
把这句话拆解一下。
“MLA decoding kernel”。
这里的“MLA”指的是Multi-head Latent Attention,多头潜在注意力,DeepSeek降低成本的王炸,反正它是个专门用来做解码阶段的注意力加速器。
大模型有两个主要阶段:训练(包括prefill)和推理解码(infer decoding)。在解码阶段,我们往往需要一次一次地拿KV缓存出来,反复计算,所以当序列变长之后,这部分开销会爆炸似的增长。如果能在解码阶段有更强的核去优化,意味着你的大模型可以更快地产出结果,特别对像这种长上下文对话就很关键。
第二,“for Hopper GPUs”。
英伟达的卡有几个架构,包括A架构和H架构。
A是Ampere架构(2020年发布),是NVIDIA的第七代GPU架构,主打通用计算和高性能AI训练/推理,典型代表型号为A100。
H代表Hopper架构(2022年发布),是NVIDIA的第九代架构(跳过第八代),目前最新的,专为超大规模AI和超算设计,显著优化了Transformer模型性能,典型的就是H100,不过因为国内问题,能用到的都是阉割版的H800。
所以,大家就可以明白,FlashMLA是DeepSeek专门针对NVIDIA H800这一代高端加速卡做的深度优化。
他们在release note里还说跑在H800上能达到“3000 GB/s memory-bound & 580 TFLOPS compute-bound”,这等于在“内存带宽”和“浮点算力”两方面都拉到极限了。基本已经是我见过的最逼近巅峰的了。
他们在致谢了写了灵感来自于FlashAttention。
我就去翻了下那个项目。
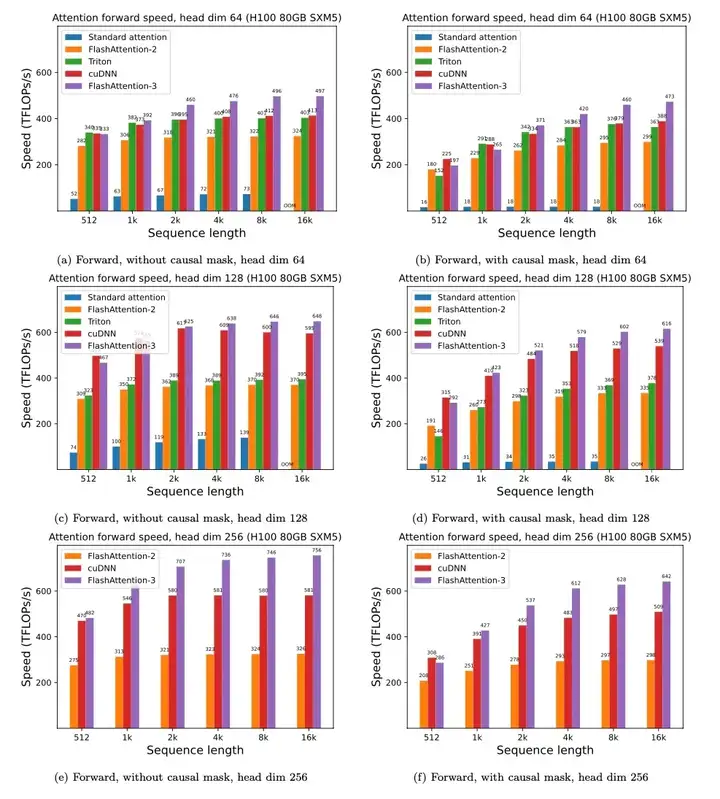
相比FlashAttention-2,FlashMLA接近翻了2倍,甚至都能跟FlashAttention-3还差点,而别人是H100优化的,DeepSeek是针对H800优化的。
第三,“optimized for variable-length sequences.” 。
就是说它不仅仅适合固定batch,还对那种“每个人输入长度不一样,随时变更token长度”的场景特别好。
因为就大模型的实际应用而言,用户往往输入并不规则,随时来个长上下文对话或者给你干上去一个超长PDF,这就需要内核支持“动态序列”,同时还能保持高效,而这块,DeepSeek也做了大幅的优化。
目前整体上也可以开箱即用。
DeepSeek这是真的把自己最牛逼的东西开源出来了。
这尼玛,才是真正的OpenAI啊。
想起来了他们前几天发的论文《Native Sparse Attention: Hardware-Aligned and Natively Trainable Sparse Attention》,整个目标也都是有异曲同工之妙。

如果说FlashMLA是针对推理解码做的“终极性能爆破”,那么Native Sparse Attention就是对训练和推理做更全面的“稀疏化改革”。
两者结合到一起,意思就是DeepSeek在告诉你。
“无论训练还是推理,我都要把硬件榨干,要做就做最猛的AI。”
对于整个AI生态来说,这是一件天大的好事。
特别是国内。
越多的开源优化,意味着以后大家都可以在高效注意力、稀疏推理、长上下文训练等方面取得突破,不用像过去那样闭源大厂独家享受。
如果你是小白或者纯产品经理,可以把这件事情当做:
苹果又给iPhone做了一个专门的GPU调教,所以游戏跑得更爽了。
只不过,这次是DeepSeek在给AI大模型做专门的GPU调教,把H800的极限性能都薅出来,换来更快的推理和训练速度。
这是妥妥的GPU性能红利。
所以我对DeepSeek挺佩服,敢搞硬件极限那一套,敢把论文跟开源项目一起放出来,而且频率这么高。
而且这还只是第一天。
后面还有四天,不敢想他们还会放出来多牛逼的东西出来。。
希望这篇小白友好版的文章能让你对FlashMLA有个更直观的理解。
既然没卡,没有资源。
那我们自己,就特娘的打下那一片天。
感谢DeepSeek。
你才是真正的源神。
文章来自微信公众号 “ 数字生命卡兹克 “



