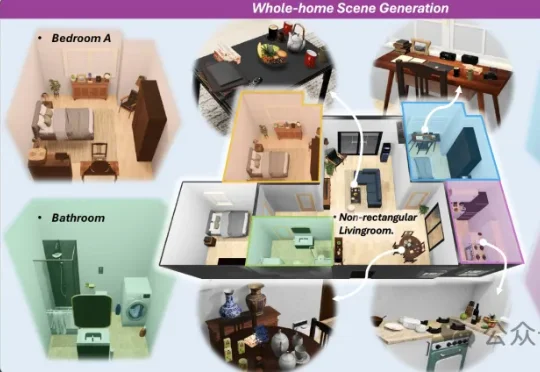
超越Figure AI!全球首个机器人训练楼盘开盘:30万套中国住宅,机器人拎包入住
超越Figure AI!全球首个机器人训练楼盘开盘:30万套中国住宅,机器人拎包入住一觉睡醒,具身智能公司竟然也开始搞房地产了?!刚刚,大晓机器人联合港中文MMLab发布了一个新项目——Kairos-Homeworld,全球首个实现全屋三维生成与物体级全交互的统一框架。
来自主题: AI技术研报
8053 点击 2026-06-06 09:47
 搜索
搜索
一觉睡醒,具身智能公司竟然也开始搞房地产了?!刚刚,大晓机器人联合港中文MMLab发布了一个新项目——Kairos-Homeworld,全球首个实现全屋三维生成与物体级全交互的统一框架。

近日,由香港科技大学 MMLab 及合作团队完成的研究工作「UniVidX: A Unified Multimodal Framework for Versatile Video Generation via Diffusion Priors」被计算机图形学顶级会议 SIGGRAPH 2026 正式接收。

南洋理工大学MMLab团队推出Hand2World,让AI世界模型真正「伸手」互动。只需在空中比划手势,模型就能生成逼真第一人称交互视频,实时响应调整。它摒弃旧有遮挡误导,用3D手部结构与射线编码解耦手与头运动,首次实现闭环持续交互。

MMLab@NTU联合中山大学的最新研究,给出了一份从入门到精通的终极“菜谱”——VLANeXt。这项研究没有简单提出一个新模型了事,而是系统性地从12个关键维度,深度剖析了VLA的设计空间。从基础组件到感知要素,再到动作建模的额外视角,每一步都有扎实的实验支撑。
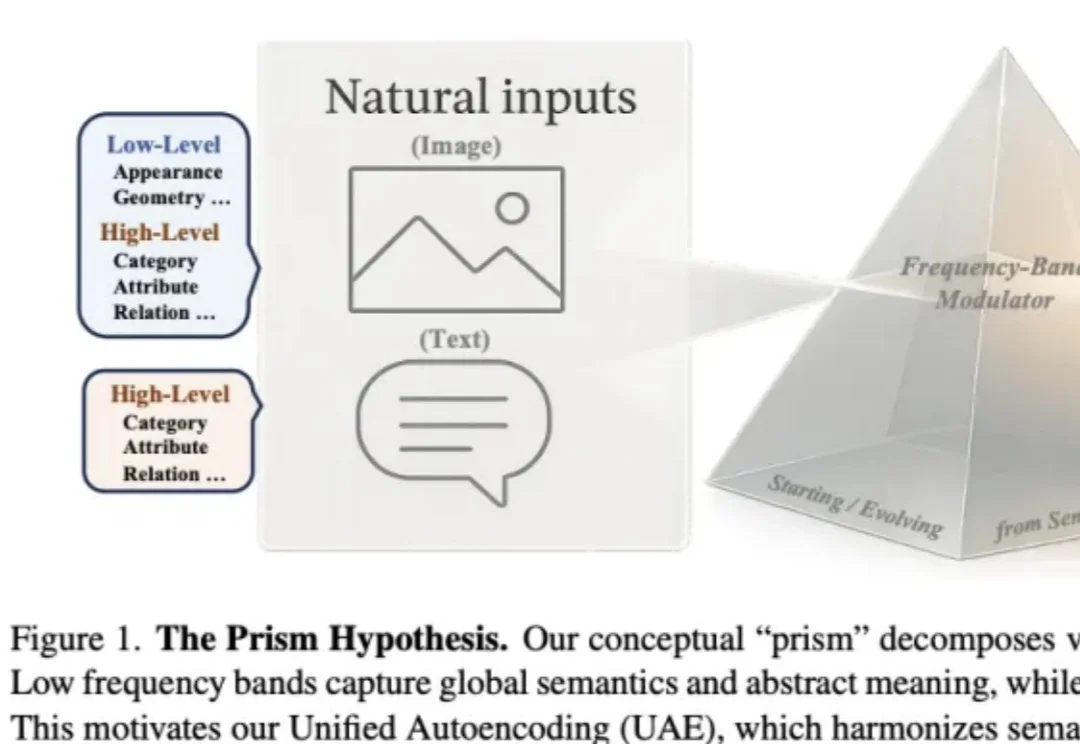
作者来自 Nanyang Technological University(MMLab) 与 SenseTime Research,提出 Prism Hypothesis(棱镜假说) 与 Unified Autoencoding(UAE),尝试用 “频率谱” 的统一视角,把语义编码器与像素编码器的表示冲突真正 “合并解决”。
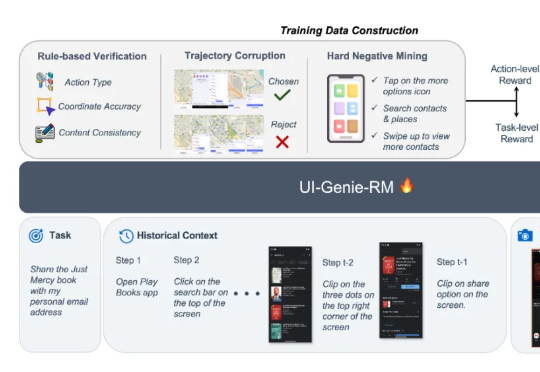
本文来自于香港中文大学 MMLab 和 vivo AI Lab,其中论文第一作者肖涵,主要研究方向为多模态大模型和智能体学习,合作作者王国志,研究方向为多模态大模型和 Agent 强化学习。项目 le
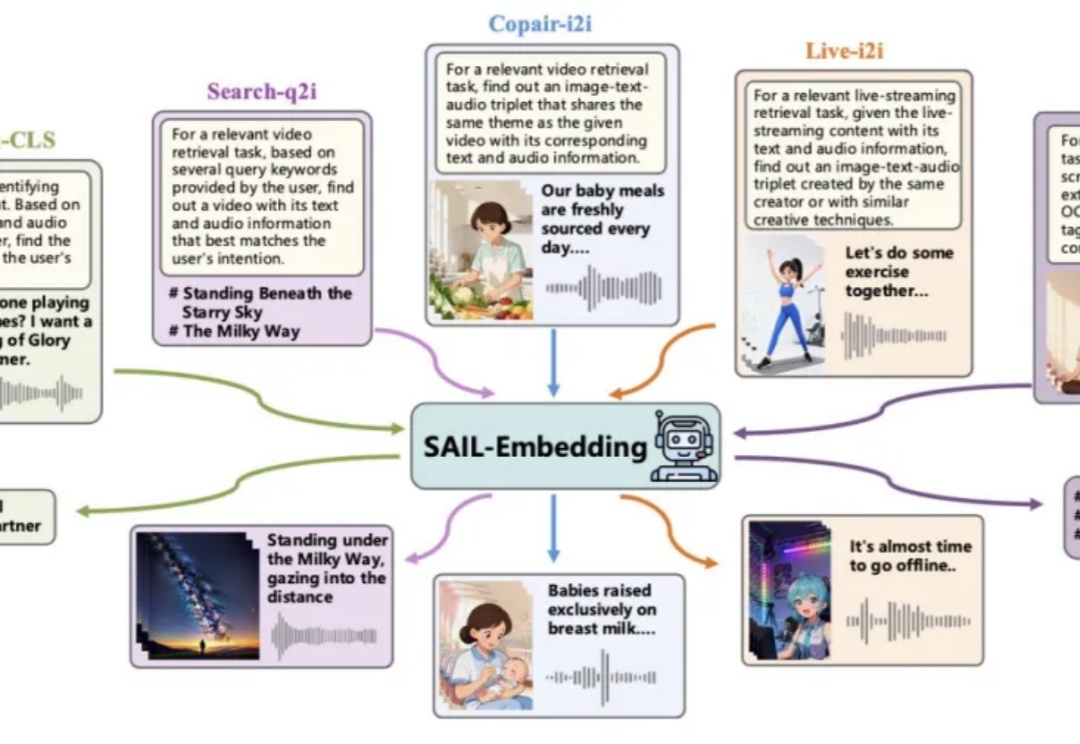
在短视频推荐、跨模态搜索等工业场景中,传统多模态模型常受限于模态支持单一、训练不稳定、领域适配性差等问题。
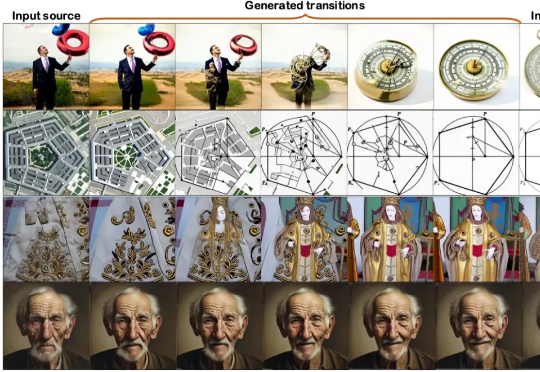
本文第一作者操雨康,南洋理工大学MMLab博士后,研究方向是3D/4D重建与生成,人体动作/视频生成,以及图像生成与编辑。
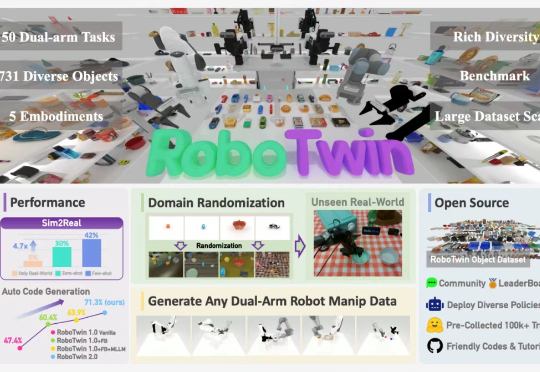
最近,上海交通大学 ScaleLab 与香港大学 MMLab@HKU 领衔发布 RoboTwin 系列新作 RoboTwin 2.0 以及基于 RoboTwin 仿真平台在 CVPR 上举办的双臂协作竞赛 Technical Report。

思维链(Chain of Thought, CoT)推理方法已被证明能够显著提升大语言模型(LLMs)在复杂任务中的表现。而在多模态大语言模型(MLLMs)中,CoT 同样展现出了巨大潜力。