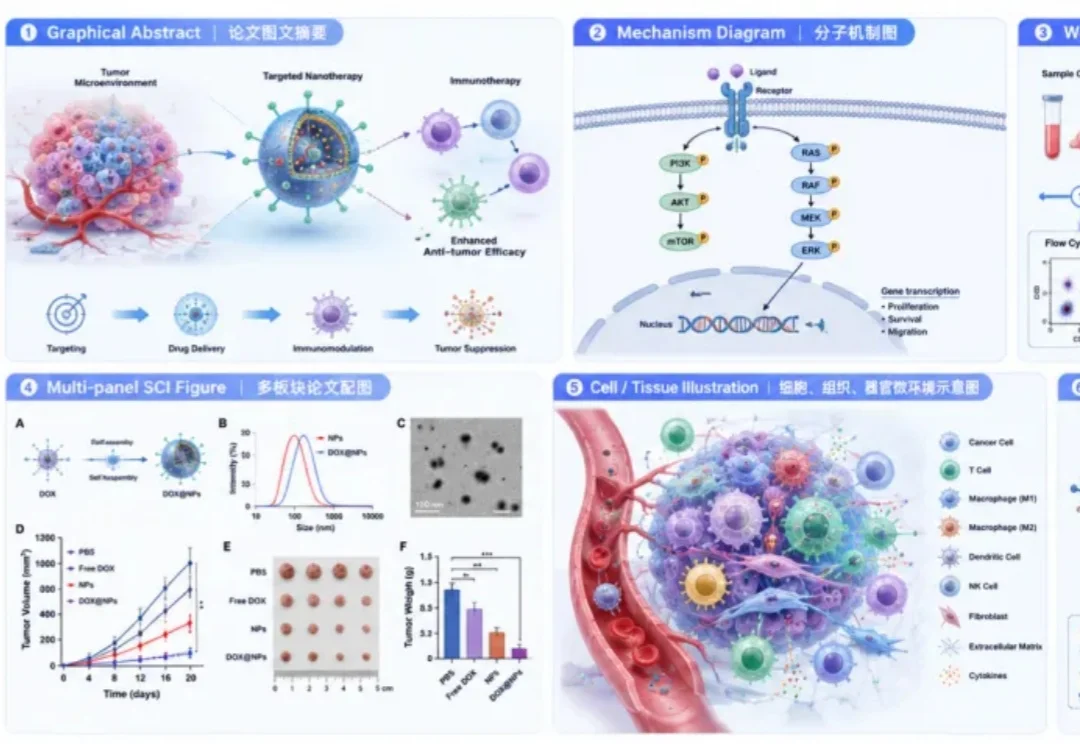
SCI 论文配图 Prompt 怎么写?这篇直接抄
SCI 论文配图 Prompt 怎么写?这篇直接抄做科研的人应该都懂,论文配图真的很耗时间。
来自主题: AI技术研报
5426 点击 2026-06-23 15:03
 搜索
搜索
做科研的人应该都懂,论文配图真的很耗时间。

今天给大家分享一个我最近经常刷的灵感外挂。

什么?这届世界杯,能一边看球一边跟范指导唠嗑了?!
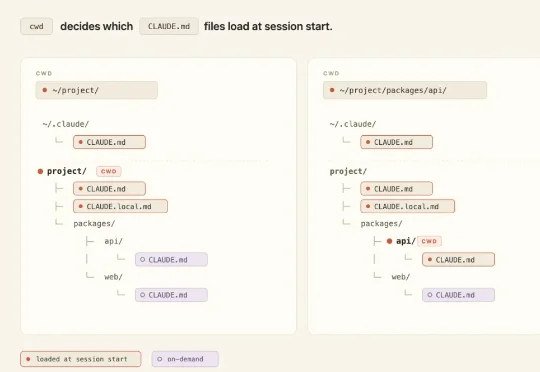
在常规的对话外,Claude Code(也可以是 Codex)其实还提供了一些别样的控制(或者说:上下文注入)方法,比如:CLAUDE.md、Rules、Skills、Subagents、Hooks、Output Styles、以及 System Prompt Append
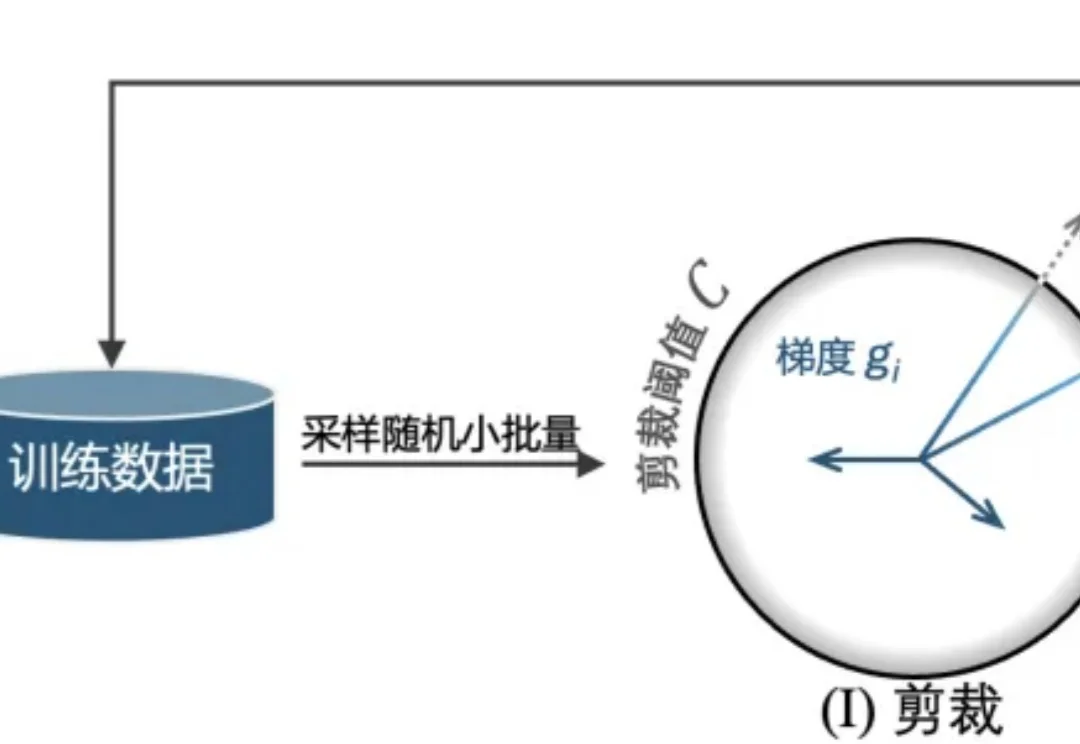
近日,来自英国南安普顿大学(University of Southampton)和广州大学的研究者团队提出 SlaClip,一种用于差分隐私随机梯度下降(DP-SGD)[1] 的自适应梯度剪裁方法。

一开始,忽悠 AI 挺简单。

2026 年,会不会用 AI 不再看 Prompt(提示词)能力了,而是要看会不会设计循环。
AI 正在学着操作电脑。由清华大学计算机系博士团队创立的非十科技,最近发布了一款桌面 Agent 产品 ———Agivar。与多数产品试图优化 Prompt 不同,它选择从另一个方向切入:让 AI 主动学习用户的工作流程。
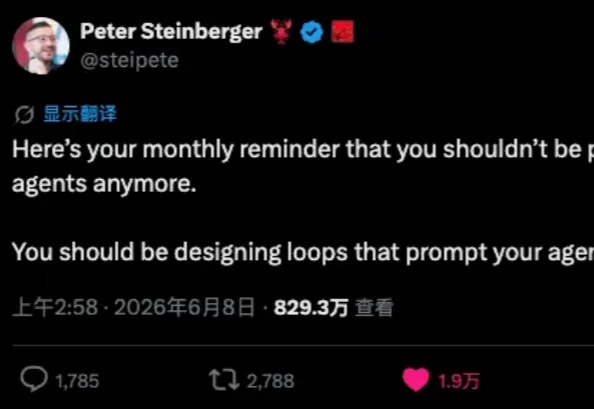
最近,AI行业又出现了一个有趣的新词。

Workflow、Skill、SOP,可能真的要过时了。