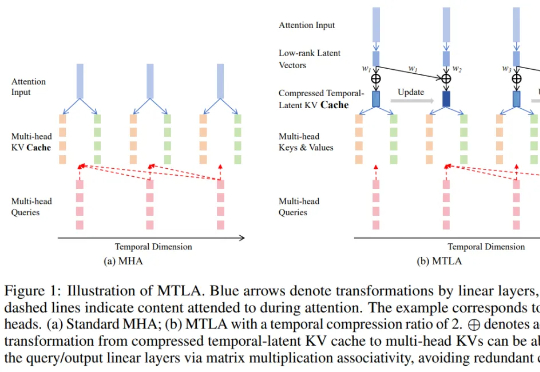
时空压缩!剑桥大学提出注意力机制MTLA:推理加速5倍,显存减至1/8
时空压缩!剑桥大学提出注意力机制MTLA:推理加速5倍,显存减至1/8在大语言模型蓬勃发展的背景下,Transformer 架构依然是不可替代的核心组件。尽管其自注意力机制存在计算复杂度为二次方的问题,成为众多研究试图突破的重点
来自主题: AI技术研报
9342 点击 2025-06-11 11:43
 搜索
搜索
在大语言模型蓬勃发展的背景下,Transformer 架构依然是不可替代的核心组件。尽管其自注意力机制存在计算复杂度为二次方的问题,成为众多研究试图突破的重点