
RNN效率媲美Transformer,谷歌新架构两连发:同等规模强于Mamba
RNN效率媲美Transformer,谷歌新架构两连发:同等规模强于Mamba去年 12 月,新架构 Mamba 引爆了 AI 圈,向屹立不倒的 Transformer 发起了挑战。如今,谷歌 DeepMind「Hawk 」和「Griffin 」的推出为 AI 圈提供了新的选择。
来自主题: AI技术研报
7062 点击 2024-03-03 18:10
 搜索
搜索
去年 12 月,新架构 Mamba 引爆了 AI 圈,向屹立不倒的 Transformer 发起了挑战。如今,谷歌 DeepMind「Hawk 」和「Griffin 」的推出为 AI 圈提供了新的选择。
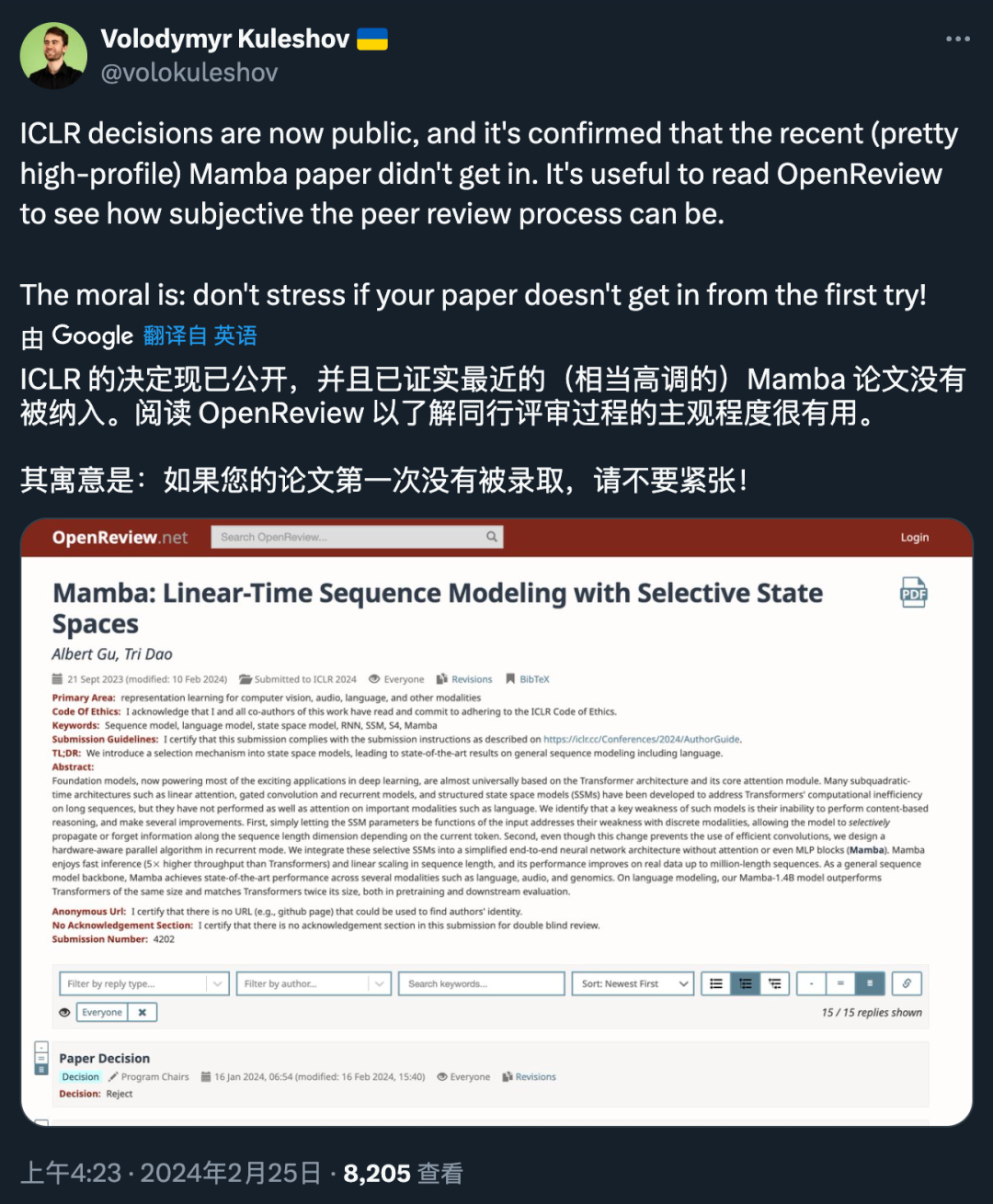
几天前,ICLR 2024 的最终接收结果出来了。

模型通过学习这些 token 的上下文关系以及如何组合它们来表示原始文本或预测下一个 token。
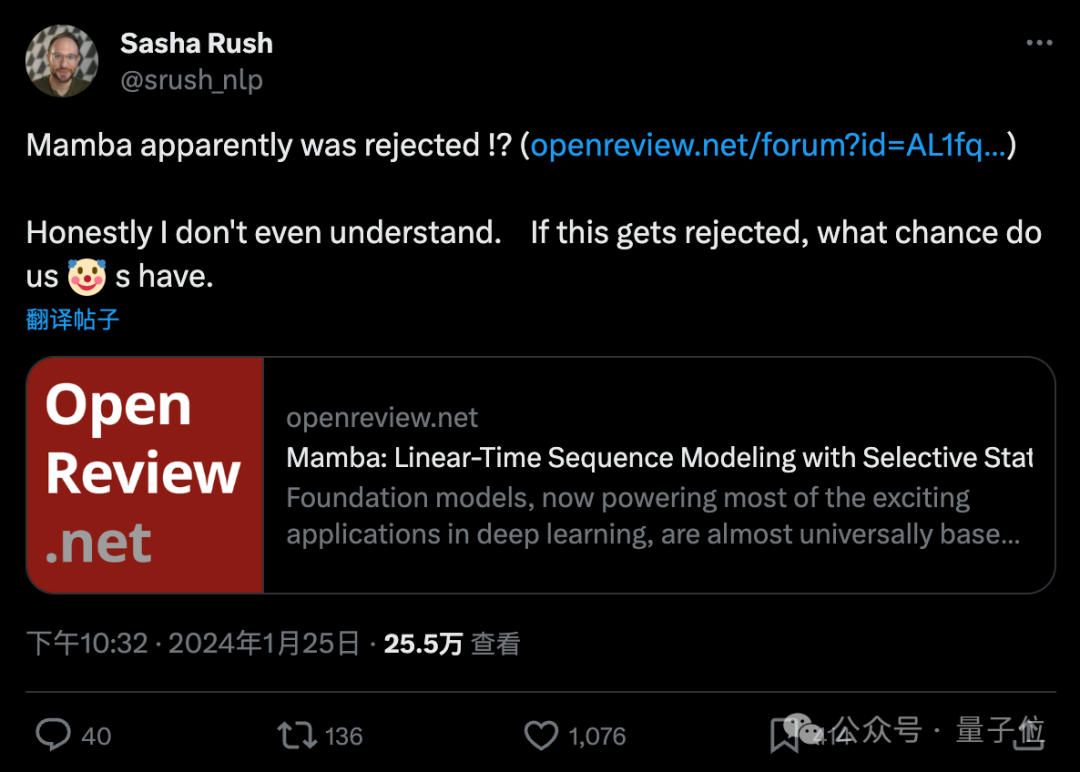
一项ICLR拒稿结果让AI研究者集体破防,纷纷刷起小丑符号。争议论文为Transformer架构挑战者Mamba,开创了大模型的一个新流派。发布两个月不到,后续研究MoE版本、多模态版本等都已跟上。
去年年底因颠覆Transformer一战成名的Mamba架构论文,竟然在ICLR 2024同行评审中被打出3分的低分,因而可能被拒收?这桩疑案今早一被曝出,立刻引发轩然大波,连LeCun都跳出来喊冤。

状态空间模型(SSM)是近来一种备受关注的 Transformer 替代技术,其优势是能在长上下文任务上实现线性时间的推理、并行化训练和强大的性能。而基于选择性 SSM 和硬件感知型设计的 Mamba 更是表现出色,成为了基于注意力的 Transformer 架构的一大有力替代架构。

Transformer 在大模型领域的地位可谓是难以撼动。不过,这个AI 大模型的主流架构在模型规模的扩展和需要处理的序列变长后,局限性也愈发凸显了。Mamba的出现,正在强力改变着这一切。它优秀的性能立刻引爆了AI圈。

替代注意力机制,SSM 真的大有可为?

现在ChatGPT等大模型一大痛点:处理长文本算力消耗巨大,背后原因是Transformer架构中注意力机制的二次复杂度。

屹立不倒的 Transformer 迎来了一个强劲竞争者。在别的领域,如果你想形容一个东西非常重要,你可能将其形容为「撑起了某领域的半壁江山」。但在 AI 大模型领域,Transformer 架构不能这么形容,因为它几乎撑起了「整个江山」。