挑战AI数学推理极限!大规模形式化数学基准FormalMATH发布,最强模型成功率仅16%
挑战AI数学推理极限!大规模形式化数学基准FormalMATH发布,最强模型成功率仅16%最强AI模型面对5560道数学难题,成功率仅16.46%?背后真相大揭秘。
来自主题: AI技术研报
10539 点击 2025-05-08 10:36
 搜索
搜索
最强AI模型面对5560道数学难题,成功率仅16.46%?背后真相大揭秘。
AIMO2冠军「答卷」公布了!英伟达团队NemoSkills拔得头筹,开源了OpenMath-Nemotron系列AI模型,1.5B小模型击败14B-DeepSeek「推理大模型」!
在大模型迈向推理时代的当下,数学推理能力已成为衡量语言模型智能上限的关键指标。
在数学推理中,大语言模型存在根本性局限:在美国数学奥赛,顶级AI模型得分不足5%!来自ETH Zurich等机构的MathArena团队,一下子推翻了AI会做数学题这个神话。
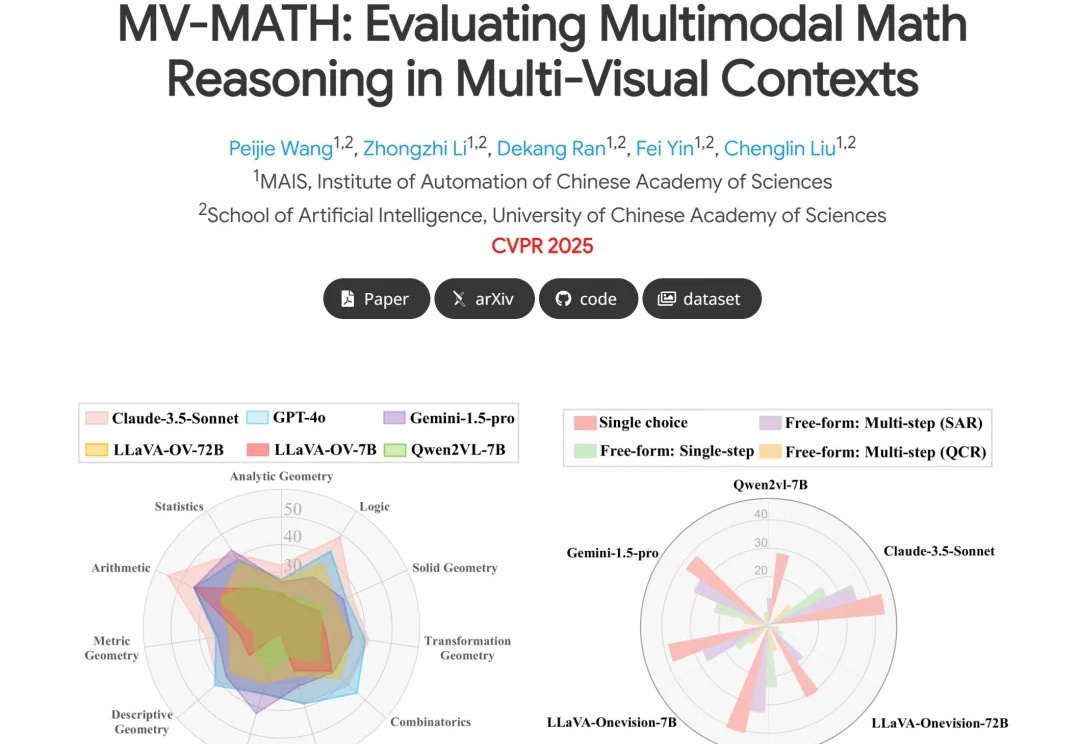
挑战多图数学推理新基准,大模型直接全军覆没?!
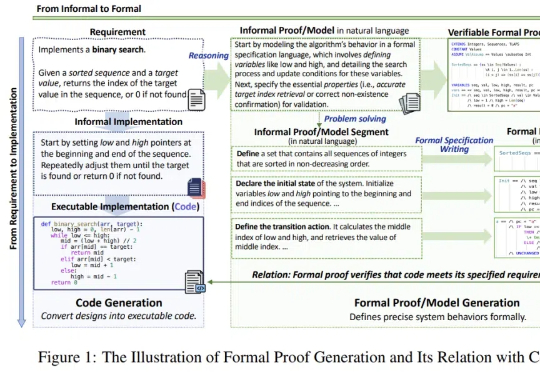
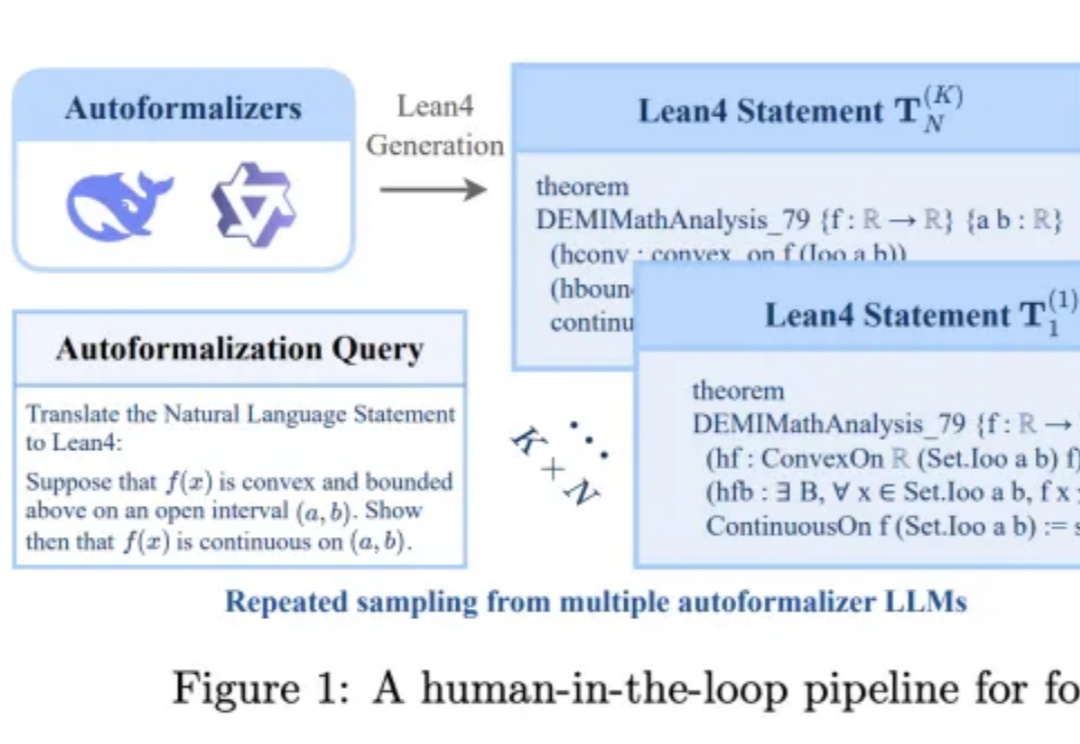
随着 DeepSeek-R1 的流行与 AI4Math 研究的深入,大模型在辅助形式化证明写作方面的需求日益增长。作为数学推理最直接的应用场景,形式化推理与验证(formal reasoning and verification),也获得持续关注。

Kimi未来还能够翻盘吗? 从公司发展路径上来看,并非没有可能。 作为曾经对OpenAI技术跟随最快的公司,Kimi在去年做出了Kimi探索版、k0-math等多个跟随OpenAI技术的模型,而杨植麟本人也在采访中,表示大模型的未来不仅在于强化学习,还在于多模态能力。 这一点似乎也与OpenAI类似。

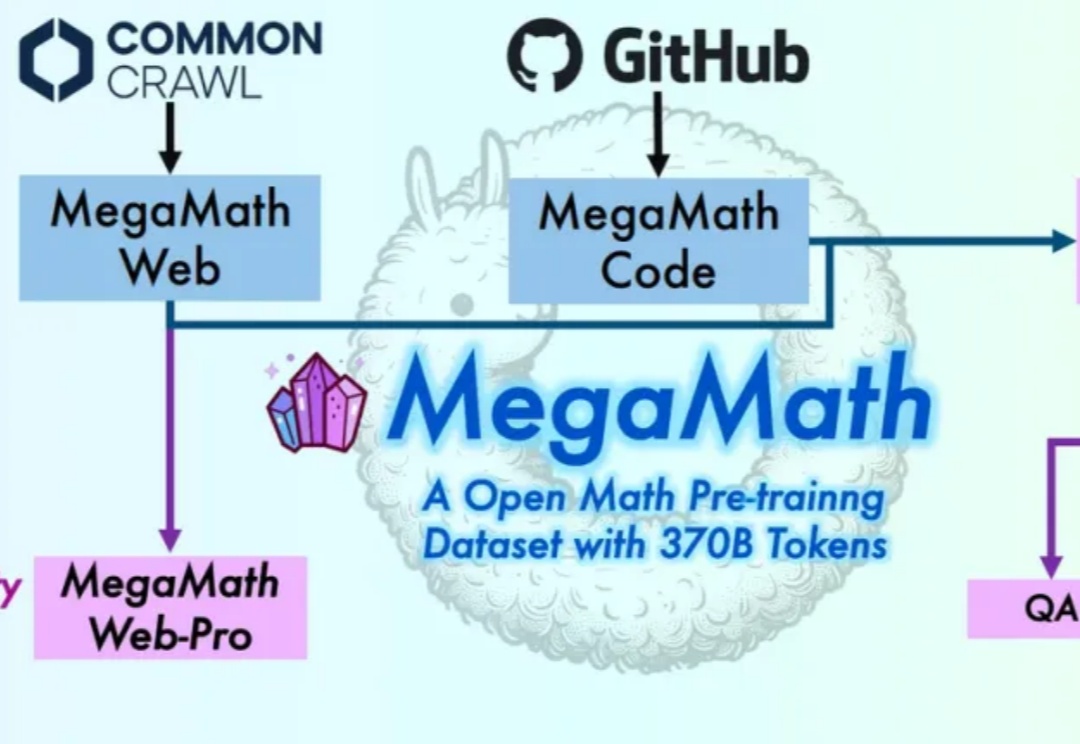
RedStone是一个高效构建大规模指定领域数据的处理管道,通过优化数据处理流程,从Common Crawl中提取了RedStone-Web、RedStone-Code、RedStone-Math和RedStone-QA等数据集,在多项任务中超越了现有开源数据集,显著提升了模型性能。

随着 Roblox 和 Minecraft 等游戏平台在年轻儿童中越来越受欢迎,以及 YouTube 等平台占据了他们每天大量的屏幕时间,教育科技公司在吸引他们的注意力方面面临挑战。

Sakana AI发布了Transformer²新方法,通过奇异值微调和权重自适应策略,提高了LLM的泛化和自适应能力。新方法在文本任务上优于LoRA;即便是从未见过的任务,比如MATH、HumanEval和ARC-Challenge等,性能也都取得了提升。